배열 (Array)
15 Jun 2020 | Data Structure
본 게시물은 문일철 교수님의 데이터 구조 및 분석을 참조하여 작성하였습니다.
배열 (Array)
배열(Array) 이란 기본적으로 동일한 자료형의 데이터를 인덱스를 활용하여 저장 및 접근할 수 있는 자료형입니다. 그렇기 때문에 배열의 각 요소에는 0부터 순차적으로 증가하는 인덱스가 할당되어 있습니다.
파이썬에서는 배열을 좀 더 일반화한 리스트(List)라는 자료형을 사용합니다. C, C++ 등의 언어는 배열에 들어가는 자료형의 종류와 배열의 크기를 미리 정해주어야 하지만 파이썬의 리스트는 이를 미리 지정하지 않고 리스트를 생성할 수 있습니다. 또한 리스트에서는 여러 자료형이 하나의 리스트에 들어가도록 할 수 있습니다.
x = ['a', 'b', 'd', 'e', 'f']
배열에서의 탐색(Search)
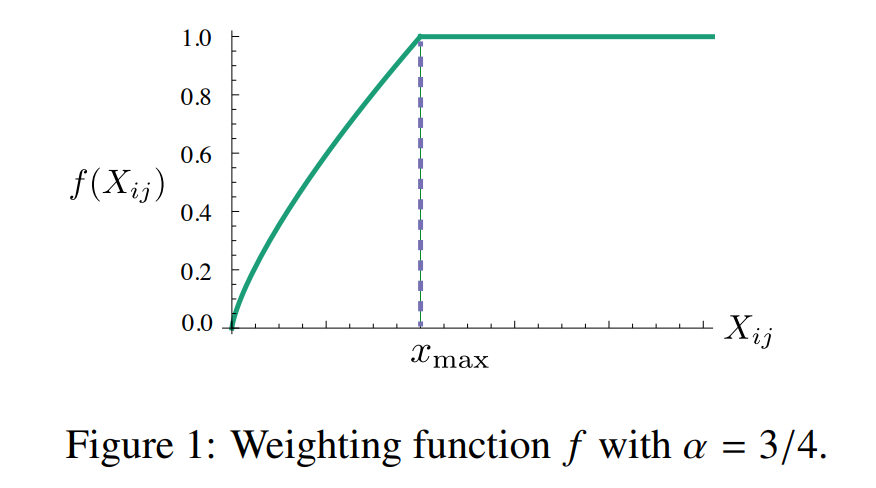
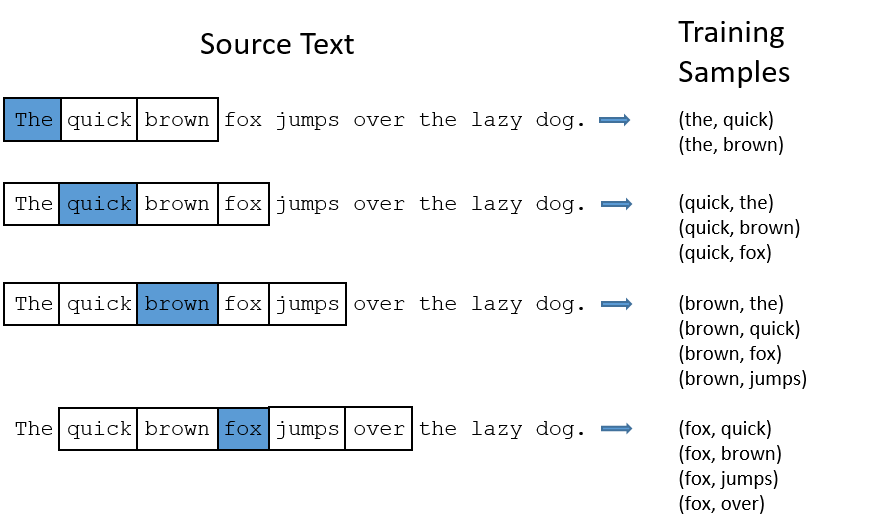
배열 안에 특정 요소가 있는 지를 탐색하는 알고리즘을 설계해 봅시다. 정렬된 배열의 경우 다른 알고리즘을 적용할 수도 있지만, 일반적인 경우는 0번째 인덱스부터 순차적으로 접근하여 그 값이 찾고자 하는 값인지 아닌 지를 비교합니다. 이를 선형 탐색(Linear search) 알고리즘이라고 합니다. 아래는 배열에서 선형 탐색 알고리즘이 이루어지는 과정을 도식화하여 나타낸 것입니다.

위에서 등장한 배열 x 에서 선형 탐색 알고리즘을 통해 'c' 와 'd' 를 찾는 과정을 생각해봅시다. 먼저 'c' 를 찾는 과정입니다. 우리는 'c' 가 없다는 것을 한눈에 알 수 있지만 컴퓨터는 한 번에 하나의 요소밖에 보지 못하므로 순차적으로 매 인덱스에 위치한 요소값을 확인하여 비교하여야 합니다. 알고리즘은 True 가 나올 때까지 진행되므로 배열 내에 없는 요소를 찾을 때는 모든 요소를 비교해야 합니다. 그렇기 때문에 배열의 길이인 $N$ 번의 Operation을 수행합니다. 이번에는 배열 안에 있는 'd' 를 찾는 과정입니다. 'c' 를 찾을 때와 같은 작업을 계속 반복하다가 해당 요소를 발견하면 종료합니다. 그렇기 때문에 찾고자 하는 값이 첫 번째로 있는 인덱스 (최대 $N$ 번)의 Operation을 수행하게 됩니다.
배열에서의 삽입(Insert)
이번에는 삽입 알고리즘 과정에 대해 생각해봅시다. 만약 위 배열 'b' 와 'd' 사이에 'c' 를 삽입하는 작업은 어떻게 할 수 있을까요? 배열에 특정 요소를 삽입할 때 원천적으로 발생하는 문제가 하나 있습니다. 위에서 배열은 크기가 정해져 있다고 했는데 어떻게 이미 만들어진 배열 안에 하나의 요소를 더 넣을 수 있을까요? 정담은 없습니다. 운전자 1명과 손님 4명이 타고 있는 택시에 손님을 태울 수 없는 것과 마찬가지입니다. 5명이 하나의 택시를 타려면 소형차가 아닌 중형보다 큰 새로운 차를 필요로 하는 것처럼, 배열도 정해진 개수보다 많은 요소를 삽입하려면 새로운 배열이 필요합니다.
우리의 목표는 하나의 요소를 삽입하는 것이므로 가장 먼저 원래의 배열보다 하나 더 큰 빈 배열을 만듭니다. 두 번째로는 새로운 요소를 삽입할 인덱스 이전까지의 참조(Reference)를 원래의 배열 x 에서 새로운 배열 y 로 복사합니다. 새로 삽입할 요소의 인덱스가 되면 그 참조를 우리가 삽입하고자 하는 값, 즉 'c' 에 연결합니다. 다시 다음 인덱스부터는 원래 배열 x 의 참조를 새로 만드는 배열의 하나씩 증가한 인덱스 y 에 복사합니다. 마지막으로 x 의 참조를 y 의 참조로 변경하면 삽입 과정이 완료됩니다. 아래는 이 과정을 도식화하여 나타낸 것입니다.

이 과정을 파이썬 코드로 구현하면 아래와 같습니다.
x = ['a', 'b', 'd', 'e', 'f']
idxInsert = 2
valInsert = 'c'
y = list(range(6))
for itr in range(0, idxInsert):
y[itr] = x[itr]
y[idxInsert] = valInsert
for itr in range(idxInsert, len(x)):
y[itr+1] = x[itr]
x = y
삽입 알고리즘에서는 Operation이 몇 번이나 일어날까요? 단계를 나누어 생각해봅시다. 원래 배열의 크기를 N, 새로운 요소를 삽입할 인덱스 idxInsert 를 a 라고 합시다. 그렇다면 그 0 부터 a-1 까지 참조를 복사하는 데 $a$ 번의 Operation을 수행합니다. 인덱스 a 에서 원하는 요소와 참조를 연결하는 과정에서는 $1$ 번의 Operation을 수행합니다. 인덱스 a+1 부터 N 까지의 참조를 복사하는 데에는 $N - a$ 번의 Operation을 수행합니다. 세 과정에서 수행하는 Operation의 개수를 합하면 삽입 알고리즘에 필요한 총 Operation 횟수가 $N + 1 = a + 1 + (N - a)$ 임을 알 수 있습니다.
배열에서의 삭제(Delete)
배열에서 특정 요소를 삭제하는 과정은 삽입 과정과 유사합니다. 배열에서 'd' 를 삭제하는 작업에 대해 생각해봅시다. 배열에는 빈자리도 있을 수 없으므로 하나의 요소를 삭제하기 위해서는 먼저 인덱스가 하나 적은 배열을 만들어야 합니다. 이후에는 삭제하려는 인덱스 이전에 있는 참조를 새로운 배열에 그대로 복사합니다. 삭제하려는 인덱스 이전에 있는 참조는 건너뛰게 되며 해당 인덱스 이후부터는 다시 새로운 배열의 하나씩 감소시킨 인덱스에 참조를 복사합니다. 마지막으로 원래의 배열 x 의 참조를 새로운 배열의 참조로 변경하면 삭제 과정이 완료됩니다.

이 과정을 파이썬 코드로 구현하면 아래와 같이 됩니다.
x = ['a', 'b', 'c', 'd', 'e', 'f']
idxDelete = 3
y = list(range(5))
for itr in range(0, idxDelete):
y[itr] = x[itr]
for itr in range(idxDelete+1, len(x)):
y[itr-1] = x[itr]
x = y
삭제 알고리즘에서는 Operation이 몇 번이나 일어날까요? 삽입과 마찬가지로 단계를 나누어 생각해봅시다. 원래 배열의 크기를 N, 삭제할 요소의 인덱스 idxDelete 를 b 라고 합시다. 그렇다면 그 0 부터 b-1 까지 참조를 복사하는 데 $b$ 번의 Operation을 수행합니다. 인덱스 b 에서는 아무런 Operation없이 건너뛰므로 고려하지 않으면 됩니다. 인덱스 b+1 부터 N 까지의 참조를 복사하는 데에는 $N - b$ 번의 Operation을 수행합니다. 세 과정에서 수행하는 Operation의 개수를 합하면 삭제 알고리즘에서는 총 $N + 1= b + 1 + (N - b)$ 회의 Operation이 필요함을 알 수 있습니다.
배열의 문제점
지금까지 알아본 것처럼 배열 속 요소를 탐색하는 과정 뿐만 아니라 새로운 요소를 삽입, 기존 요소를 삭제하는 작업을 위해서는 최대 $N$ 번의 Operation이 필요합니다. 배열 내에 수 개의 요소만 있을 경우에는 큰 상관이 없지만 배열의 크기 $N$ 이 $1,000,000$ 이상으로 매우 커지게 되면 삽입이나 삭제 과정에 그만큼의 Operation이 필요하므로 꽤 오랜 시간을 소모하게 될 것입니다. 선형 구조로 되어있는 배열은 삽입과 삭제에 불리합니다. 선형 구조에서는 크기가 $N$ 인 배열에 삽입 혹은 삭제를 수행하여 크기를 $N+1, N-1$ 로 만들 경우 모든 배열의 자리(인덱스)를 지정해 주어야 하기 때문입니다.
이런 문제를 개선하기 위해서는 선형 구조를 벗어나 새로운 자료구조의 세계로 들어가야 합니다. 이 자료구조에서는 삽입과 삭제를 오직 한 번의 Operation 만으로 수행할 수 있습니다. 그 자료구조가 바로 다음에 나올 연결 리스트(Linked List) 입니다.
본 게시물은 문일철 교수님의 데이터 구조 및 분석을 참조하여 작성하였습니다.
배열 (Array)
배열(Array) 이란 기본적으로 동일한 자료형의 데이터를 인덱스를 활용하여 저장 및 접근할 수 있는 자료형입니다. 그렇기 때문에 배열의 각 요소에는 0부터 순차적으로 증가하는 인덱스가 할당되어 있습니다.
파이썬에서는 배열을 좀 더 일반화한 리스트(List)라는 자료형을 사용합니다. C, C++ 등의 언어는 배열에 들어가는 자료형의 종류와 배열의 크기를 미리 정해주어야 하지만 파이썬의 리스트는 이를 미리 지정하지 않고 리스트를 생성할 수 있습니다. 또한 리스트에서는 여러 자료형이 하나의 리스트에 들어가도록 할 수 있습니다.
x = ['a', 'b', 'd', 'e', 'f']
배열에서의 탐색(Search)
배열 안에 특정 요소가 있는 지를 탐색하는 알고리즘을 설계해 봅시다. 정렬된 배열의 경우 다른 알고리즘을 적용할 수도 있지만, 일반적인 경우는 0번째 인덱스부터 순차적으로 접근하여 그 값이 찾고자 하는 값인지 아닌 지를 비교합니다. 이를 선형 탐색(Linear search) 알고리즘이라고 합니다. 아래는 배열에서 선형 탐색 알고리즘이 이루어지는 과정을 도식화하여 나타낸 것입니다.
위에서 등장한 배열 x 에서 선형 탐색 알고리즘을 통해 'c' 와 'd' 를 찾는 과정을 생각해봅시다. 먼저 'c' 를 찾는 과정입니다. 우리는 'c' 가 없다는 것을 한눈에 알 수 있지만 컴퓨터는 한 번에 하나의 요소밖에 보지 못하므로 순차적으로 매 인덱스에 위치한 요소값을 확인하여 비교하여야 합니다. 알고리즘은 True 가 나올 때까지 진행되므로 배열 내에 없는 요소를 찾을 때는 모든 요소를 비교해야 합니다. 그렇기 때문에 배열의 길이인 $N$ 번의 Operation을 수행합니다. 이번에는 배열 안에 있는 'd' 를 찾는 과정입니다. 'c' 를 찾을 때와 같은 작업을 계속 반복하다가 해당 요소를 발견하면 종료합니다. 그렇기 때문에 찾고자 하는 값이 첫 번째로 있는 인덱스 (최대 $N$ 번)의 Operation을 수행하게 됩니다.
배열에서의 삽입(Insert)
이번에는 삽입 알고리즘 과정에 대해 생각해봅시다. 만약 위 배열 'b' 와 'd' 사이에 'c' 를 삽입하는 작업은 어떻게 할 수 있을까요? 배열에 특정 요소를 삽입할 때 원천적으로 발생하는 문제가 하나 있습니다. 위에서 배열은 크기가 정해져 있다고 했는데 어떻게 이미 만들어진 배열 안에 하나의 요소를 더 넣을 수 있을까요? 정담은 없습니다. 운전자 1명과 손님 4명이 타고 있는 택시에 손님을 태울 수 없는 것과 마찬가지입니다. 5명이 하나의 택시를 타려면 소형차가 아닌 중형보다 큰 새로운 차를 필요로 하는 것처럼, 배열도 정해진 개수보다 많은 요소를 삽입하려면 새로운 배열이 필요합니다.
우리의 목표는 하나의 요소를 삽입하는 것이므로 가장 먼저 원래의 배열보다 하나 더 큰 빈 배열을 만듭니다. 두 번째로는 새로운 요소를 삽입할 인덱스 이전까지의 참조(Reference)를 원래의 배열 x 에서 새로운 배열 y 로 복사합니다. 새로 삽입할 요소의 인덱스가 되면 그 참조를 우리가 삽입하고자 하는 값, 즉 'c' 에 연결합니다. 다시 다음 인덱스부터는 원래 배열 x 의 참조를 새로 만드는 배열의 하나씩 증가한 인덱스 y 에 복사합니다. 마지막으로 x 의 참조를 y 의 참조로 변경하면 삽입 과정이 완료됩니다. 아래는 이 과정을 도식화하여 나타낸 것입니다.
이 과정을 파이썬 코드로 구현하면 아래와 같습니다.
x = ['a', 'b', 'd', 'e', 'f']
idxInsert = 2
valInsert = 'c'
y = list(range(6))
for itr in range(0, idxInsert):
y[itr] = x[itr]
y[idxInsert] = valInsert
for itr in range(idxInsert, len(x)):
y[itr+1] = x[itr]
x = y
삽입 알고리즘에서는 Operation이 몇 번이나 일어날까요? 단계를 나누어 생각해봅시다. 원래 배열의 크기를 N, 새로운 요소를 삽입할 인덱스 idxInsert 를 a 라고 합시다. 그렇다면 그 0 부터 a-1 까지 참조를 복사하는 데 $a$ 번의 Operation을 수행합니다. 인덱스 a 에서 원하는 요소와 참조를 연결하는 과정에서는 $1$ 번의 Operation을 수행합니다. 인덱스 a+1 부터 N 까지의 참조를 복사하는 데에는 $N - a$ 번의 Operation을 수행합니다. 세 과정에서 수행하는 Operation의 개수를 합하면 삽입 알고리즘에 필요한 총 Operation 횟수가 $N + 1 = a + 1 + (N - a)$ 임을 알 수 있습니다.
배열에서의 삭제(Delete)
배열에서 특정 요소를 삭제하는 과정은 삽입 과정과 유사합니다. 배열에서 'd' 를 삭제하는 작업에 대해 생각해봅시다. 배열에는 빈자리도 있을 수 없으므로 하나의 요소를 삭제하기 위해서는 먼저 인덱스가 하나 적은 배열을 만들어야 합니다. 이후에는 삭제하려는 인덱스 이전에 있는 참조를 새로운 배열에 그대로 복사합니다. 삭제하려는 인덱스 이전에 있는 참조는 건너뛰게 되며 해당 인덱스 이후부터는 다시 새로운 배열의 하나씩 감소시킨 인덱스에 참조를 복사합니다. 마지막으로 원래의 배열 x 의 참조를 새로운 배열의 참조로 변경하면 삭제 과정이 완료됩니다.
이 과정을 파이썬 코드로 구현하면 아래와 같이 됩니다.
x = ['a', 'b', 'c', 'd', 'e', 'f']
idxDelete = 3
y = list(range(5))
for itr in range(0, idxDelete):
y[itr] = x[itr]
for itr in range(idxDelete+1, len(x)):
y[itr-1] = x[itr]
x = y
삭제 알고리즘에서는 Operation이 몇 번이나 일어날까요? 삽입과 마찬가지로 단계를 나누어 생각해봅시다. 원래 배열의 크기를 N, 삭제할 요소의 인덱스 idxDelete 를 b 라고 합시다. 그렇다면 그 0 부터 b-1 까지 참조를 복사하는 데 $b$ 번의 Operation을 수행합니다. 인덱스 b 에서는 아무런 Operation없이 건너뛰므로 고려하지 않으면 됩니다. 인덱스 b+1 부터 N 까지의 참조를 복사하는 데에는 $N - b$ 번의 Operation을 수행합니다. 세 과정에서 수행하는 Operation의 개수를 합하면 삭제 알고리즘에서는 총 $N + 1= b + 1 + (N - b)$ 회의 Operation이 필요함을 알 수 있습니다.
배열의 문제점
지금까지 알아본 것처럼 배열 속 요소를 탐색하는 과정 뿐만 아니라 새로운 요소를 삽입, 기존 요소를 삭제하는 작업을 위해서는 최대 $N$ 번의 Operation이 필요합니다. 배열 내에 수 개의 요소만 있을 경우에는 큰 상관이 없지만 배열의 크기 $N$ 이 $1,000,000$ 이상으로 매우 커지게 되면 삽입이나 삭제 과정에 그만큼의 Operation이 필요하므로 꽤 오랜 시간을 소모하게 될 것입니다. 선형 구조로 되어있는 배열은 삽입과 삭제에 불리합니다. 선형 구조에서는 크기가 $N$ 인 배열에 삽입 혹은 삭제를 수행하여 크기를 $N+1, N-1$ 로 만들 경우 모든 배열의 자리(인덱스)를 지정해 주어야 하기 때문입니다.
이런 문제를 개선하기 위해서는 선형 구조를 벗어나 새로운 자료구조의 세계로 들어가야 합니다. 이 자료구조에서는 삽입과 삭제를 오직 한 번의 Operation 만으로 수행할 수 있습니다. 그 자료구조가 바로 다음에 나올 연결 리스트(Linked List) 입니다.