
Word2Vec
28 May 2020 | NLP
본 포스트의 내용은 고려대학교 강필성 교수님의 강의 와 김기현의 자연어처리 딥러닝 캠프 , 밑바닥에서 시작하는 딥러닝 2 , 한국어 임베딩 책을 참고하였습니다.
Word2Vec
지난번 게시물에 있었던 확률기반 신경망 언어 모델(NPLM)은 처음으로 단어 임베딩을 언어 모델에 사용하였습니다. 이번에는 단어 임베딩에서 가장 많이 쓰이는 모델인 Word2Vec에 대해서 알아보겠습니다. Word2Vec에는 크게 CBoW(Continuous Bag-of-Words)와 Skip-gram의 2가지 방법이 있습니다.
CBoW & Skip-gram
NPLM에서도 가정했던 것처럼 Word2Vec의 두 방법 CBoW와 Skip-gram은 모두 “특정 단어 주변에 있는 단어는 유사한 관계를 맺고 있을 것이다”라는 전제를 하고 있습니다. 이런 전제에 따라
결정적인 차이는 학습의 기준이 되는 단어와 학습할 단어의 차이에 있습니다. 윤동주 시인의 시를 통해서 CBoW와 Skip-gram이 어떻게 학습을 해가는지를 알아보겠습니다. 아래는 Mecab 으로 추출한 별헤는 밤의 형태소 일부입니다.
“… 어머님 나 는 별 하나 에 아름다운 말 한마디 씩 불러 봅니다 …”
이 가사를 CBoW를 활용하면 아래의 빈칸에 들어갈 단어를 예상하는 과정으로 학습이 진행됩니다.
“… 나 는 [ __ ] 하나 에 … “
“… 는 별 [ ____ ] 에 아름다운 …”
“… 별 하나 [ __ ] 아름다운 말 …”
“… 하나 에 [ _________ ] 말 한마디 …”
Skip-gram을 진행하면 다음의 빈칸에 들어갈 단어를 예상하는 과정으로 학습이 진행되지요.
“… [ __ ] [ __ ]별 [ ____ ] [ __ ] …”
“… [ __ ] [ __ ]하나 [ __ ] [________ ] …”
“… [ __ ] [ ____ ] 에 [ _________ ] [ __ ] …”
“… [ ____ ] [ __ ] 아름다운 [ __ ] [ ______ ] …”
위 처럼 CBoW는 주변 단어(Context)를 보고 타겟 단어 $w_t$ 를 예측하게 되고, Skip-gram은 타겟 단어 $w_t$ 를 보고 주변 단어 $C$ 를 입력하게 됩니다. 얼핏 생각해보면 더 많은 정보를 받아서 단어를 예측하는 CBoW의 성능이 좋을 것으로 생각하기 쉽습니다. 실제로는 Skip-gram 방법이 역전파를 통해 더 많은 학습 정보를 받을 수 있습니다. 아래는 학습이 되는 과정을 도식화한 이미지입니다.

이미지 출처 : researchgate.net
위 그림을 역전파의 관점에서 생각해보면 CBoW는 타겟 단어 $w_t$의 학습 정보를 주변 단어 4개가 모두 나누어 받게 됩니다. 반대로 Skip-gram은 타겟 단어 $w_t$ 가 무려 주변 단어 4개의 학습 정보를 받게 됩니다. 실제로 Skip-gram이 성능이 더 좋지만 하나의 타겟 단어를 학습하는데 4단어에 대한 학습을 진행하므로 시간이 더 오래 걸리고 더 많은 컴퓨팅 자원을 필요로 한다는 단점이 있습니다.
Structure
실제로는 모델의 성능 덕분에 CBoW보다는 Skip-gram이 더 많이 사용됩니다. 그렇기 때문에 이번 게시물에서는 Skip-gram을 중심으로 어떻게 학습이 진행되는 지를 알아보겠습니다. 일단 Skip-gram 모델의 기본적인 구조는 아래와 같이 생겼습니다.
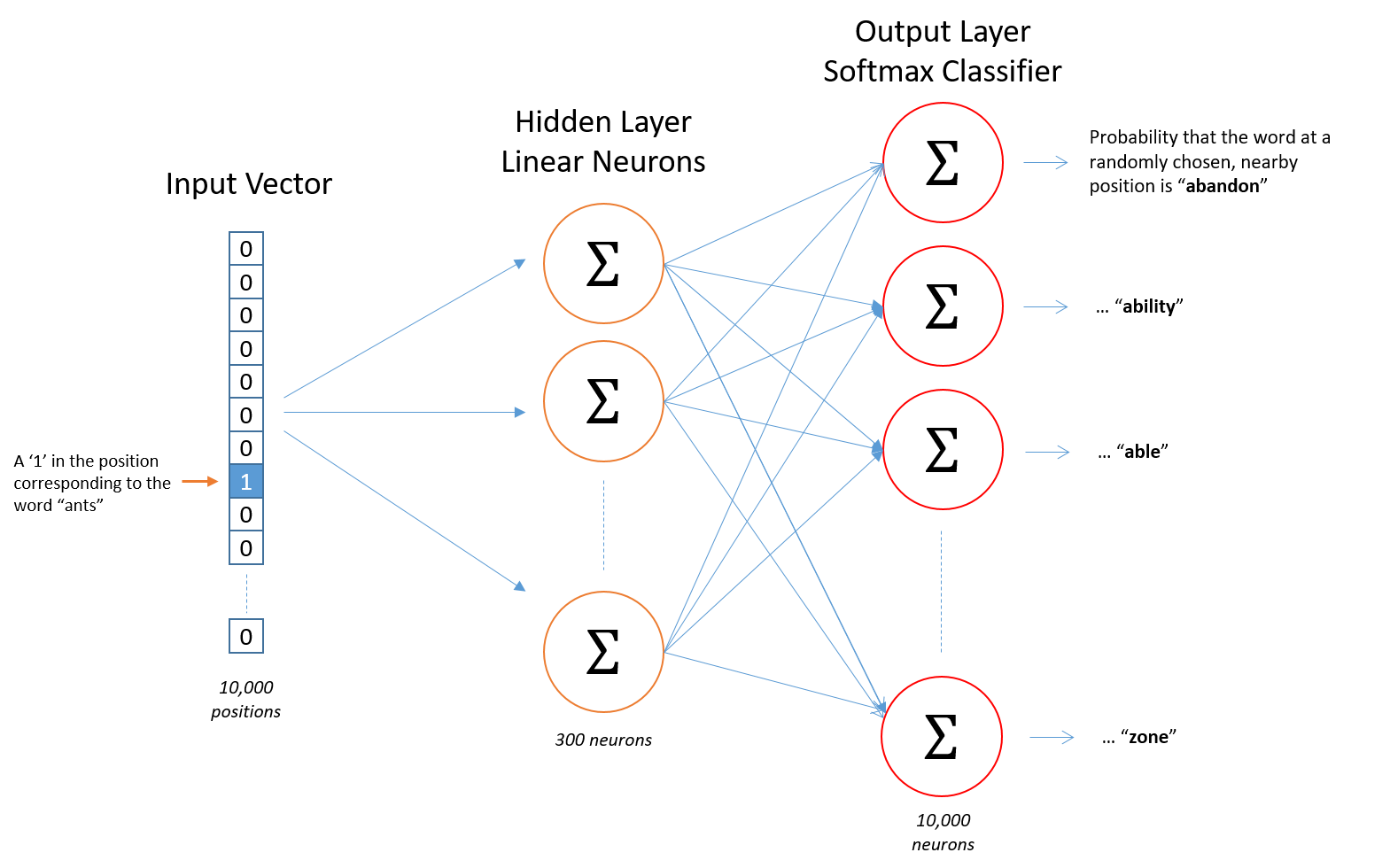
이미지 출처 : mccormickml.com
가장 왼쪽에 있는 입력 벡터는 원-핫 인코딩을 거친 벡터로 우리가 알고 있는 타겟 단어만 $1$ 로 표시됩니다. 총 10,000개의 단어가 있을 때 300차원으로 임베딩 하기 위해서는 아래와 같은 가중치 행렬(Weight matrix, 주황색)가 필요하게 되고 이를 참조(Lookup)하여 단어 임베딩 벡터로 이루어진 행렬(파란색)을 만들게 됩니다.
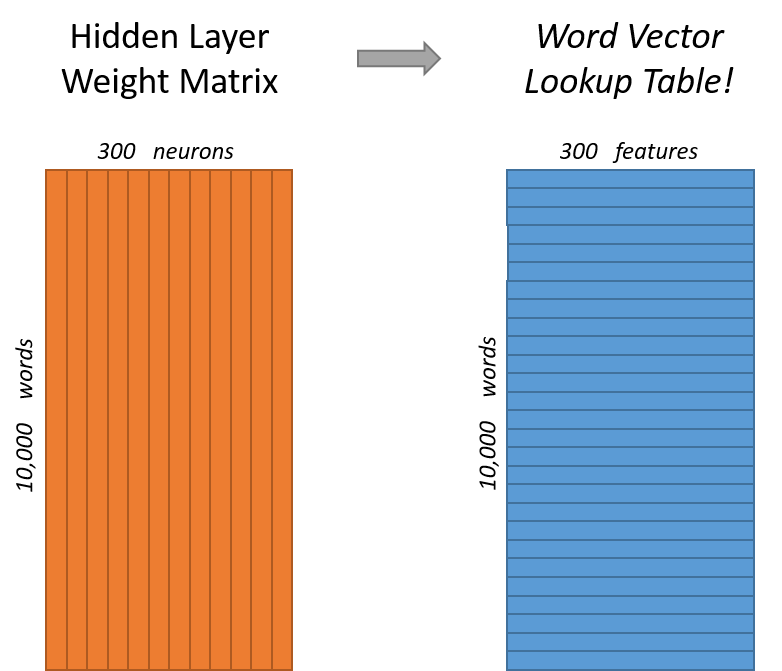
이미지 출처 : mccormickml.com
임베딩을 마친 단어 임베딩 벡터는 출력층에서 소프트맥스 함수를 통해서 주변 단어를 각각 예측하게 됩니다.
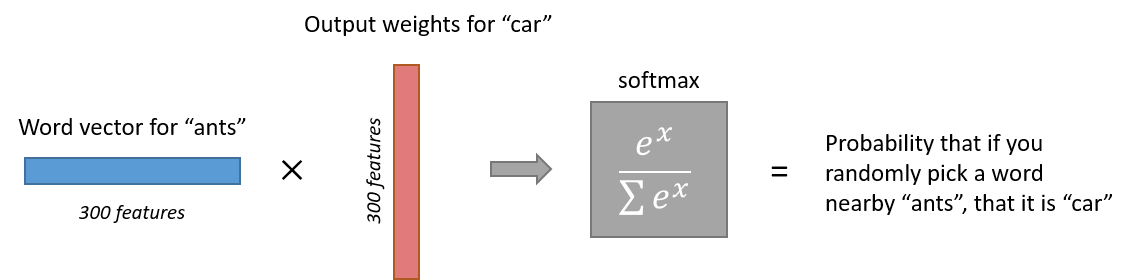
이미지 출처 : mccormickml.com
실제 학습과정에서는 4개의 단어를 한꺼번에 학습 하는 것이 아니라 (타겟단어, 주변단어)처럼 타겟 단어와 각 주변 단어의 쌍을 만들어 각각을 학습합니다. 아래 이미지는 모델에서 이런 방식으로 학습 샘플을 만드는 것을 잘 나타내는 그림입니다.
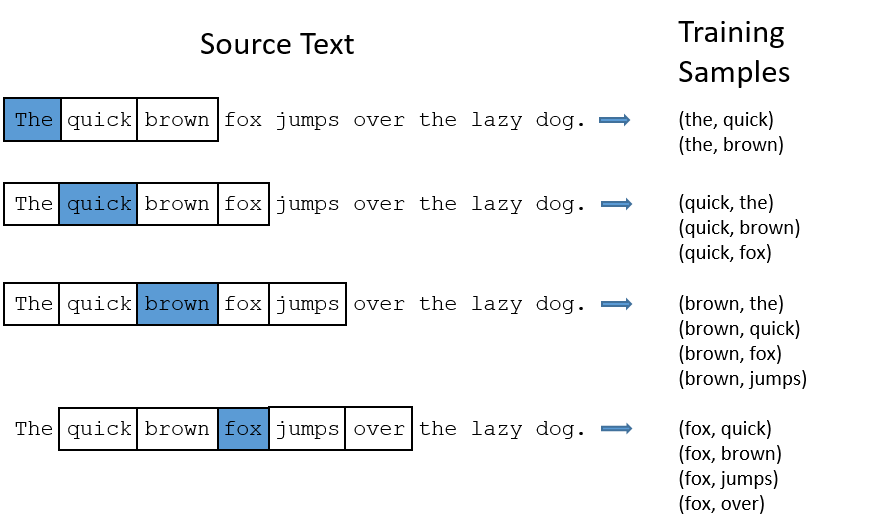
이미지 출처 : mccormickml.com
Skip-gram with Gradient Ascent
Skip-gram의 목적 함수 $J(\theta)$를 다음과 같이 나타낼 수 있습니다. $\theta$ 는 파라미터 행렬이며 $t$ 는 각 타겟 단어인 $w_t$ 를 가리킵니다.
\[J(\theta) = \frac{1}{T} \sum^T_{t=1} \sum_{-m \leq j \leq m, j \neq 0} \log p(w_{t+j}|w_t) = \frac{1}{T} \sum^T_{t=1} J_t (\theta)\]
그럼 이 목적함수를 바탕으로 Skip-gram에서 경사 상승법을 통해 학습이 진행되는 과정을 살펴보겠습니다. 수식의 단순화를 위하여 $w_{t+j} \rightarrow o, w_t \rightarrow c$(outside, center)로 나타내면 주변 단어의 확률을 아래와 같이 나타낼 수 있습니다.
\[p(o|c) = \frac{\exp(u_o^Tv_c)}{\sum^W_{w=1} \exp(u_w^Tv_c)}\]
위 확률을 최대화하는 것이 목적입니다. 타겟 단어마다의 목적 함수 $J_t(\theta)$ 와 $\text{argmax}$ 를 사용하면 식을 아래와 같이 나타낼 수 있습니다.
\[\hat{v_c} = \text{argmax}_{v_c} J_t(\theta) = \text{argmax}_{v_c} \log p(w_o|w_t)\]
확률을 최대화 하는 $v_c$를 찾는 것아야 하기 때문에 $v_c$로 편미분한 식을 $0$ 으로 만드는 $v_c$를 찾아야합니다. 수식으로 알아보도록 하겠습니다.
\[\begin{aligned}
\frac{\partial}{\partial v_c} \log p(o|c) &= \frac{\partial}{\partial v_c} \log \frac{\exp(u_o^Tv_c)}{\sum^W_{w=1} \exp(u_w^Tv_c)}\\
&= \frac{\partial}{\partial v_c} u_o^Tv_c-\frac{\partial}{\partial v_c} \log \sum^W_{w=1} \exp(u^T_w v_c) \\
&= u_o - \frac{1}{\sum^W_{w=1} \exp(u^T_w v_c)} \cdot \sum^W_{w=1} \exp(u^T_w v_c) \cdot u_w \\
&= u_o - \sum^W_{w=1}\frac{\exp(u^T_w v_c)}{\sum^W_{w=1} \exp(u^T_w v_c)} \cdot u_w \\
&= u_o - \sum^W_{w=1} P(w|c) \cdot u_w
\end{aligned}\]
확률을 최대화 하는 것이 목적이므로 경사 상승법(Gradient Ascent)을 적용하여 가중치 벡터 $v_c$ 를 개선해나가게 됩니다.
\[v_c(t+1) = v_c(t) + \alpha \bigg(u_o - \sum^W_{w=1} P(w|c) \cdot u_w\bigg)\]
Skip-gram with Sampling
Skip-gram의 단점은 계산량이 많아 시간이 오래 걸린다는 점입니다. 아무런 처리가 없을 때, $V$개의 단어를 가진 말뭉치를 $N$차원의 임베딩 벡터로 학습하려면 $2\times V\times N$ 만큼의 가중치를 학습해야 합니다. 위 그림처럼 “brown”이 타깃 단어이고 주변 단어에 “fox”가 있을 때 (brown, fox)로 학습하고, “fox”가 타깃 단어이고 주변 단어에 “brown”이 있을 때에는 (fox, brown)을 학습하기 때문입니다. 이를 위해 고안된 샘플링(Sampling) 기법은 중요도가 떨어지는 단어의 개수를 줄임으로써 임베딩 벡터의 성능을 떨어뜨리지 않으면서도 계산량을 줄일 수 있도록 하는 방법입니다.
Sub-sampling
서브샘플링(Sub-sampling)은 자주 등장하는 단어를 학습 대상에서 제외하는 방법입니다. 아래 식에서 $P(w_i)$는 단어 빈도 $f(w_i)$ 에 따라서 이 값이 높은 단어를 누락시키는 확률입니다. $t$ 는 임계값(threshold)입니다.
\[P(w_i) = 1 - \sqrt{\frac{t}{f(w_i)}}\]
예를 들어, 총 말뭉치에 등장하는 단어 중 10,000번에 1번 등장하는 단어 $w_1$이 학습에서 누락될 확률과 100번에 1번 등장하는 단어 $w_2$가 학습에서 누락될 확률을 비교해봅시다. 이 때 $t = 10^{-5}$ 로 설정하겠습니다.
\[\begin{aligned}
P(w_1) &= 1 - \sqrt{\frac{10^{-5}}{10^{-4}}} = 1 - \sqrt{\frac{1}{10}} = 0.6838 \qquad \because f(w_1) = \frac{1}{10000} = 10^{-4} \\
P(w_2) &= 1 - \sqrt{\frac{10^{-5}}{10^{-2}}} = 1 - \sqrt{\frac{1}{1000}} = 0.9684 \qquad \because f(w_2) = \frac{1}{100} = 10^{-2}
\end{aligned}\]
위 식을 보면 $w_1$ 은 말뭉치에 100번 등장할 때 약 68개의 단어가 누락되므로 32개의 단어만 학습에 사용됩니다. 하지만 $w_2$ 는 말뭉치에 1000번이나 등장하더라도 968개의 단어가 누락되므로 32개의 단어만 학습에 사용됩니다. 이렇게 서브샘플링을 하면 자주 나오는 단어들에 대한 확률을 급격히 낮춤으로써 계산량을 줄일 수 있습니다.
Negative Sampling
네거티브 샘플링을 설명하기 위해서 위에서 사용했던 Skip-gram의 구조 이미지를 다시 가져와 보겠습니다.
이미지 출처 : mccormickml.com
이 구조에 따르면 총 10,000단어에 대한 300개의 임베딩 벡터를 학습하기 위해서 소프트맥스 단계의 행렬의 요소는 $10,000 \times 300 = 3,000,000$개가 됩니다. 각각의 요소를 경사 상승법으로 반복해서 학습하기에는 너무 많은 양이지요. 네거티브 샘플링(Negative Sampling)은 수많은 파라미터 중 일부만을 학습하기 위해 고안된 전략입니다.
네거티브 샘플링 전략을 사용하지 않았을 때는 타겟 단어 $w_t$와 주변 단어 중 하나인 $w_o$에 대하여 학습 샘플이 $(w_t, w_o)$로 계산됩니다. 결국 하나의 계산마다 $w_o$를 구할 때 10,000개 단어 전부를 예측의 대상으로 하기 때문에, 소프트맥스의 계산량이 매우 많습니다. 네거티브 샘플링은 예측 대상을 포지티브 샘플(Positive sample) $1$개와 네거티브 샘플(Negative sample) $k$개로 구성함으로써 소프트맥스 계산을 줄일 수 있습니다.
위에서 포지티브 샘플은 $w_o$ 에 해당하는 단어이고, 네거티브 샘플은 $w_o$에 해당하지 않는 단어입니다. 위에서 했던 <별 헤는="" 밤="">을 예시로 다시 가져와 보겠습니다.
… 어머님 나 는 별 하나 에 아름다운 말 한마디 씩 불러 봅니다 소학교 때 책상 을 같이 했 던 아이 들 의 이름 과 패 경 옥 이런 이국 소녀 들 의 이름 과 벌써 애기 어머니 된 계집애 들 의 이름 과 가난 한 이웃 사람 들 의 이름 과 비둘기 강아지 토끼 노새 노루 프란시스 쟘 라이너 마리아 릴케 이런 시인 의 이름 을 불러 봅니다 …
위에서 첫 번째 줄에 있는 “아름다운” 이라는 단어를 학습한다고 해봅시다. 왼쪽과 오른쪽 각각 2개의 단어를 예측할 때 포지티브 샘플에 해당하는 단어는 “하나”, “에”, “말”, “한마디” 입니다. 이 네 단어를 제외한 모든 단어는 Negative sample에 해당합니다. 즉 네거티브 샘플링을 사용하면 예측 대상이 전체 단어의 개수인 10,000개에서 $k+1$ 개로 줄어듭니다. 이렇게 샘플링한 후에는 $k+1$ 개 각각의 학습 세트에 대해 이 세트가 포지티브 샘플인지 네거티브 샘플인지를 예측하는 이진 분류(Binary classification) 작업을 수행합니다.
일반적으로 학습 데이터가 작은 경우에는 $5 \leq k \leq 20$ 정도가 적당하며, 말뭉치가 클 때는 $2 \leq k \leq 5$ 정도로 조정합니다. 예를 들어, “아름다운”을 타겟 단어로 하여 $k = 5$로 네거티브 샘플링하여 학습한다고 하면 학습 데이터셋을 아래와 같이 구성하게 됩니다. 아래 표에서 $w_t$ 는 타겟 단어이며 $w_p$ 는 각 포지티브 샘플이고, $w_{n}$ 은 각각의 네거티브 샘플입니다.
$w_t$
$w_p$
$w_{n_1}$
$w_{n_2}$
$w_{n_3}$
$w_{n_4}$
$w_{n_5}$
아름다운
하나
어머님
소학교
들
비둘기
토끼
아름다운
에
계집애
노새
애기
과
한
아름다운
말
강아지
벌써
시인
의
불러
아름다운
한마디
했
봅니다
이국
이름
된
각각에 대해 이진 분류를 수행하므로 $k = 5$인 경우에는 $(1+5) \times 300 = 1,800$ 개가 됩니다. 학습해야 할 파라미터의 개수가 $3,000,000 \rightarrow 1,800$ 로 매우 많이 줄어든 것을 볼 수 있습니다.
그런데 네거티브 샘플을 구성하는 단어는 어떤 기준으로 뽑는 것일까요? 논문에서는 말뭉치에 자주 등장하지 않는 단어에 가중치를 줄 수 있도록 네거티브 샘플 확률을 설정하였습니다. $f(w_i)$를 말뭉치의 단어 $w_i$가 등장할 빈도라고 할 때 네거티브 샘플이 될 확률 $P(w_i)$은 아래와 같습니다.
\[P(w_i) = \frac{f(w_i)^{3/4}}{\sum_{j=0}^n (f(w_i)^{3/4})}\]
예를 들어, 전체 말뭉치가 4개의 단어 $w_1, w_2, w_3, w_4$로만 구성되어 있고 각 단어의 빈도는 $f(w_1) = 0.1, f(w_2) = 0.2, f(w_3) = 0.3, f(w_4) = 0.4$ 라고 해봅시다. 이 때, 각 단어가 네거티브 샘플로 뽑힐 확률은 다음과 같습니다.
\[\begin{aligned}
P(w_1) = \frac{0.1^{3/4}}{0.1^3/4+0.2^3/4+0.3^3/4+0.4^3/4} = 0.1284 \\
P(w_2) = \frac{0.2^{3/4}}{0.1^3/4+0.2^3/4+0.3^3/4+0.4^3/4} = 0.2159 \\
P(w_3) = \frac{0.3^{3/4}}{0.1^3/4+0.2^3/4+0.3^3/4+0.4^3/4} = 0.2926 \\
P(w_4) = \frac{0.4^{3/4}}{0.1^3/4+0.2^3/4+0.3^3/4+0.4^3/4} = 0.3631
\end{aligned}\]
빈도가 적은 $w_1, w_2$ 는 원래 단어의 빈도보다 네거티브 샘플이 될 확률이 늘어나는 것을 볼 수 있고, 빈도가 높은 $w_3, w_4$ 는 원래 단어의 빈도보다 낮게 계산되는 것을 볼 수 있습니다.
네거티브 샘플링을 사용하면 각 이진 분류에 대해 시그모이드 함수 $\sigma$ 를 활성화 함수로 사용하게 됩니다. 네거티브 샘플링을 사용하여 변화된 타겟 단어 마다의 목적 함수 $J(\theta)$는 다음과 같이 변하게 됩니다.
\[J_t (\theta) = \log \sigma(u_o^T v_c) + \sum_{i=1}^T E_{i \sim P(W)} \big[\log \sigma(-u_i^T v_c)\big] \\\]
Word Pairs or Phrases to Word
계산량을 줄이는 마지막 방법으로 통상적으로 쓰이는 관용어구를 하나의 단어로 취급하는 방법이 있습니다. 예를 들어, “Boston Globe”(신문사 이름)과 같은 고유명사나 “this is” 처럼 통상적으로 쓰이는 관용어구를 하나의 단어로 처리합니다.
본 포스트의 내용은 고려대학교 강필성 교수님의 강의 와 김기현의 자연어처리 딥러닝 캠프 , 밑바닥에서 시작하는 딥러닝 2 , 한국어 임베딩 책을 참고하였습니다.
Word2Vec
지난번 게시물에 있었던 확률기반 신경망 언어 모델(NPLM)은 처음으로 단어 임베딩을 언어 모델에 사용하였습니다. 이번에는 단어 임베딩에서 가장 많이 쓰이는 모델인 Word2Vec에 대해서 알아보겠습니다. Word2Vec에는 크게 CBoW(Continuous Bag-of-Words)와 Skip-gram의 2가지 방법이 있습니다.
CBoW & Skip-gram
NPLM에서도 가정했던 것처럼 Word2Vec의 두 방법 CBoW와 Skip-gram은 모두 “특정 단어 주변에 있는 단어는 유사한 관계를 맺고 있을 것이다”라는 전제를 하고 있습니다. 이런 전제에 따라
결정적인 차이는 학습의 기준이 되는 단어와 학습할 단어의 차이에 있습니다. 윤동주 시인의 시를 통해서 CBoW와 Skip-gram이 어떻게 학습을 해가는지를 알아보겠습니다. 아래는 Mecab 으로 추출한 별헤는 밤의 형태소 일부입니다.
“… 어머님 나 는 별 하나 에 아름다운 말 한마디 씩 불러 봅니다 …”
이 가사를 CBoW를 활용하면 아래의 빈칸에 들어갈 단어를 예상하는 과정으로 학습이 진행됩니다.
“… 나 는 [ __ ] 하나 에 … “
“… 는 별 [ ____ ] 에 아름다운 …”
“… 별 하나 [ __ ] 아름다운 말 …”
“… 하나 에 [ _________ ] 말 한마디 …”
Skip-gram을 진행하면 다음의 빈칸에 들어갈 단어를 예상하는 과정으로 학습이 진행되지요.
“… [ __ ] [ __ ]별 [ ____ ] [ __ ] …”
“… [ __ ] [ __ ]하나 [ __ ] [________ ] …”
“… [ __ ] [ ____ ] 에 [ _________ ] [ __ ] …”
“… [ ____ ] [ __ ] 아름다운 [ __ ] [ ______ ] …”
위 처럼 CBoW는 주변 단어(Context)를 보고 타겟 단어 $w_t$ 를 예측하게 되고, Skip-gram은 타겟 단어 $w_t$ 를 보고 주변 단어 $C$ 를 입력하게 됩니다. 얼핏 생각해보면 더 많은 정보를 받아서 단어를 예측하는 CBoW의 성능이 좋을 것으로 생각하기 쉽습니다. 실제로는 Skip-gram 방법이 역전파를 통해 더 많은 학습 정보를 받을 수 있습니다. 아래는 학습이 되는 과정을 도식화한 이미지입니다.
이미지 출처 : researchgate.net
위 그림을 역전파의 관점에서 생각해보면 CBoW는 타겟 단어 $w_t$의 학습 정보를 주변 단어 4개가 모두 나누어 받게 됩니다. 반대로 Skip-gram은 타겟 단어 $w_t$ 가 무려 주변 단어 4개의 학습 정보를 받게 됩니다. 실제로 Skip-gram이 성능이 더 좋지만 하나의 타겟 단어를 학습하는데 4단어에 대한 학습을 진행하므로 시간이 더 오래 걸리고 더 많은 컴퓨팅 자원을 필요로 한다는 단점이 있습니다.
Structure
실제로는 모델의 성능 덕분에 CBoW보다는 Skip-gram이 더 많이 사용됩니다. 그렇기 때문에 이번 게시물에서는 Skip-gram을 중심으로 어떻게 학습이 진행되는 지를 알아보겠습니다. 일단 Skip-gram 모델의 기본적인 구조는 아래와 같이 생겼습니다.
이미지 출처 : mccormickml.com
가장 왼쪽에 있는 입력 벡터는 원-핫 인코딩을 거친 벡터로 우리가 알고 있는 타겟 단어만 $1$ 로 표시됩니다. 총 10,000개의 단어가 있을 때 300차원으로 임베딩 하기 위해서는 아래와 같은 가중치 행렬(Weight matrix, 주황색)가 필요하게 되고 이를 참조(Lookup)하여 단어 임베딩 벡터로 이루어진 행렬(파란색)을 만들게 됩니다.
이미지 출처 : mccormickml.com
임베딩을 마친 단어 임베딩 벡터는 출력층에서 소프트맥스 함수를 통해서 주변 단어를 각각 예측하게 됩니다.
이미지 출처 : mccormickml.com
실제 학습과정에서는 4개의 단어를 한꺼번에 학습 하는 것이 아니라 (타겟단어, 주변단어)처럼 타겟 단어와 각 주변 단어의 쌍을 만들어 각각을 학습합니다. 아래 이미지는 모델에서 이런 방식으로 학습 샘플을 만드는 것을 잘 나타내는 그림입니다.
이미지 출처 : mccormickml.com
Skip-gram with Gradient Ascent
Skip-gram의 목적 함수 $J(\theta)$를 다음과 같이 나타낼 수 있습니다. $\theta$ 는 파라미터 행렬이며 $t$ 는 각 타겟 단어인 $w_t$ 를 가리킵니다.
\[J(\theta) = \frac{1}{T} \sum^T_{t=1} \sum_{-m \leq j \leq m, j \neq 0} \log p(w_{t+j}|w_t) = \frac{1}{T} \sum^T_{t=1} J_t (\theta)\]그럼 이 목적함수를 바탕으로 Skip-gram에서 경사 상승법을 통해 학습이 진행되는 과정을 살펴보겠습니다. 수식의 단순화를 위하여 $w_{t+j} \rightarrow o, w_t \rightarrow c$(outside, center)로 나타내면 주변 단어의 확률을 아래와 같이 나타낼 수 있습니다.
\[p(o|c) = \frac{\exp(u_o^Tv_c)}{\sum^W_{w=1} \exp(u_w^Tv_c)}\]위 확률을 최대화하는 것이 목적입니다. 타겟 단어마다의 목적 함수 $J_t(\theta)$ 와 $\text{argmax}$ 를 사용하면 식을 아래와 같이 나타낼 수 있습니다.
\[\hat{v_c} = \text{argmax}_{v_c} J_t(\theta) = \text{argmax}_{v_c} \log p(w_o|w_t)\]확률을 최대화 하는 $v_c$를 찾는 것아야 하기 때문에 $v_c$로 편미분한 식을 $0$ 으로 만드는 $v_c$를 찾아야합니다. 수식으로 알아보도록 하겠습니다.
\[\begin{aligned} \frac{\partial}{\partial v_c} \log p(o|c) &= \frac{\partial}{\partial v_c} \log \frac{\exp(u_o^Tv_c)}{\sum^W_{w=1} \exp(u_w^Tv_c)}\\ &= \frac{\partial}{\partial v_c} u_o^Tv_c-\frac{\partial}{\partial v_c} \log \sum^W_{w=1} \exp(u^T_w v_c) \\ &= u_o - \frac{1}{\sum^W_{w=1} \exp(u^T_w v_c)} \cdot \sum^W_{w=1} \exp(u^T_w v_c) \cdot u_w \\ &= u_o - \sum^W_{w=1}\frac{\exp(u^T_w v_c)}{\sum^W_{w=1} \exp(u^T_w v_c)} \cdot u_w \\ &= u_o - \sum^W_{w=1} P(w|c) \cdot u_w \end{aligned}\]확률을 최대화 하는 것이 목적이므로 경사 상승법(Gradient Ascent)을 적용하여 가중치 벡터 $v_c$ 를 개선해나가게 됩니다.
\[v_c(t+1) = v_c(t) + \alpha \bigg(u_o - \sum^W_{w=1} P(w|c) \cdot u_w\bigg)\]Skip-gram with Sampling
Skip-gram의 단점은 계산량이 많아 시간이 오래 걸린다는 점입니다. 아무런 처리가 없을 때, $V$개의 단어를 가진 말뭉치를 $N$차원의 임베딩 벡터로 학습하려면 $2\times V\times N$ 만큼의 가중치를 학습해야 합니다. 위 그림처럼 “brown”이 타깃 단어이고 주변 단어에 “fox”가 있을 때 (brown, fox)로 학습하고, “fox”가 타깃 단어이고 주변 단어에 “brown”이 있을 때에는 (fox, brown)을 학습하기 때문입니다. 이를 위해 고안된 샘플링(Sampling) 기법은 중요도가 떨어지는 단어의 개수를 줄임으로써 임베딩 벡터의 성능을 떨어뜨리지 않으면서도 계산량을 줄일 수 있도록 하는 방법입니다.
Sub-sampling
서브샘플링(Sub-sampling)은 자주 등장하는 단어를 학습 대상에서 제외하는 방법입니다. 아래 식에서 $P(w_i)$는 단어 빈도 $f(w_i)$ 에 따라서 이 값이 높은 단어를 누락시키는 확률입니다. $t$ 는 임계값(threshold)입니다.
\[P(w_i) = 1 - \sqrt{\frac{t}{f(w_i)}}\]예를 들어, 총 말뭉치에 등장하는 단어 중 10,000번에 1번 등장하는 단어 $w_1$이 학습에서 누락될 확률과 100번에 1번 등장하는 단어 $w_2$가 학습에서 누락될 확률을 비교해봅시다. 이 때 $t = 10^{-5}$ 로 설정하겠습니다.
\[\begin{aligned} P(w_1) &= 1 - \sqrt{\frac{10^{-5}}{10^{-4}}} = 1 - \sqrt{\frac{1}{10}} = 0.6838 \qquad \because f(w_1) = \frac{1}{10000} = 10^{-4} \\ P(w_2) &= 1 - \sqrt{\frac{10^{-5}}{10^{-2}}} = 1 - \sqrt{\frac{1}{1000}} = 0.9684 \qquad \because f(w_2) = \frac{1}{100} = 10^{-2} \end{aligned}\]위 식을 보면 $w_1$ 은 말뭉치에 100번 등장할 때 약 68개의 단어가 누락되므로 32개의 단어만 학습에 사용됩니다. 하지만 $w_2$ 는 말뭉치에 1000번이나 등장하더라도 968개의 단어가 누락되므로 32개의 단어만 학습에 사용됩니다. 이렇게 서브샘플링을 하면 자주 나오는 단어들에 대한 확률을 급격히 낮춤으로써 계산량을 줄일 수 있습니다.
Negative Sampling
네거티브 샘플링을 설명하기 위해서 위에서 사용했던 Skip-gram의 구조 이미지를 다시 가져와 보겠습니다.
이미지 출처 : mccormickml.com
이 구조에 따르면 총 10,000단어에 대한 300개의 임베딩 벡터를 학습하기 위해서 소프트맥스 단계의 행렬의 요소는 $10,000 \times 300 = 3,000,000$개가 됩니다. 각각의 요소를 경사 상승법으로 반복해서 학습하기에는 너무 많은 양이지요. 네거티브 샘플링(Negative Sampling)은 수많은 파라미터 중 일부만을 학습하기 위해 고안된 전략입니다.
네거티브 샘플링 전략을 사용하지 않았을 때는 타겟 단어 $w_t$와 주변 단어 중 하나인 $w_o$에 대하여 학습 샘플이 $(w_t, w_o)$로 계산됩니다. 결국 하나의 계산마다 $w_o$를 구할 때 10,000개 단어 전부를 예측의 대상으로 하기 때문에, 소프트맥스의 계산량이 매우 많습니다. 네거티브 샘플링은 예측 대상을 포지티브 샘플(Positive sample) $1$개와 네거티브 샘플(Negative sample) $k$개로 구성함으로써 소프트맥스 계산을 줄일 수 있습니다.
위에서 포지티브 샘플은 $w_o$ 에 해당하는 단어이고, 네거티브 샘플은 $w_o$에 해당하지 않는 단어입니다. 위에서 했던 <별 헤는="" 밤="">을 예시로 다시 가져와 보겠습니다.
… 어머님 나 는 별 하나 에 아름다운 말 한마디 씩 불러 봅니다 소학교 때 책상 을 같이 했 던 아이 들 의 이름 과 패 경 옥 이런 이국 소녀 들 의 이름 과 벌써 애기 어머니 된 계집애 들 의 이름 과 가난 한 이웃 사람 들 의 이름 과 비둘기 강아지 토끼 노새 노루 프란시스 쟘 라이너 마리아 릴케 이런 시인 의 이름 을 불러 봅니다 …
위에서 첫 번째 줄에 있는 “아름다운” 이라는 단어를 학습한다고 해봅시다. 왼쪽과 오른쪽 각각 2개의 단어를 예측할 때 포지티브 샘플에 해당하는 단어는 “하나”, “에”, “말”, “한마디” 입니다. 이 네 단어를 제외한 모든 단어는 Negative sample에 해당합니다. 즉 네거티브 샘플링을 사용하면 예측 대상이 전체 단어의 개수인 10,000개에서 $k+1$ 개로 줄어듭니다. 이렇게 샘플링한 후에는 $k+1$ 개 각각의 학습 세트에 대해 이 세트가 포지티브 샘플인지 네거티브 샘플인지를 예측하는 이진 분류(Binary classification) 작업을 수행합니다.
일반적으로 학습 데이터가 작은 경우에는 $5 \leq k \leq 20$ 정도가 적당하며, 말뭉치가 클 때는 $2 \leq k \leq 5$ 정도로 조정합니다. 예를 들어, “아름다운”을 타겟 단어로 하여 $k = 5$로 네거티브 샘플링하여 학습한다고 하면 학습 데이터셋을 아래와 같이 구성하게 됩니다. 아래 표에서 $w_t$ 는 타겟 단어이며 $w_p$ 는 각 포지티브 샘플이고, $w_{n}$ 은 각각의 네거티브 샘플입니다.
| $w_t$ | $w_p$ | $w_{n_1}$ | $w_{n_2}$ | $w_{n_3}$ | $w_{n_4}$ | $w_{n_5}$ |
|---|---|---|---|---|---|---|
| 아름다운 | 하나 | 어머님 | 소학교 | 들 | 비둘기 | 토끼 |
| 아름다운 | 에 | 계집애 | 노새 | 애기 | 과 | 한 |
| 아름다운 | 말 | 강아지 | 벌써 | 시인 | 의 | 불러 |
| 아름다운 | 한마디 | 했 | 봅니다 | 이국 | 이름 | 된 |
각각에 대해 이진 분류를 수행하므로 $k = 5$인 경우에는 $(1+5) \times 300 = 1,800$ 개가 됩니다. 학습해야 할 파라미터의 개수가 $3,000,000 \rightarrow 1,800$ 로 매우 많이 줄어든 것을 볼 수 있습니다.
그런데 네거티브 샘플을 구성하는 단어는 어떤 기준으로 뽑는 것일까요? 논문에서는 말뭉치에 자주 등장하지 않는 단어에 가중치를 줄 수 있도록 네거티브 샘플 확률을 설정하였습니다. $f(w_i)$를 말뭉치의 단어 $w_i$가 등장할 빈도라고 할 때 네거티브 샘플이 될 확률 $P(w_i)$은 아래와 같습니다.
\[P(w_i) = \frac{f(w_i)^{3/4}}{\sum_{j=0}^n (f(w_i)^{3/4})}\]예를 들어, 전체 말뭉치가 4개의 단어 $w_1, w_2, w_3, w_4$로만 구성되어 있고 각 단어의 빈도는 $f(w_1) = 0.1, f(w_2) = 0.2, f(w_3) = 0.3, f(w_4) = 0.4$ 라고 해봅시다. 이 때, 각 단어가 네거티브 샘플로 뽑힐 확률은 다음과 같습니다.
\[\begin{aligned} P(w_1) = \frac{0.1^{3/4}}{0.1^3/4+0.2^3/4+0.3^3/4+0.4^3/4} = 0.1284 \\ P(w_2) = \frac{0.2^{3/4}}{0.1^3/4+0.2^3/4+0.3^3/4+0.4^3/4} = 0.2159 \\ P(w_3) = \frac{0.3^{3/4}}{0.1^3/4+0.2^3/4+0.3^3/4+0.4^3/4} = 0.2926 \\ P(w_4) = \frac{0.4^{3/4}}{0.1^3/4+0.2^3/4+0.3^3/4+0.4^3/4} = 0.3631 \end{aligned}\]빈도가 적은 $w_1, w_2$ 는 원래 단어의 빈도보다 네거티브 샘플이 될 확률이 늘어나는 것을 볼 수 있고, 빈도가 높은 $w_3, w_4$ 는 원래 단어의 빈도보다 낮게 계산되는 것을 볼 수 있습니다.
네거티브 샘플링을 사용하면 각 이진 분류에 대해 시그모이드 함수 $\sigma$ 를 활성화 함수로 사용하게 됩니다. 네거티브 샘플링을 사용하여 변화된 타겟 단어 마다의 목적 함수 $J(\theta)$는 다음과 같이 변하게 됩니다.
\[J_t (\theta) = \log \sigma(u_o^T v_c) + \sum_{i=1}^T E_{i \sim P(W)} \big[\log \sigma(-u_i^T v_c)\big] \\\]Word Pairs or Phrases to Word
계산량을 줄이는 마지막 방법으로 통상적으로 쓰이는 관용어구를 하나의 단어로 취급하는 방법이 있습니다. 예를 들어, “Boston Globe”(신문사 이름)과 같은 고유명사나 “this is” 처럼 통상적으로 쓰이는 관용어구를 하나의 단어로 처리합니다.
Comments