
BERT (Bidirectional Encoder Representations from Transformer)
04 Jul 2020 | NLP
본 포스트의 내용은 고려대학교 강필성 교수님의 강의 와 김기현의 자연어처리 딥러닝 캠프 , 밑바닥에서 시작하는 딥러닝 2 , 한국어 임베딩 책을 참고하였습니다.
BERT

이미지 출처 : sesameworkshop.org
BERT(Bidirectional Encoder Representations from Transformer)는 구글이 2018년 10월에 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 라는 논문을 통해서 발표한 모델입니다. 모델명을 해석해보면 ‘트랜스포머의 인코더를 양방향으로 해석하여 만들어낸 표현’을 사용하였음을 알 수 있습니다.
Structure
논문에서는 BERT Base 모델과 좀 더 크기를 키운 BERT Large 모델을 발표하였습니다.

이미지 출처 : jalammar.github.io
둘 모두 트랜스포머의 인코더 블록을 여러 개 중첩한 모델입니다. Base 모델은 총 12개의 인코더 블록(Layer)을 사용하였고, 은닉 벡터(Hidden vector)의 차원은 768, 어텐션 헤드(Attention head)는 12개를 사용하였습니다. $\text{BERT}_\text{BASE} (L=12, H=768, A=12)$ 모델의 파라미터는 총 1억 1천만(110M)개로 이전에 발표되었던 GPT의 Base 모델(117M)과 비슷합니다.
Large 모델은 총 24개의 인코더와 1024 차원의 은닉 벡터, 16개의 어텐션 헤드로 구성됩니다. $\text{BERT}_\text{BASE} (L=24, H=1024, A=16)$ 모델의 파라미터는 3억 4천만(340M)개의 파라미터를 사용합니다. 아래는 각 모델에 사용된 인코더 블록을 도식화한 이미지입니다.
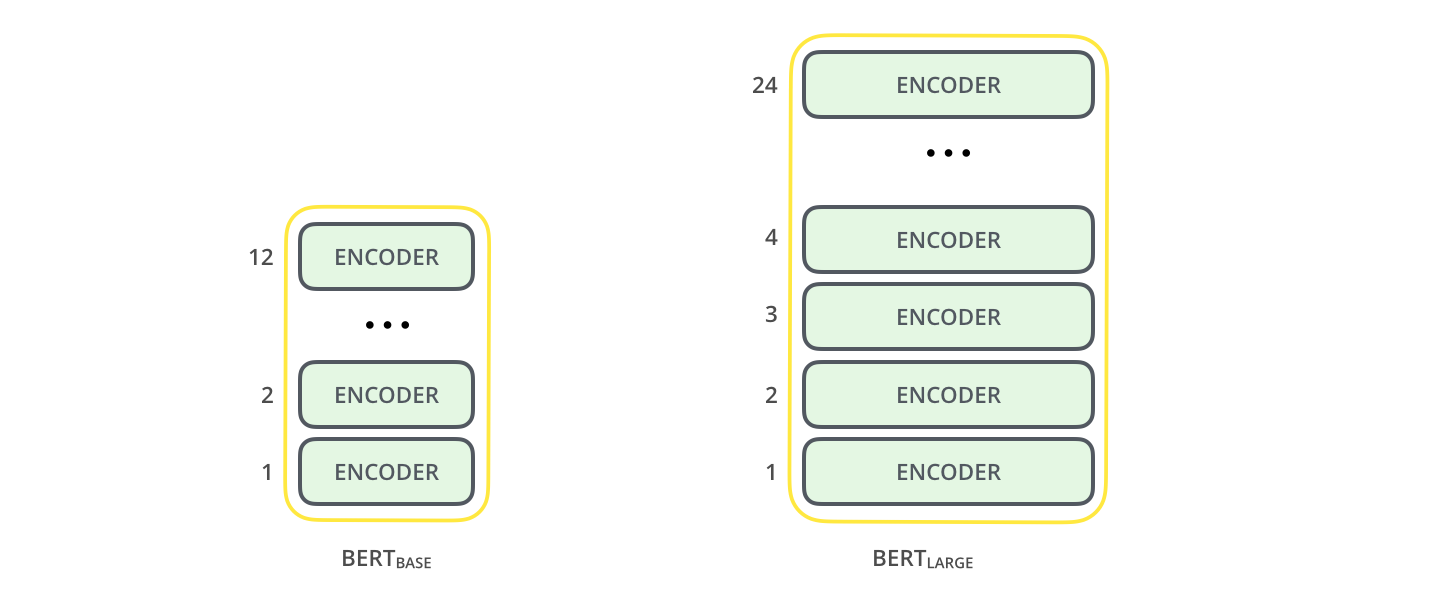
이미지 출처 : jalammar.github.io
BERT vs GPT vs ELMo
BERT는 단어를 예측할 때 문맥(Context)을 동시에 양방향(Bidirectional)으로 모두 읽어낼 수 있습니다. 아래 그림은 BERT와 이전 모델인 GPT와 ELMo의 구조를 비교하여 보여주고 있습니다. ELMo는 양방향으로 문장을 학습하지만 동시에 양방향을 보고 단어를 예측하지는 않습니다. GPT는 디코더 블록의 Masked Self-Attention을 사용하여 단어를 예측하기 때문에 단방향(Unidirectional)으로 학습을 진행합니다.

이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Input Representation
BERT는 여러 태스크에 적용하기 위해 입력 데이터를 두 가지 형태로 입력 받을 수 있도록 설계되었습니다. 입력 데이터인 “Sequence”는 하나의 “Sentence”가 될 수도 있고, 두 개의 “Sentence”가 될 수도 있지요. 앞 문장에 나오는 “Sentence”는 일반적으로 사용되는 ‘문장’과는 다른 의미를 가집니다. BERT에서 “Sentence”란 임의로 계속 이어지는 텍스트(Arbitrary span of contiguous text)라는 의미로 사용합니다. 하나의 “Sentence” 안에 (일반적인 의미의)’문장’이 하나만 있을 수도, 여러 개가 있을 수도 있지요.
아래 이미지는 데이터가 모델에 입력되는 모습을 보여주고 있습니다.

이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT에는 특정한 기능을 담당하는 스페셜 토큰이 있습니다. 첫 번째 스페셜 토큰인 [CLS](Classification token)는 모든 입력 토큰의 앞에 위치합니다. [CLS]는 학습을 진행하면서 다음 Sentence를 예측하는 정보를 담은 은닉 벡터(Hidden vector)로 거듭나게 됩니다. 두 번째 스페셜 토큰은 [SEP](Separation token)입니다. [SEP]는 입력 데이터가 두 개의 “Sentence”로 구성될 때, 둘 사이에 위치하여 “Sentence”를 구분하는 역할을 합니다. 만약 하나의 “Sentence”로만 구성된 입력 데이터라면 맨 마지막에 위치합니다.
BERT에 입력되는 벡터는 세 가지 임베딩 벡터의 합으로 구성됩니다. 첫 번째는 3만 개의 단어로 이루어진 사전으로부터 가져온 단어 토큰 임베딩 벡터입니다. 두 번째는 [SEP]을 기준으로 앞에 있는 “Sentence”인지 뒤에 있는 “Sentence”인지를 구분하는 세그먼트(Segment) 임베딩 벡터입니다. 마지막은 각 토큰이 어디에 위치하는 지를 표시하는 위치 임베딩(Positional Embedding) 벡터1입니다. 세 벡터를 모두 더한 벡터를 BERT 안으로 넣어주게 됩니다.

이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Pre-training
BERT의 사전 학습에는 약 8억 단어로 구성된 Book corpus와 25억 단어로 구성된 위키피디아 말뭉치를 사용하였습니다. 한 번에 입력할 수 있는 최대 토큰 길이는 512개이며, 배치 사이즈는 256을 사용하였습니다. 옵티마이저(Optimizer)는 Adam을 $\eta = 1.0 \times 10^{-4}, \beta_1 = 0.9, \beta_2 = 0.999$로 설정하여 사용하였습니다. $0.01$ 의 $L2$ 정칙화를 적용하였고 모든 층마다 $0.1$ 의 드롭아웃(Dropout)을 적용하여 과적합을 방지하고자 하였습니다. 활성화 함수로는 GPT와 동일한 GeLU를 사용하였습니다.
BERT는 pre-training 단계에서 두 가지 방법을 사용하여 언어를 학습합니다. 하나는 MLM(Masked Language Model)이고 나머지 하나는 NSP(Next Sentence Prediction)입니다. BERT의 성능을 크게 끌어올린 두 방법에 대해 더 자세히 알아보겠습니다.
MLM(Masked Language Model)
혹시 영어를 공부하면서 아래와 같은 문제를 풀어보신 적이 있으신가요?

이미지 출처 : news.mt.co.kr
이런 유형을 흔히 “빈칸 추론”이라고 하는데요. 이 빈칸 추론 문제는 수능 영어나 토익에서 꽤 높은 비중을 차지합니다. 문맥에 맞는 의미에 해당하는 단어를 찾거나, 문법적으로 알맞는 단어를 고르면 됩니다. 이쯤 되면 갑자기 BERT 이야기하다가 갑자기 빈칸 추론 문제가 나와서 당황하신 분이 계실텐데요. “빈칸 추론”을 언급한 이유는 BERT의 MLM이 이와 매우 유사하기 때문입니다.
BERT 이전의 언어 모델은 순차적으로 단어를 예측하는(Auto-Regressive) 방법으로 진행되었습니다. ELMo가 양방향으로 단어를 학습하기 위해서 순방향으로 학습한 임베딩 벡터와 역방향으로 학습한 임베딩 벡터를 이어 붙이기는(Concatenation) 하였습니다. 하지만 동시에 전체 문맥을 학습할 수 없는 한계점이 있었지요. GPT는 단방향(Unidirectional)으로 학습하기 때문에 문맥을 제대로 판단하기 어렵습니다. 아래 예시를 보겠습니다.
“I was (happy) that my mother complimented me.”
위 문장에서 “happy”를 학습해야 한다고 해보겠습니다. 순방향으로 학습한다면 “I was” 만을 보고 단어를 예측해야합니다. 뒤에 “happy” 한 이유를 설명하는 부분은 학습 과정에서 생략되지요. 단어 학습에서 많은 부분을 포기하게 됩니다.
하지만 BERT는 빈칸을 뚫어놓고 다음 단어를 예측합니다. 빈칸 앞과 뒤를 모두 보고 문맥을 파악하여 해당하는 단어를 맞추며 학습하지요. BERT가 위 문장에서 “happy” 를 학습한다면 아래 문장에서 [MASK]에 들어갈 단어를 학습하는 식으로 진행되겠지요.
“I was [MASK] that my mother complimented me.”
BERT는 위와 같이 입력 토큰의 15% 가량을 임의로 [MASK] 토큰으로 마스킹한 뒤에 해당 토큰 주변의 문맥을 양방향(Bidirectional)으로 탐색하여 마스킹된 단어가 실제로 어떤 단어인지를 예측합니다. MLM 방식을 채택함으로써 ELMo나 GPT가 동시에 양방향으로 문맥을 학습할 수 없었다는 한계점을 극복할 수 있었습니다.
아래는 BERT가 “Let’s stick to improvisation in this skit …” 로 시작하는 문장에서 MLM을 통해 학습하는 방법을 도식화한 이미지입니다.
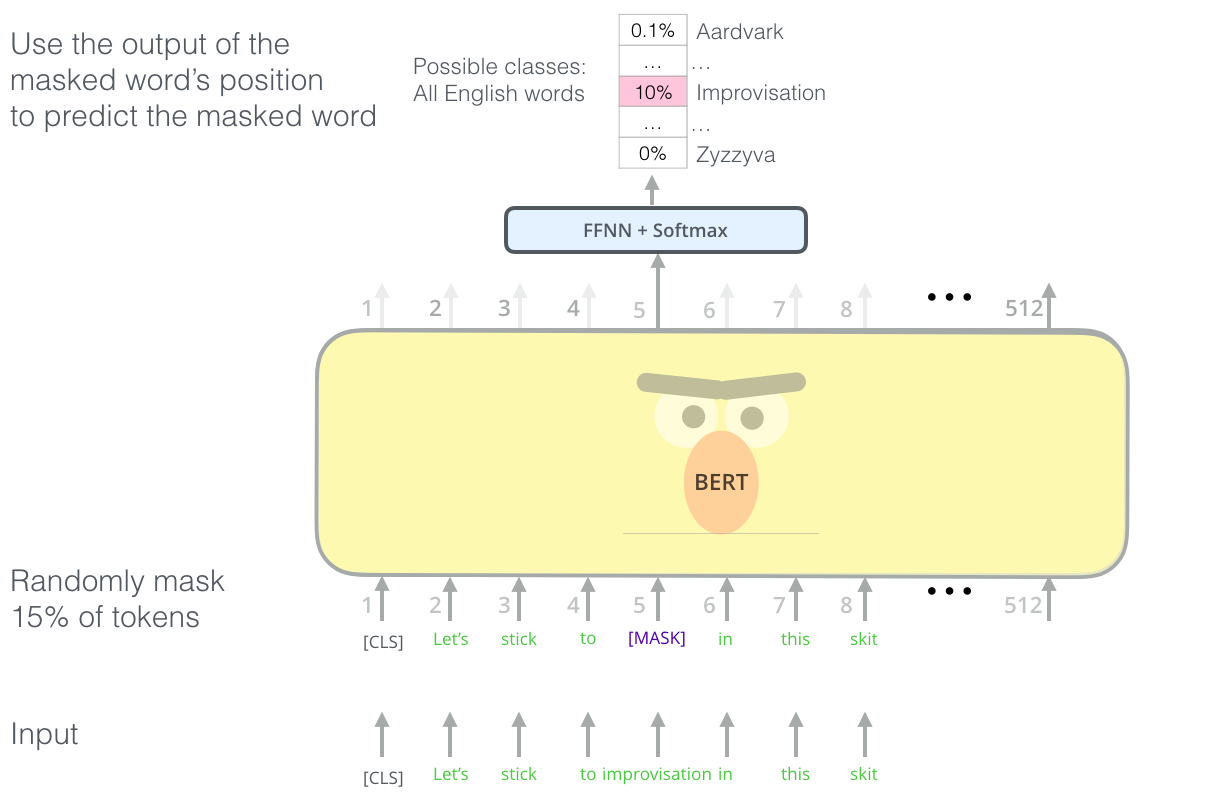
이미지 출처 : jalammar.github.io
위에서는 “improvisation”이 마스킹되었습니다. [MASK]토큰으로 변환된 상태로 모델에 입력되고 모델은 해당 단어에 들어갈 가장 적절한 단어를 확률로써 찾아냅니다. 예측한 단어가 원래 문장에 있는 단어인 “improvisation”이 되도록 모델이 학습을 진행하지요.
하지만 사뭇 완벽해보이는 MLM에도 문제가 있습니다. fine-tuning 에서는 MLM이 작동하지 않기 때문에 pre-training과 fine-tuning간 학습 불일치(discrepancy)가 발생합니다. 논문에서는 학습 과정상 불일치를 줄이기 위해서 일종의 트릭을 사용하였습니다. 마스킹 대상이 되는 단어 중에 80%만 실제로 [MASK] 토큰으로 바꾸어주는 것이지요. 나머지 20% 중 절반인 10%는 원래 단어로 두고, 남은 10%는 임의의 단어로 치환합니다. 논문에서는 불일치를 줄이기 위해서 (마스킹 : 동일 단어 : 임의의 단어)의 비율을 조정하면서 성능을 비교하였습니다. 실험 결과 80 : 10 : 10 일 때의 성능이 가장 좋음을 아래 표를 통해서 보여주고 있습니다.
“My dog is hairy” $\rightarrow$ “My dog is [MASK]” - (80%)
“My dog is hairy” $\rightarrow$ “My dog is hairy” - (10%)
“My dog is hairy” $\rightarrow$ “My dog is apple - (10%)

이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
NSP(Next Sentence Prediction)
동문서답 사자성어는 아래와 같은 의미를 가지고 있지요.

이미지 출처 : wordrow.kr
우리는 질문할 때 질문을 받은 사람이 질문 의도에 맞는 적절한 답을 해주기를 원합니다. 질문과는 상관없는 대답, 즉 동문서답을 한다면 짜증나겠지요. BERT도 동문서답을 하지 않도록 학습을 하는데요. NSP가 바로 이를 위한 학습 방법입니다.
NSP는 한 쌍의 “Sentence”가 들어왔을 때 [SEP] 뒤에 있는 “Sentence”가 이전 “Sentence” 바로 다음에 등장하는지를 [CLS] 토큰을 활용하여 이진 분류(IsNext, NotNext)로 예측합니다. 아래 예시를 보겠습니다.
S1 : 자연어 처리 또는 자연 언어 처리는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나다.
S2 : 자연 언어 처리는 연구 대상이 언어 이기 때문에 당연하게도 언어 자체를 연구하는 언어학과 언어 현상의 내적 기재를 탐구하는 언어 인지 과학과 연관이 깊다.
위 예시에서 S1과 S2는 위키피디아 - 자연어처리의 첫 두 문장으로 실제로 이어지는 문장입니다. BERT는 이런 문장을 IsNext 로 판단하도록 학습합니다. 반대로 NSP가 NotNext로 판단해야 하는 한 쌍의 문장은 다음과 같습니다.
S1 : 자연어 처리 또는 자연 언어 처리는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나다.
S2` : 전세계 최대 규모의 동영상 공유 사이트로서, 유튜브 이용자가 영상을 시청·업로드·공유할 수 있다.
위 예시의 S2` 는 위키피디아 - 유튜브의 두 번째 문장입니다. S1과 실제로 이어지지 않는 문장이며 문맥적으로도 아무 상관이 없지요.
QA(Question & Answering)나 NLI(Natural Language Inference, 자연어 추론) 등의 복잡한 태스크를 풀기 위해서는 “Sentence” 사이의 관계를 이해해야 합니다. BERT 이전의 모델은 두 텍스트 사이의 관계를 학습하지 않았습니다. 그렇기 때문에 이런 복잡한 문제에 대해 좋은 성능을 보이지 못했지요. BERT의 NSP는 이를 [CLS] 토큰 하나를 학습시키는 간단한 방법으로 극복하였습니다. 아래 이미지는 NSP 학습을 잘 보여주는 이미지입니다.

이미지 출처 : jalammar.github.io
실제 pre-training 과정에서는 입력할 2개의 “Sentence”를 뽑을 때 50%는 실제로 이어지는 쌍을, 나머지 50%는 이어지지 않는 쌍을 임의로 구성합니다. 그리고 [CLS]로 바로 다음에 이어지는 문장인지(IsNext) 떨어져 있는 문장인지(NotNext) 를 예측하지요. 아래는 NSP 예시 이미지입니다.


이미지 출처 : github.com/pilsung-kang
위에서 언급한 것처럼 NSP는 매우 간단한 방법을 통해서 성능을 올릴 수 있었습니다. 아래는 pre-training에서 NSP를 학습한 모델과 그렇지 않은 모델의 성능을 비교한 표입니다. NSP 방법으로 학습한 모델이 그렇지 않은 모델보다 NLI(QNLI), QA(SQuAD) 등의 태스크에서 좋은 성능을 보임을 확인할 수 있습니다.

이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Fine-Tuning
이어서 BERT의 fine-Tuning에 대해서 알아보겠습니다. fine-tuning은 pre-trained BERT를 목적에 맞는 태스크에 사용하기 위해서 수행합니다. pre-trained BERT위에 하나의 층을 더 쌓아 원하는 데이터를 학습시키면 태스크를 수행할 수 있는 모델이 만들어집니다.
fine-tuning 방법을 태스크에 따라 크게 4가지로 구분해 볼 수 있습니다. 아래 그림을 통해 각 빙법에 대해 알아보겠습니다.
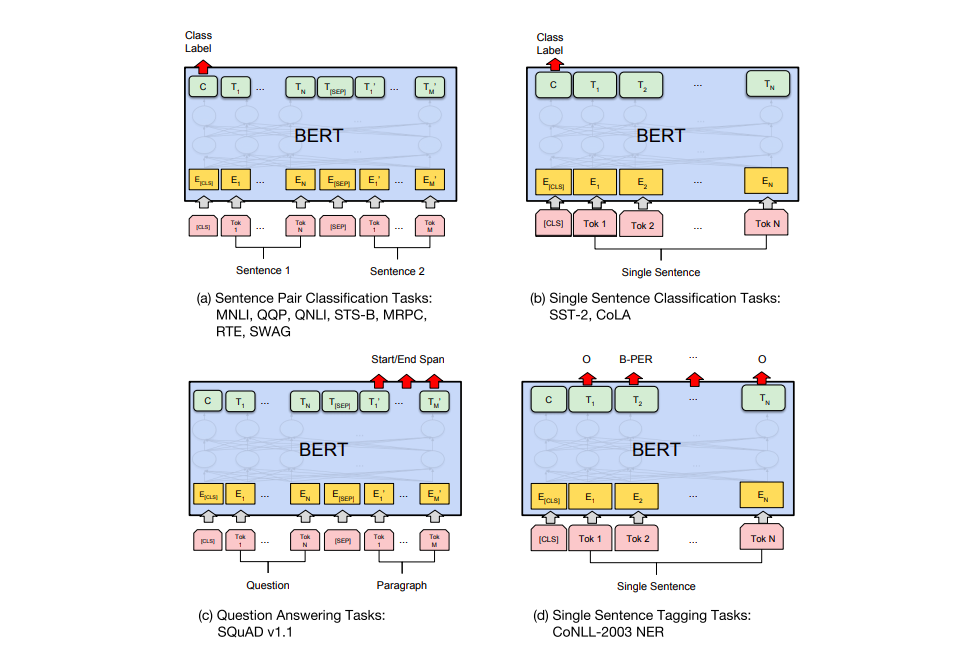
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
(a)는 “Sentence” 쌍을 분류하는 태스크에 대하여 데이터를 입력하는 방식입니다. “Sentence” 쌍을 입력받은 모델은 [CLS] 토큰이 출력하는 Class label을 반환합니다. (b)는 감성분석 등 하나의 문장을 입력하여 해당 문장을 분류하는 태스크에서 데이터를 입력하는 방식입니다. (c)는 질의응답(Question & Answering)에 대해 데이터를 입력하는 방식입니다. 질문과 본문에 해당하는 단락을 [SEP] 토큰으로 나누어 입력한 뒤 답을 출력하도록 합니다. (d)는 토큰마다 답을 내야 하는 개체명 인식(Named Entity Recognition, NER) 등의 태스크를 fine-tuning하는 방법입니다.
아래는 여러 데이터셋에 대하여 BERT와 이전 모델의 성능을 비교하여 나타낸 표입니다. BERT BASE 만으로도 이전에 발표된 모델보다 대부분 더 좋은 성능을 보임을 확인할 수 있습니다. BERT LARGE의 경우 CoLA, RTE등의 데이터셋에는 BASE 보다도 더욱 좋은 성능을 나타내며 SOTA를 달성하였습니다.

이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Ablation Study
논문에서는 여러 조건을 바꾸어가며 추가적인 연구를 진행했습니다. 첫 번째로 BERT 모델의 사이즈를 바꾸어가며 성능을 평가하였습니다. $#L$은 인코더 블록의 개수이고 $#H$와 $#A$ 는 각각 임베딩 벡터 차원과 어텐션 헤드의 개수입니다. 아래 그림에서 4번째 행에 있는 모델이 BERT BASE이며 맨 아래에 있는 모델이 BERT LARGE입니다. 아래 표에서 모델의 사이즈를 늘릴 수록 성능이 좋아지는 것을 볼 수 있습니다.

이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
논문의 저자들은 모델이 커지면 기계 번역이나 언어 모델과 같은 큰 사이즈의 태스크에 대해서는 이전부터 알려진 사실이지만, 크기가 작은 데이터셋에 대해서도 모델 사이즈를 키웠을 때 성능이 좋아짐을 확인할 수 있었던 사례임을 강조하고 있습니다.
두 번째로는 fine-tuning과 feature-based 방법에 대해 성능을 비교한 표입니다. fine-tuning은 pre-training 이후에 추가 학습 과정에서 단어 임베딩 벡터까지 업데이트 합니다. 하지만 feature-based은 단어 임베딩은 고정한 채 신경망 파라미터만 학습하는 방법입니다.
아래는 fine-tuning 과 다양한 feature-based 케이스에 대해서 모델의 성능을 비교한 표입니다. 실험 대상이 되는 모든 feature-based 모델보다 fine-tuning 모델이 좋은 성능을 보이는 것을 확인할 수 있습니다.

이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
아래는 실험한 feature-based 케이스에 대해 결과를 잘 나타내주는 이미지입니다.
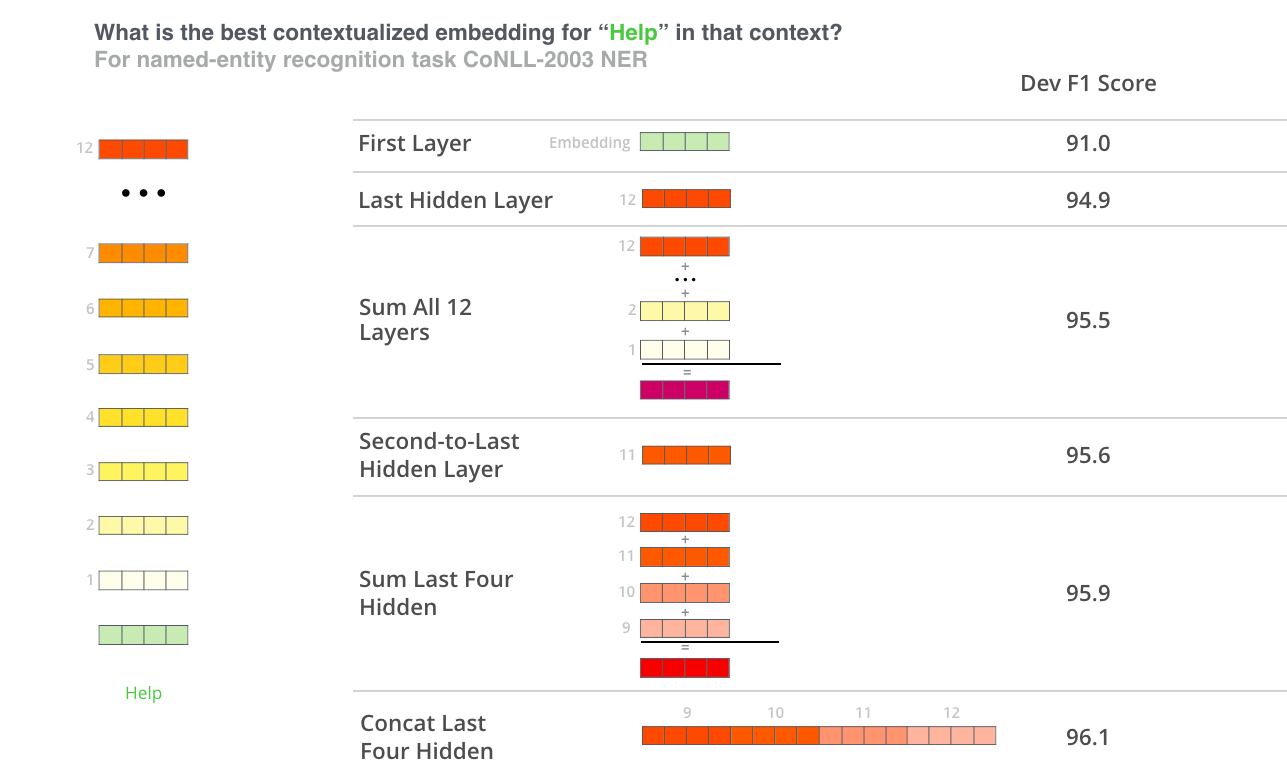
이미지 출처 : jalammar.github.io
Conclusion
BERT는 MLM과 NSP라는 특이한 pre-training 방법을 사용하여 이전 모델보다 월등한 성능을 보이며 SOTA를 달성하였습니다. 두 방법중 NSP는 이후 모델에서 삭제되기는 하지만 MLM은 문맥을 Bidirectional 학습할 수 있기 때문에 이후 모델에도 계속 사용됩니다. MLM 방법을 그대로 계승하여 BERT 개선하거나 경량화한 “RoBERTa, AlBERT…” 등이 나오게 되지요. BERT는 이러한 모델의 원조로서 자연어처리 분야의 큰 발전을 가져온 기념비적인 모델이라고 할 수 있습니다.
-
Transformer의 Positional Encoding 과는 다른 방법으로 만들어집니다. ↩
본 포스트의 내용은 고려대학교 강필성 교수님의 강의 와 김기현의 자연어처리 딥러닝 캠프 , 밑바닥에서 시작하는 딥러닝 2 , 한국어 임베딩 책을 참고하였습니다.
BERT
이미지 출처 : sesameworkshop.org
BERT(Bidirectional Encoder Representations from Transformer)는 구글이 2018년 10월에 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 라는 논문을 통해서 발표한 모델입니다. 모델명을 해석해보면 ‘트랜스포머의 인코더를 양방향으로 해석하여 만들어낸 표현’을 사용하였음을 알 수 있습니다.
Structure
논문에서는 BERT Base 모델과 좀 더 크기를 키운 BERT Large 모델을 발표하였습니다.
이미지 출처 : jalammar.github.io
둘 모두 트랜스포머의 인코더 블록을 여러 개 중첩한 모델입니다. Base 모델은 총 12개의 인코더 블록(Layer)을 사용하였고, 은닉 벡터(Hidden vector)의 차원은 768, 어텐션 헤드(Attention head)는 12개를 사용하였습니다. $\text{BERT}_\text{BASE} (L=12, H=768, A=12)$ 모델의 파라미터는 총 1억 1천만(110M)개로 이전에 발표되었던 GPT의 Base 모델(117M)과 비슷합니다.
Large 모델은 총 24개의 인코더와 1024 차원의 은닉 벡터, 16개의 어텐션 헤드로 구성됩니다. $\text{BERT}_\text{BASE} (L=24, H=1024, A=16)$ 모델의 파라미터는 3억 4천만(340M)개의 파라미터를 사용합니다. 아래는 각 모델에 사용된 인코더 블록을 도식화한 이미지입니다.
이미지 출처 : jalammar.github.io
BERT vs GPT vs ELMo
BERT는 단어를 예측할 때 문맥(Context)을 동시에 양방향(Bidirectional)으로 모두 읽어낼 수 있습니다. 아래 그림은 BERT와 이전 모델인 GPT와 ELMo의 구조를 비교하여 보여주고 있습니다. ELMo는 양방향으로 문장을 학습하지만 동시에 양방향을 보고 단어를 예측하지는 않습니다. GPT는 디코더 블록의 Masked Self-Attention을 사용하여 단어를 예측하기 때문에 단방향(Unidirectional)으로 학습을 진행합니다.
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Input Representation
BERT는 여러 태스크에 적용하기 위해 입력 데이터를 두 가지 형태로 입력 받을 수 있도록 설계되었습니다. 입력 데이터인 “Sequence”는 하나의 “Sentence”가 될 수도 있고, 두 개의 “Sentence”가 될 수도 있지요. 앞 문장에 나오는 “Sentence”는 일반적으로 사용되는 ‘문장’과는 다른 의미를 가집니다. BERT에서 “Sentence”란 임의로 계속 이어지는 텍스트(Arbitrary span of contiguous text)라는 의미로 사용합니다. 하나의 “Sentence” 안에 (일반적인 의미의)’문장’이 하나만 있을 수도, 여러 개가 있을 수도 있지요.
아래 이미지는 데이터가 모델에 입력되는 모습을 보여주고 있습니다.
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT에는 특정한 기능을 담당하는 스페셜 토큰이 있습니다. 첫 번째 스페셜 토큰인 [CLS](Classification token)는 모든 입력 토큰의 앞에 위치합니다. [CLS]는 학습을 진행하면서 다음 Sentence를 예측하는 정보를 담은 은닉 벡터(Hidden vector)로 거듭나게 됩니다. 두 번째 스페셜 토큰은 [SEP](Separation token)입니다. [SEP]는 입력 데이터가 두 개의 “Sentence”로 구성될 때, 둘 사이에 위치하여 “Sentence”를 구분하는 역할을 합니다. 만약 하나의 “Sentence”로만 구성된 입력 데이터라면 맨 마지막에 위치합니다.
BERT에 입력되는 벡터는 세 가지 임베딩 벡터의 합으로 구성됩니다. 첫 번째는 3만 개의 단어로 이루어진 사전으로부터 가져온 단어 토큰 임베딩 벡터입니다. 두 번째는 [SEP]을 기준으로 앞에 있는 “Sentence”인지 뒤에 있는 “Sentence”인지를 구분하는 세그먼트(Segment) 임베딩 벡터입니다. 마지막은 각 토큰이 어디에 위치하는 지를 표시하는 위치 임베딩(Positional Embedding) 벡터1입니다. 세 벡터를 모두 더한 벡터를 BERT 안으로 넣어주게 됩니다.
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Pre-training
BERT의 사전 학습에는 약 8억 단어로 구성된 Book corpus와 25억 단어로 구성된 위키피디아 말뭉치를 사용하였습니다. 한 번에 입력할 수 있는 최대 토큰 길이는 512개이며, 배치 사이즈는 256을 사용하였습니다. 옵티마이저(Optimizer)는 Adam을 $\eta = 1.0 \times 10^{-4}, \beta_1 = 0.9, \beta_2 = 0.999$로 설정하여 사용하였습니다. $0.01$ 의 $L2$ 정칙화를 적용하였고 모든 층마다 $0.1$ 의 드롭아웃(Dropout)을 적용하여 과적합을 방지하고자 하였습니다. 활성화 함수로는 GPT와 동일한 GeLU를 사용하였습니다.
BERT는 pre-training 단계에서 두 가지 방법을 사용하여 언어를 학습합니다. 하나는 MLM(Masked Language Model)이고 나머지 하나는 NSP(Next Sentence Prediction)입니다. BERT의 성능을 크게 끌어올린 두 방법에 대해 더 자세히 알아보겠습니다.
MLM(Masked Language Model)
혹시 영어를 공부하면서 아래와 같은 문제를 풀어보신 적이 있으신가요?
이미지 출처 : news.mt.co.kr
이런 유형을 흔히 “빈칸 추론”이라고 하는데요. 이 빈칸 추론 문제는 수능 영어나 토익에서 꽤 높은 비중을 차지합니다. 문맥에 맞는 의미에 해당하는 단어를 찾거나, 문법적으로 알맞는 단어를 고르면 됩니다. 이쯤 되면 갑자기 BERT 이야기하다가 갑자기 빈칸 추론 문제가 나와서 당황하신 분이 계실텐데요. “빈칸 추론”을 언급한 이유는 BERT의 MLM이 이와 매우 유사하기 때문입니다.
BERT 이전의 언어 모델은 순차적으로 단어를 예측하는(Auto-Regressive) 방법으로 진행되었습니다. ELMo가 양방향으로 단어를 학습하기 위해서 순방향으로 학습한 임베딩 벡터와 역방향으로 학습한 임베딩 벡터를 이어 붙이기는(Concatenation) 하였습니다. 하지만 동시에 전체 문맥을 학습할 수 없는 한계점이 있었지요. GPT는 단방향(Unidirectional)으로 학습하기 때문에 문맥을 제대로 판단하기 어렵습니다. 아래 예시를 보겠습니다.
“I was (happy) that my mother complimented me.”
위 문장에서 “happy”를 학습해야 한다고 해보겠습니다. 순방향으로 학습한다면 “I was” 만을 보고 단어를 예측해야합니다. 뒤에 “happy” 한 이유를 설명하는 부분은 학습 과정에서 생략되지요. 단어 학습에서 많은 부분을 포기하게 됩니다.
하지만 BERT는 빈칸을 뚫어놓고 다음 단어를 예측합니다. 빈칸 앞과 뒤를 모두 보고 문맥을 파악하여 해당하는 단어를 맞추며 학습하지요. BERT가 위 문장에서 “happy” 를 학습한다면 아래 문장에서 [MASK]에 들어갈 단어를 학습하는 식으로 진행되겠지요.
“I was [MASK] that my mother complimented me.”
BERT는 위와 같이 입력 토큰의 15% 가량을 임의로 [MASK] 토큰으로 마스킹한 뒤에 해당 토큰 주변의 문맥을 양방향(Bidirectional)으로 탐색하여 마스킹된 단어가 실제로 어떤 단어인지를 예측합니다. MLM 방식을 채택함으로써 ELMo나 GPT가 동시에 양방향으로 문맥을 학습할 수 없었다는 한계점을 극복할 수 있었습니다.
아래는 BERT가 “Let’s stick to improvisation in this skit …” 로 시작하는 문장에서 MLM을 통해 학습하는 방법을 도식화한 이미지입니다.
이미지 출처 : jalammar.github.io
위에서는 “improvisation”이 마스킹되었습니다. [MASK]토큰으로 변환된 상태로 모델에 입력되고 모델은 해당 단어에 들어갈 가장 적절한 단어를 확률로써 찾아냅니다. 예측한 단어가 원래 문장에 있는 단어인 “improvisation”이 되도록 모델이 학습을 진행하지요.
하지만 사뭇 완벽해보이는 MLM에도 문제가 있습니다. fine-tuning 에서는 MLM이 작동하지 않기 때문에 pre-training과 fine-tuning간 학습 불일치(discrepancy)가 발생합니다. 논문에서는 학습 과정상 불일치를 줄이기 위해서 일종의 트릭을 사용하였습니다. 마스킹 대상이 되는 단어 중에 80%만 실제로 [MASK] 토큰으로 바꾸어주는 것이지요. 나머지 20% 중 절반인 10%는 원래 단어로 두고, 남은 10%는 임의의 단어로 치환합니다. 논문에서는 불일치를 줄이기 위해서 (마스킹 : 동일 단어 : 임의의 단어)의 비율을 조정하면서 성능을 비교하였습니다. 실험 결과 80 : 10 : 10 일 때의 성능이 가장 좋음을 아래 표를 통해서 보여주고 있습니다.
“My dog is hairy” $\rightarrow$ “My dog is [MASK]” - (80%)
“My dog is hairy” $\rightarrow$ “My dog is hairy” - (10%)
“My dog is hairy” $\rightarrow$ “My dog is apple - (10%)
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
NSP(Next Sentence Prediction)
동문서답 사자성어는 아래와 같은 의미를 가지고 있지요.
이미지 출처 : wordrow.kr
우리는 질문할 때 질문을 받은 사람이 질문 의도에 맞는 적절한 답을 해주기를 원합니다. 질문과는 상관없는 대답, 즉 동문서답을 한다면 짜증나겠지요. BERT도 동문서답을 하지 않도록 학습을 하는데요. NSP가 바로 이를 위한 학습 방법입니다.
NSP는 한 쌍의 “Sentence”가 들어왔을 때 [SEP] 뒤에 있는 “Sentence”가 이전 “Sentence” 바로 다음에 등장하는지를 [CLS] 토큰을 활용하여 이진 분류(IsNext, NotNext)로 예측합니다. 아래 예시를 보겠습니다.
S1 : 자연어 처리 또는 자연 언어 처리는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나다.
S2 : 자연 언어 처리는 연구 대상이 언어 이기 때문에 당연하게도 언어 자체를 연구하는 언어학과 언어 현상의 내적 기재를 탐구하는 언어 인지 과학과 연관이 깊다.
위 예시에서 S1과 S2는 위키피디아 - 자연어처리의 첫 두 문장으로 실제로 이어지는 문장입니다. BERT는 이런 문장을 IsNext 로 판단하도록 학습합니다. 반대로 NSP가 NotNext로 판단해야 하는 한 쌍의 문장은 다음과 같습니다.
S1 : 자연어 처리 또는 자연 언어 처리는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나다.
S2` : 전세계 최대 규모의 동영상 공유 사이트로서, 유튜브 이용자가 영상을 시청·업로드·공유할 수 있다.
위 예시의 S2` 는 위키피디아 - 유튜브의 두 번째 문장입니다. S1과 실제로 이어지지 않는 문장이며 문맥적으로도 아무 상관이 없지요.
QA(Question & Answering)나 NLI(Natural Language Inference, 자연어 추론) 등의 복잡한 태스크를 풀기 위해서는 “Sentence” 사이의 관계를 이해해야 합니다. BERT 이전의 모델은 두 텍스트 사이의 관계를 학습하지 않았습니다. 그렇기 때문에 이런 복잡한 문제에 대해 좋은 성능을 보이지 못했지요. BERT의 NSP는 이를 [CLS] 토큰 하나를 학습시키는 간단한 방법으로 극복하였습니다. 아래 이미지는 NSP 학습을 잘 보여주는 이미지입니다.
이미지 출처 : jalammar.github.io
실제 pre-training 과정에서는 입력할 2개의 “Sentence”를 뽑을 때 50%는 실제로 이어지는 쌍을, 나머지 50%는 이어지지 않는 쌍을 임의로 구성합니다. 그리고 [CLS]로 바로 다음에 이어지는 문장인지(IsNext) 떨어져 있는 문장인지(NotNext) 를 예측하지요. 아래는 NSP 예시 이미지입니다.
이미지 출처 : github.com/pilsung-kang
위에서 언급한 것처럼 NSP는 매우 간단한 방법을 통해서 성능을 올릴 수 있었습니다. 아래는 pre-training에서 NSP를 학습한 모델과 그렇지 않은 모델의 성능을 비교한 표입니다. NSP 방법으로 학습한 모델이 그렇지 않은 모델보다 NLI(QNLI), QA(SQuAD) 등의 태스크에서 좋은 성능을 보임을 확인할 수 있습니다.
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Fine-Tuning
이어서 BERT의 fine-Tuning에 대해서 알아보겠습니다. fine-tuning은 pre-trained BERT를 목적에 맞는 태스크에 사용하기 위해서 수행합니다. pre-trained BERT위에 하나의 층을 더 쌓아 원하는 데이터를 학습시키면 태스크를 수행할 수 있는 모델이 만들어집니다.
fine-tuning 방법을 태스크에 따라 크게 4가지로 구분해 볼 수 있습니다. 아래 그림을 통해 각 빙법에 대해 알아보겠습니다.
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
(a)는 “Sentence” 쌍을 분류하는 태스크에 대하여 데이터를 입력하는 방식입니다. “Sentence” 쌍을 입력받은 모델은 [CLS] 토큰이 출력하는 Class label을 반환합니다. (b)는 감성분석 등 하나의 문장을 입력하여 해당 문장을 분류하는 태스크에서 데이터를 입력하는 방식입니다. (c)는 질의응답(Question & Answering)에 대해 데이터를 입력하는 방식입니다. 질문과 본문에 해당하는 단락을 [SEP] 토큰으로 나누어 입력한 뒤 답을 출력하도록 합니다. (d)는 토큰마다 답을 내야 하는 개체명 인식(Named Entity Recognition, NER) 등의 태스크를 fine-tuning하는 방법입니다.
아래는 여러 데이터셋에 대하여 BERT와 이전 모델의 성능을 비교하여 나타낸 표입니다. BERT BASE 만으로도 이전에 발표된 모델보다 대부분 더 좋은 성능을 보임을 확인할 수 있습니다. BERT LARGE의 경우 CoLA, RTE등의 데이터셋에는 BASE 보다도 더욱 좋은 성능을 나타내며 SOTA를 달성하였습니다.
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Ablation Study
논문에서는 여러 조건을 바꾸어가며 추가적인 연구를 진행했습니다. 첫 번째로 BERT 모델의 사이즈를 바꾸어가며 성능을 평가하였습니다. $#L$은 인코더 블록의 개수이고 $#H$와 $#A$ 는 각각 임베딩 벡터 차원과 어텐션 헤드의 개수입니다. 아래 그림에서 4번째 행에 있는 모델이 BERT BASE이며 맨 아래에 있는 모델이 BERT LARGE입니다. 아래 표에서 모델의 사이즈를 늘릴 수록 성능이 좋아지는 것을 볼 수 있습니다.
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
논문의 저자들은 모델이 커지면 기계 번역이나 언어 모델과 같은 큰 사이즈의 태스크에 대해서는 이전부터 알려진 사실이지만, 크기가 작은 데이터셋에 대해서도 모델 사이즈를 키웠을 때 성능이 좋아짐을 확인할 수 있었던 사례임을 강조하고 있습니다.
두 번째로는 fine-tuning과 feature-based 방법에 대해 성능을 비교한 표입니다. fine-tuning은 pre-training 이후에 추가 학습 과정에서 단어 임베딩 벡터까지 업데이트 합니다. 하지만 feature-based은 단어 임베딩은 고정한 채 신경망 파라미터만 학습하는 방법입니다.
아래는 fine-tuning 과 다양한 feature-based 케이스에 대해서 모델의 성능을 비교한 표입니다. 실험 대상이 되는 모든 feature-based 모델보다 fine-tuning 모델이 좋은 성능을 보이는 것을 확인할 수 있습니다.
이미지 출처 : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
아래는 실험한 feature-based 케이스에 대해 결과를 잘 나타내주는 이미지입니다.
이미지 출처 : jalammar.github.io
Conclusion
BERT는 MLM과 NSP라는 특이한 pre-training 방법을 사용하여 이전 모델보다 월등한 성능을 보이며 SOTA를 달성하였습니다. 두 방법중 NSP는 이후 모델에서 삭제되기는 하지만 MLM은 문맥을 Bidirectional 학습할 수 있기 때문에 이후 모델에도 계속 사용됩니다. MLM 방법을 그대로 계승하여 BERT 개선하거나 경량화한 “RoBERTa, AlBERT…” 등이 나오게 되지요. BERT는 이러한 모델의 원조로서 자연어처리 분야의 큰 발전을 가져온 기념비적인 모델이라고 할 수 있습니다.
-
Transformer의 Positional Encoding 과는 다른 방법으로 만들어집니다. ↩
Comments