
GPT, GPT-2 (Generative Pre-Training of a language model)
05 Jul 2020 | NLP
본 포스트의 내용은 고려대학교 강필성 교수님의 강의 와 김기현의 자연어처리 딥러닝 캠프 , 밑바닥에서 시작하는 딥러닝 2 , 한국어 임베딩 책을 참고하였습니다.
GPT

이미지 출처 : openai.com
GPT(Generative Pre-Training of a Language Model)는 2018년 6월 OpenAI에서 “Improving Language Understanding by Generative Pre-Training” 논문을 통해서 발표한 모델입니다. GPT는 시간적으로 ELMo이후에 BERT보다는 전에 발표되었습니다. GPT의 기본이 되는 아이디어는 좋은 임베딩 표현을 강조했던 ELMo와 유사하다고 할 수 있습니다.
먼저 특정한 목적 태스크가 없는 대량의 자연어 데이터셋(Unlabeled corpora)을 언어 모델에 학습시킵니다. 이 과정을 Pre-training(사전 학습)이라고 합니다. pre-training을 마친 모델에 추가로 태스크에 맞는 데이터셋(Labeled corpora)을 추가 학습시킵니다. 이를 Fine-tuning이라고 합니다. GPT는 이러한 “전이 학습(Transfer learning) 방법으로 이전의 모델보다 태스크에 상관없이(Task-agnostic) 더 좋은 성능을 낼 수 있을 것이다”라는 아이디어에서 고안되었습니다.
Structure & Pre-training
GPT는 트랜스포머(Transformer)의 디코더 블록을 여러 겹 쌓아 만들어 언어 모델(Language models)에 적용하였습니다. 하지만 GPT의 디코더 블록은 트랜스포머의 디코더 블록과 완전히 동일한 구조를 가지고 있지는 않습니다. 트랜스포머에서는 디코더 블록 내에 총 3개의 서브레이어(Sub-layer)를 가지고 있었습니다. 각각 Masked Self-Attention, Encoder-Decoder Attention, Feed Forward Neural Network 였습니다.
하지만 GPT에서는 인코더를 사용하지 않으므로 Encoder-Decoder Attention 층을 필요로 하지 않습니다. 그래서 GPT의 디코더 블록 내부에는 2개의 서브레이어(Masked Self-Attention, FFNN)만 존재하게 됩니다. 아래는 GPT에서 사용된 트랜스포머의 디코더 구조를 나타낸 이미지입니다.
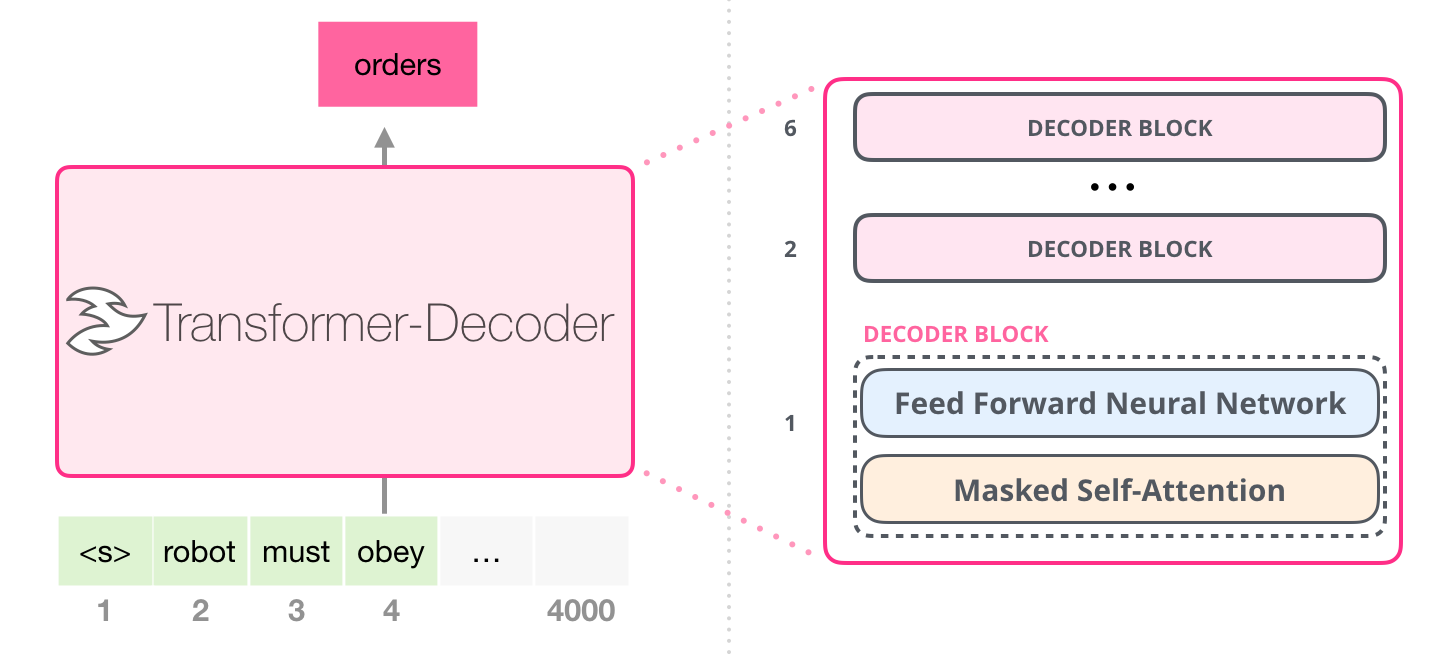
이미지 출처 : jalammar.github.io
pre-training은 레이블링되지 않은 말뭉치 $U = (u_1, u_2, \cdots ,u_n)$ 에 대하여 다음의 로그 우도를 $L_1$을 최대화 하는 과정으로 진행됩니다. 아래 수식에서 $k$는 윈도우의 사이즈이며, $\Theta$는 학습 파라미터입니다.
\[L_1(U) = \sum_i \log P(u_i \vert u_{i-k}, \cdots, u_{i-1};\Theta)\]
학습과정 역시 트랜스포머의 디코더와 유사합니다. 단어 임베딩 $W_e$와 포지셔널 인코딩 $W_p$를 사용하여 첫 번째 디코더에 들어갈 은닉벡터 $h_0$를 마련합니다. 그리고 $n$개의 디코더 블록을 통과시킨 뒤에 최종적으로 나오는 은닉 벡터 $h_n$을 마지막으로 소프트맥스로 통과시켜 각 토큰이 등장할 확률을 구하게 됩니다. 수식으로 나타내면 다음과 같습니다.
\[\begin{aligned}
h_0 &= UW_e + W_p \\
h_l &= \text{TransformerDecoderBlock}(h_{l-1}), \quad \forall i\in [1,n] \\
P(u) &= \text{Softmax}(h_nW_e^T)
\end{aligned}\]
Fine-Tuning
fine-tuning에서는 레이블링된 데이터셋 $C = (x_1, \cdots, x_m;y)$를 사용합니다. 각 입력된 데이터는 pre-trained 모델을 지나면서 레이블 $y$를 예측하는 방향으로 학습을 진행해나가게 됩니다. 로그 우도 $L_2$를 최대화 하는 과정입니다. 수식으로 나타내면 다음과 같습니다.
\[P(y|x_1, \cdots, x_m) = \text{softmax}(h_l^m W_y) \\
L_2(C) = \sum_{(x,y)} \log P(y|x_1, \cdots, x_m)\]
논문에서는 fine-tuning에서 $L_2$뿐만 아니라 $L_1$을 조합하여 사용합니다. 논문에서는 방법이 지도학습 모델의 일반화를 돕고 수렴 속도를 더 빠르게 하는 효과가 있다고 합니다. 아래의 식은 두 목적함수를 결합한 새로운 목적함수 $L_3$를 수식으로 나타낸 것입니다.
\[L_3(C) = L_2(C) + \lambda \times L_1(C)\]
fine-tuning 에서 GPT의 모델 구조는 동일하게 유지됩니다. 대신 태스크마다 다른(task-specific) 형태로 데이터셋을 입력해야 하지요. 아래는 태스크에 따라서 달라지는 데이터셋의 형태를 나타낸 이미지입니다.
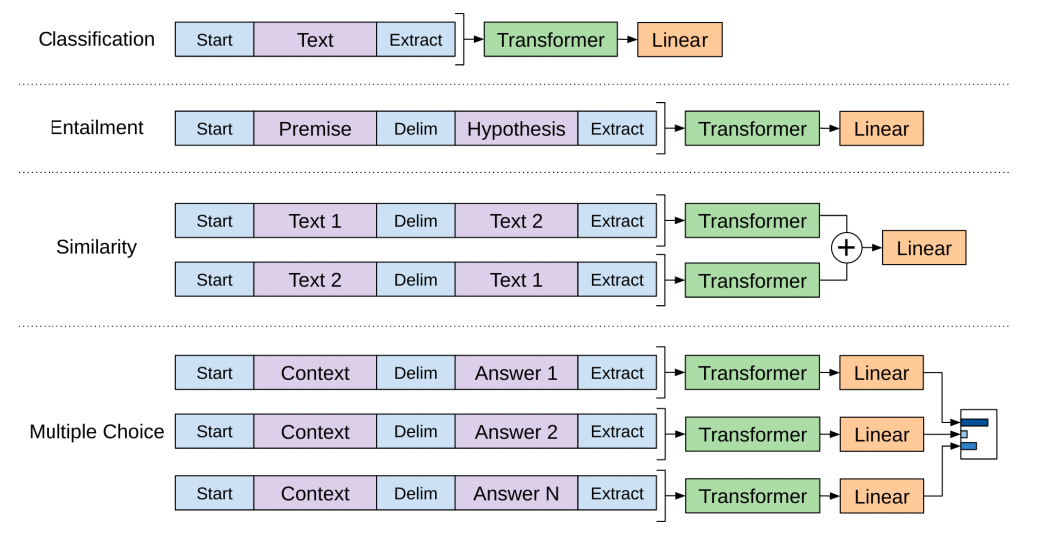
이미지 출처 : jalammar.github.io
먼저 분류(Classification)의 경우에는 별도의 구분자(Delim) 없이 텍스트 데이터를 넣습니다. 함의(Entailment)와 관련된 태스크는 전제(Premise)와 가설(Hypothesis)를 구분자로 나누어 입력합니다. 두 텍스트 간의 유사도(Similarity)를 파악하는 태스크는 두 텍스트를 구분자로 나누어 입력하되, 순서를 바꾼 데이터셋을 하나 더 구성하여 함께 입력하게 됩니다. 마지막으로 객관식(Multiple choice)와 관련된 태스크의 경우에는 N개 만큼의 세트를 만듭니다. 각 세트는 구분자를 기준으로 앞쪽에는 동일한 컨텍스트가 위치하고 뒤쪽은 각각의 Answer가 위치합니다. 모든 세트를 각각 다른 트랜스포머에 넣은 뒤 출력되는 벡터에 소프트맥스를 취해주어 최종 답안을 구합니다.
Evalution
논문에서는 지도학습 데이터셋을 사용하여 이전의 모델과 비교하였습니다. 대부분의 태스크에서 State-of-the-Art(SOTA) 를 달성하였습니다.



이미지 출처 : Improving Language Understanding by Generative Pre-Training
Ablation Study
논문에서는 이외에도 몇 가지 추가적인 연구를 수행하였습니다. 먼저 디코더 층의 개수를 변화시키면서 2개의 데이터셋(RACE, MultiNLI)에 대해 성능을 측정하였습니다. 아래 이미지의 왼쪽이 결과를 나타낸 그래프입니다. 층의 개수가 늘어나면서 성능이 늘어남을 확인할 수 있습니다. 전이 학습된 모든 디코더 층이 더 좋은 성능에 영향을 미치고 있는 것을 확인할 수 있습니다.
오른쪽은 4개의 태스크(감성 분석, 객관식, 문법, 질의응답)에 대하여 pre-training 만으로 어떤 성능을 보이는 지를 나타낸 그래프입니다. 그리고 LSTM을 활용하여 동일한 태스크에 대해 동일한 횟수만큼 pre-training한 후 성능을 비교하였습니다. 이 실험을 통해 모델의 휴리스틱(Heuristic)이 어떻게 변화하는 지를 평가하고 있습니다. pre-training 학습량이 늘어날수록 모델의 휴리스틱이 더 좋아지는 것을 볼 수 있습니다. 그리고 LSTM은 트랜스포머에 비해 Zero-shot 성능이 떨어짐을 확인할 수 있습니다.

이미지 출처 : Improving Language Understanding by Generative Pre-Training
아래는 여러 데이터셋에 대해 학습 방법이나 다른 학습 방법을 사용한 4가지 경우를 비교하고 있습니다. 첫 번째는 pre-training 이후 보조 손실($\lambda \times L_1$)을 활용하여 fine-tuning을 모두 수행한 모델입니다. 두 번째는 pre-training을 사용하지 않은 모델이고, 세 번째는 fine-tuning 과정에서 보조 손실을 사용하지 않은(only $L_2$) 모델입니다. 마지막은 다른 조건은 동일하되 트랜스포머 대신 2048개의 유닛을 사용한 LSTM 모델입니다.
먼저 pre-training을 하지 않은 모델은 모든 태스크에 대해 낮은 성능을 나타냅니다. LSTM 역시 하나의 데이터셋(MRPC)을 제외하고는 대부분의 태스크에서 트랜스포머에 비해 떨어지는 성능을 보여줍니다. 마지막으로 보조 손실을 사용한 모델(full)과 보조 손실을 적용하지 않은 모델을 비교해보겠습니다. 상대적으로 작은 데이터셋(CoLA, SST2, MRPC, STSB)에 대해서는 보조 손실을 적용하지 않은 모델이 오히려 더 좋은 성능을 보여줍니다. 하지만 일정 이상으로 커지게 되면 보조 함수를 적용한 데이터셋의 성능이 더 높아짐을 확인할 수 있습니다.

이미지 출처 : Improving Language Understanding by Generative Pre-Training
GPT-2
OpenAI는 GPT에 이어 2019년 2월 “Language Models are Unsupervised Multitask Learners” 라는 논문을 통해 GPT-2 모델을 발표하였습니다. 구조상으로는 이전에 발표했던 GPT와 별 차이가 없지만 더 많은 데이터를 통해서 Pre-training 되었다는 차이점을 가지고 있습니다. GPT-2의 Pre-training에는 무려 40GB정도의 말뭉치가 사용되었습니다.
모델의 크기에 따라 4개의 GPT-2 모델을 발표하였습니다. GPT-2 SMALL의 경우 파라미터의 개수가 1억 1700만(117M)개로 BERT BASE가 사용했던 110M과 비슷한 개수로 맞추어 발표하였습니다. GPT-2 MEDIUM은 3억 4500만(345M)으로 BERT LARGE의 파라미터 개수인 340M과 비슷한 개수로 맞추었지요. OpenAI는 이보다 더 큰 사이즈의 LARGE와 EXTRA LARGE 모델도 공개하였는데 각각 7억 6200만(762M)개, 15억 4200만(1542M)개의 파라미터를 가지고 있습니다. 아래는 GPT-2의 대략적인 크기를 잘 보여주는 이미지입니다.

이미지 출처 : jalammar.github.io
Structure
GPT-2의 구조는 GPT와 거의 유사합니다. GPT-2 SMALL은 12개의 디코더 블록을 쌓아올린 모델이며 임베딩 벡터의 차원 또한 BERT BASE와 동일한 768차원의 임베딩 벡터를 사용하고 있습니다. GPT-2 MEDIUM은 디코더 24개를 쌓아올렸으며 BERT LARGE와 같은 1024차원의 임베딩 벡터를 사용하였습니다. 나머지 GPT-2 LARGE와 EXTRA LARGE는 각각 36개, 48개의 디코더를 쌓아올렸으며 1280, 1600차원의 임베딩 벡터를 사용하였습니다. 아래는 각 모델마다 사용한 디코더 블록의 개수와 임베딩 벡터의 차원 수를 잘 보여주는 이미지입니다.
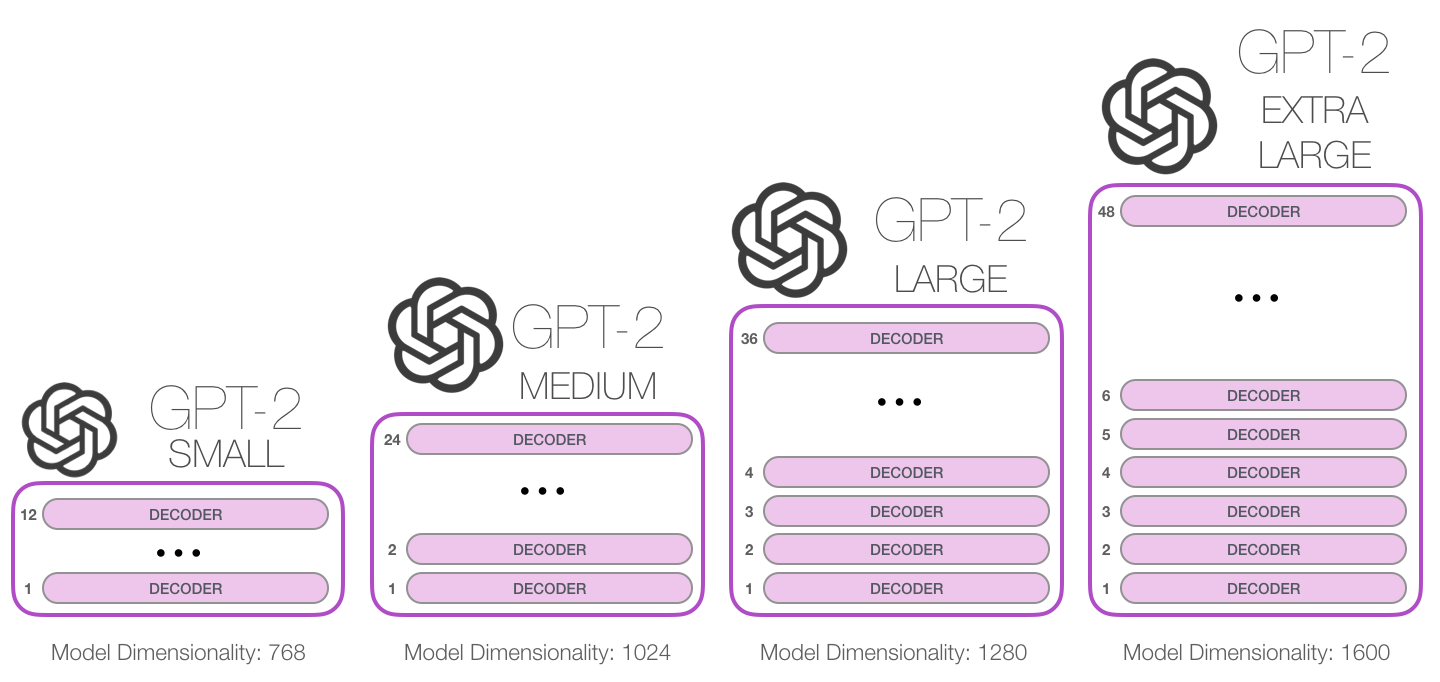
이미지 출처 : jalammar.github.io
GPT-2는 최대 1024개의 토큰을 입력받을 수 있으며 GPT-2는 특정 토큰이 생성될 때 항상 가장 확률이 높은 단어(Top word)만 선택되지 않도록 top_k 파라미터를 설정하여 샘플링 범위를 넓힐 수 있습니다. 이 파라미터를 조정하면 단어를 생성할 때 $k$개의 단어 보기 중에서 선택하게 되므로 $k$를 키울수록 모델이 다양한 문장을 생성하게 됩니다.
자기 회귀(Auto-regressive)적인 언어 모델 기반으로 작동하므로 이미 생성된 토큰이 다음 토큰의 생성 확률에 영향을 끼치게 됩니다.
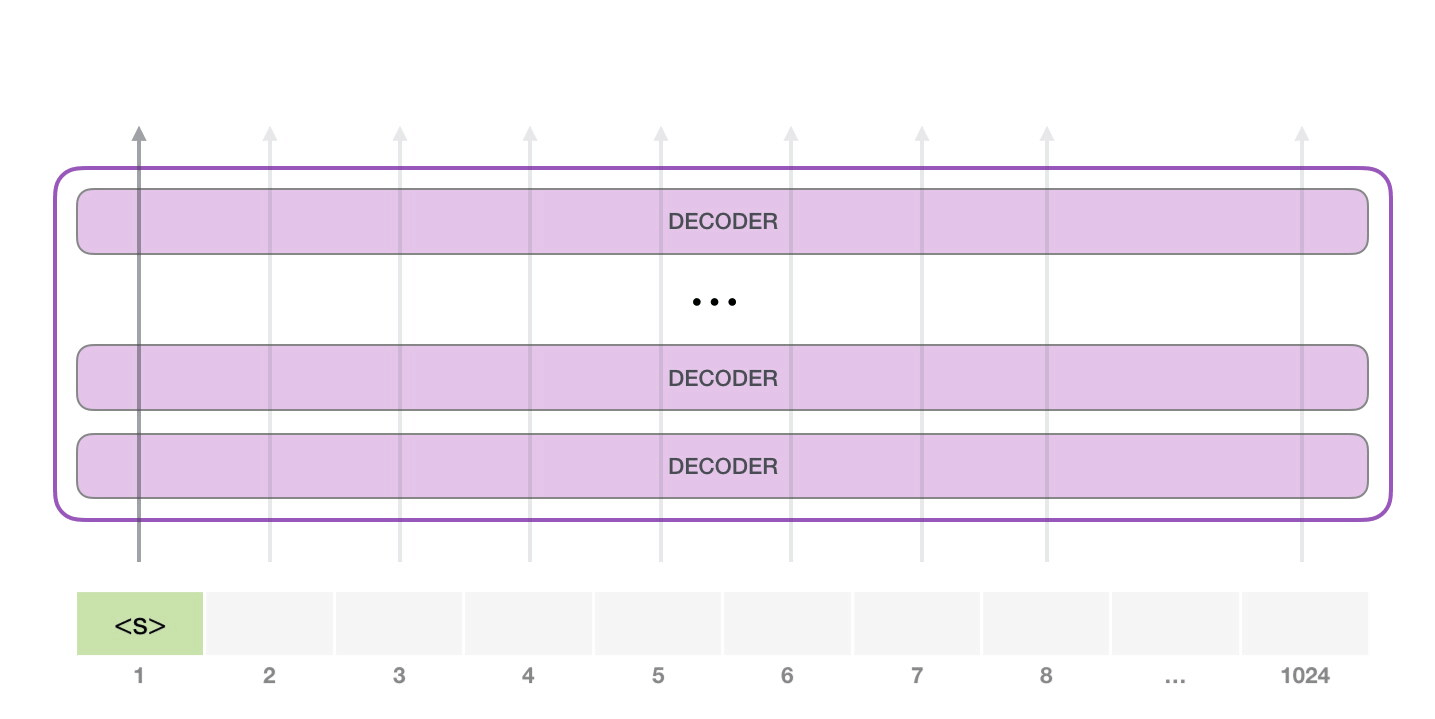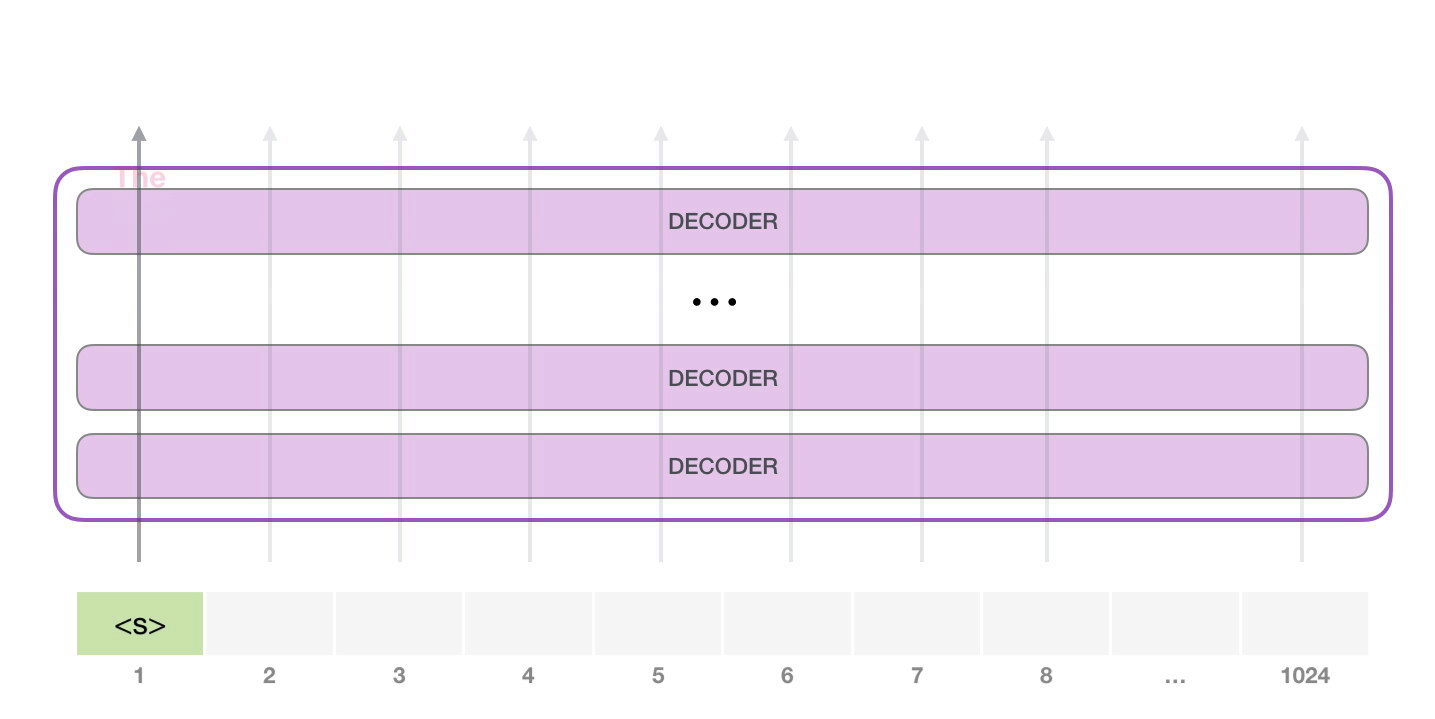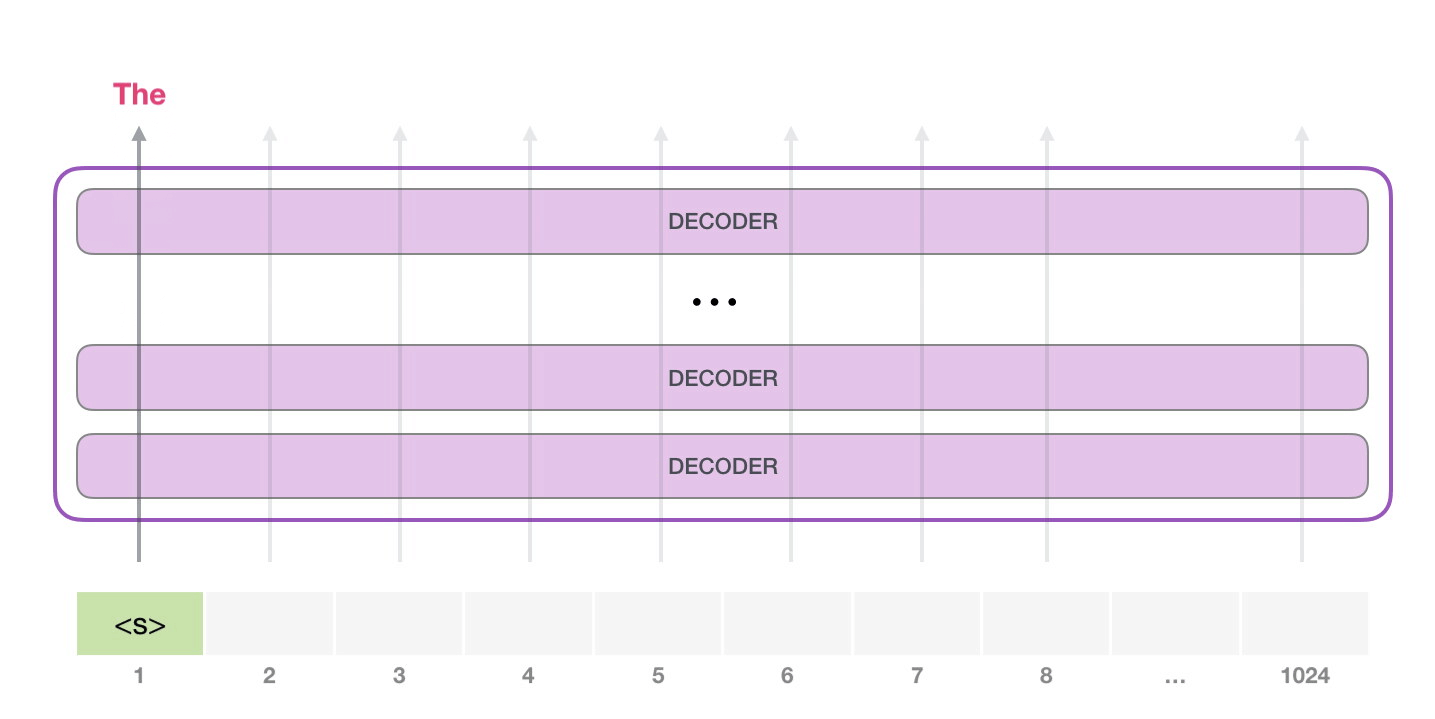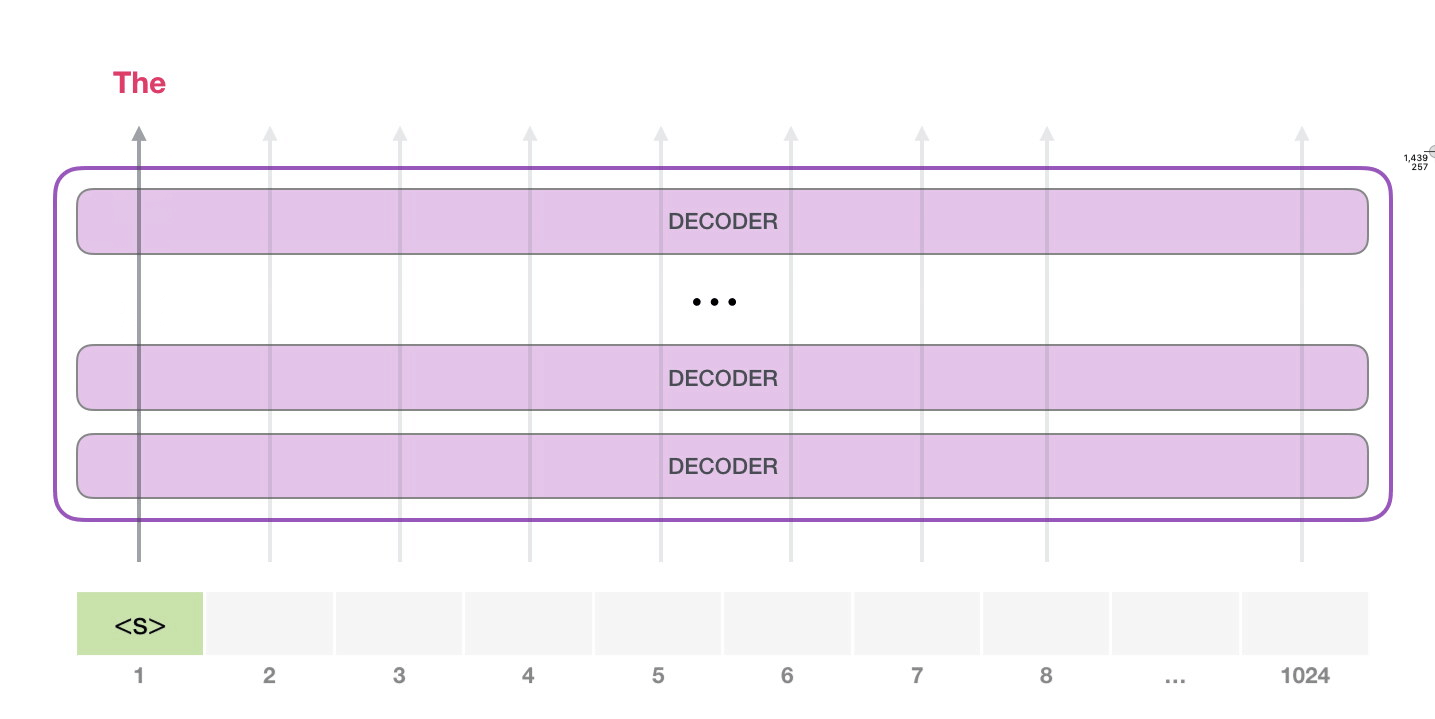
이미지 출처 : jalammar.github.io
전체 vocab 사이즈의 크기는 50,257개이며 단어 임베딩 사이즈는 모델에 맞게 사용합니다. 포지셔널 인코딩 역시 최대 처리할 수 있는 토큰 사이즈에 맞추어 1024개로 설정되어 있습니다. 이렇게 단어 임베딩과 포지셔널 인코딩 벡터를 더하여 모델에 입력하게 됩니다. 아래는 토큰 임베딩 벡터와 포지셔널 인코딩 벡터가 결합되어 모델에 입력된 후 출력 단어가 생성되는 과정을 나타낸 이미지입니다.
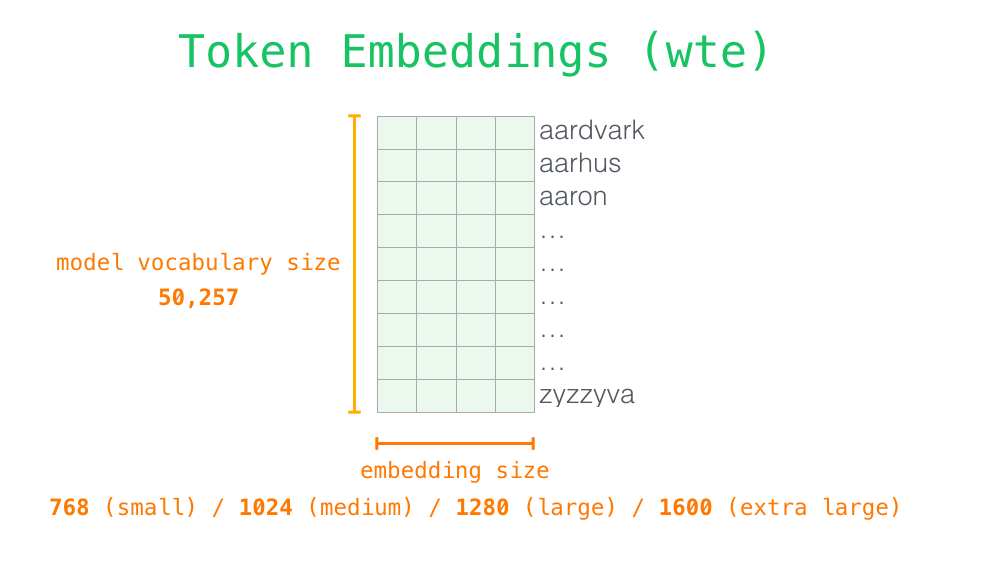
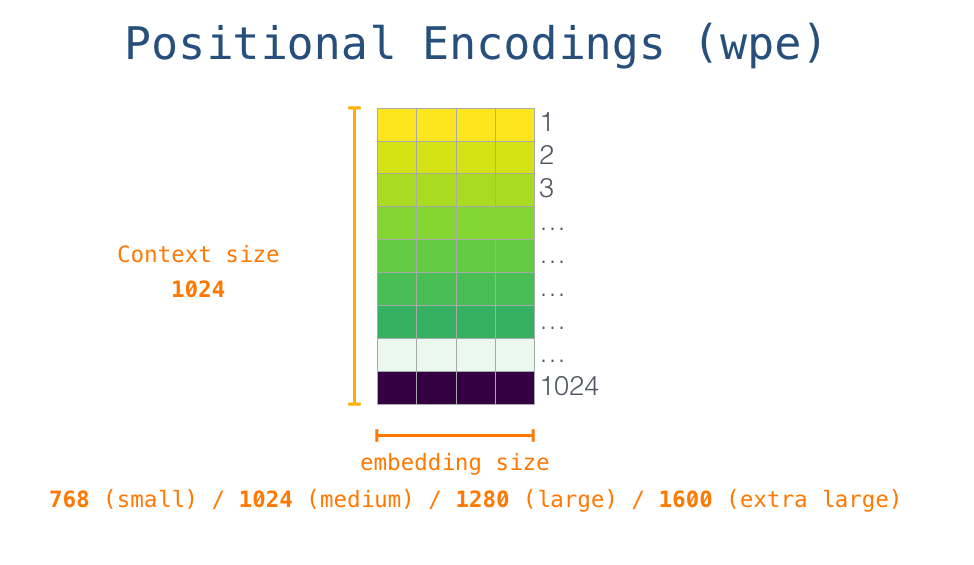

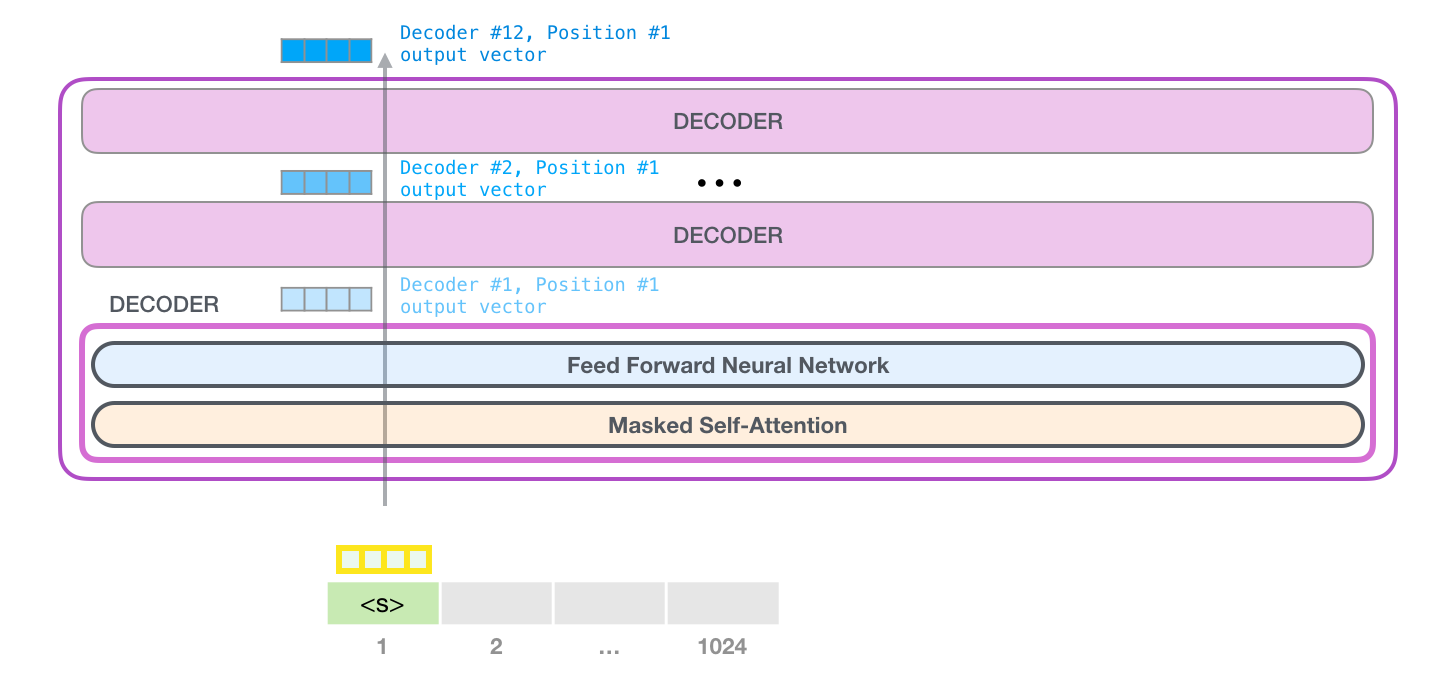
이미지 출처 : jalammar.github.io
GPT-2는 단어 토큰을 만들기 위해서 BPE(Byte pair encoding)을 사용합니다. 입력할 수 있는 최대 토큰의 개수는 1024개 이며 동시에 처리할 수 있는 토큰 수는 절반인 512개입니다.
Ablation Study
아래는 파라미터의 개수, 즉 모델의 사이즈에 따라 성능이 변하는 것을 관측한 그래프입니다. Perplexity(PPL)을 기준으로 측정하였으며 모델 사이즈가 커질수록 성능이 좋아지는 것을 알 수 있습니다.

이미지 출처 : Improving Language Understanding by Generative Pre-Training
아래는 지도학습 데이터셋에 대한 GPT-2의 성능을 측정한 것입니다. GPT-2 SMALL 모델만으로도 몇 가지 태스크에서 SOTA를 달성할 수 있었으며 가장 사이즈가 큰 EXTRA LARGE 모델의 경우 한 가지 데이터셋을 제외하고는 SOTA를 달성한 것을 볼 수 있습니다.

이미지 출처 : Improving Language Understanding by Generative Pre-Training
Post BERT, GPT-2
ELMo, GPT, BERT, GPT-2 이후에도 아래 그림과 같이 수많은 모델이 나오고 있습니다.

이미지 출처 : Text Analytics 강의자료
아래 그림을 보면 T-NLG가 발;표된 시점까지 파라미터의 개수, 즉 모델의 사이즈가 기하급수적으로 늘고 있는 것을 볼 수 있습니다. 심지어 GPT-2에 이어 2020년 6월에 OpenAI가 발표한 GPT-3에는 약 1750억(175B)개의 파라미터가 사용되었습니다. 이는 그래프에 있는 T-NLG보다도 10배나 많은 파라미터가 사용된 것으로 자연어처리 모델의 스케일이 얼마나 빠르게 커지고 있는 지를 보여주는 사례라고 할 수 있습니다.

이미지 출처 : Text-Analytics Github
본 포스트의 내용은 고려대학교 강필성 교수님의 강의 와 김기현의 자연어처리 딥러닝 캠프 , 밑바닥에서 시작하는 딥러닝 2 , 한국어 임베딩 책을 참고하였습니다.
GPT
이미지 출처 : openai.com
GPT(Generative Pre-Training of a Language Model)는 2018년 6월 OpenAI에서 “Improving Language Understanding by Generative Pre-Training” 논문을 통해서 발표한 모델입니다. GPT는 시간적으로 ELMo이후에 BERT보다는 전에 발표되었습니다. GPT의 기본이 되는 아이디어는 좋은 임베딩 표현을 강조했던 ELMo와 유사하다고 할 수 있습니다.
먼저 특정한 목적 태스크가 없는 대량의 자연어 데이터셋(Unlabeled corpora)을 언어 모델에 학습시킵니다. 이 과정을 Pre-training(사전 학습)이라고 합니다. pre-training을 마친 모델에 추가로 태스크에 맞는 데이터셋(Labeled corpora)을 추가 학습시킵니다. 이를 Fine-tuning이라고 합니다. GPT는 이러한 “전이 학습(Transfer learning) 방법으로 이전의 모델보다 태스크에 상관없이(Task-agnostic) 더 좋은 성능을 낼 수 있을 것이다”라는 아이디어에서 고안되었습니다.
Structure & Pre-training
GPT는 트랜스포머(Transformer)의 디코더 블록을 여러 겹 쌓아 만들어 언어 모델(Language models)에 적용하였습니다. 하지만 GPT의 디코더 블록은 트랜스포머의 디코더 블록과 완전히 동일한 구조를 가지고 있지는 않습니다. 트랜스포머에서는 디코더 블록 내에 총 3개의 서브레이어(Sub-layer)를 가지고 있었습니다. 각각 Masked Self-Attention, Encoder-Decoder Attention, Feed Forward Neural Network 였습니다.
하지만 GPT에서는 인코더를 사용하지 않으므로 Encoder-Decoder Attention 층을 필요로 하지 않습니다. 그래서 GPT의 디코더 블록 내부에는 2개의 서브레이어(Masked Self-Attention, FFNN)만 존재하게 됩니다. 아래는 GPT에서 사용된 트랜스포머의 디코더 구조를 나타낸 이미지입니다.
이미지 출처 : jalammar.github.io
pre-training은 레이블링되지 않은 말뭉치 $U = (u_1, u_2, \cdots ,u_n)$ 에 대하여 다음의 로그 우도를 $L_1$을 최대화 하는 과정으로 진행됩니다. 아래 수식에서 $k$는 윈도우의 사이즈이며, $\Theta$는 학습 파라미터입니다.
\[L_1(U) = \sum_i \log P(u_i \vert u_{i-k}, \cdots, u_{i-1};\Theta)\]학습과정 역시 트랜스포머의 디코더와 유사합니다. 단어 임베딩 $W_e$와 포지셔널 인코딩 $W_p$를 사용하여 첫 번째 디코더에 들어갈 은닉벡터 $h_0$를 마련합니다. 그리고 $n$개의 디코더 블록을 통과시킨 뒤에 최종적으로 나오는 은닉 벡터 $h_n$을 마지막으로 소프트맥스로 통과시켜 각 토큰이 등장할 확률을 구하게 됩니다. 수식으로 나타내면 다음과 같습니다.
\[\begin{aligned} h_0 &= UW_e + W_p \\ h_l &= \text{TransformerDecoderBlock}(h_{l-1}), \quad \forall i\in [1,n] \\ P(u) &= \text{Softmax}(h_nW_e^T) \end{aligned}\]Fine-Tuning
fine-tuning에서는 레이블링된 데이터셋 $C = (x_1, \cdots, x_m;y)$를 사용합니다. 각 입력된 데이터는 pre-trained 모델을 지나면서 레이블 $y$를 예측하는 방향으로 학습을 진행해나가게 됩니다. 로그 우도 $L_2$를 최대화 하는 과정입니다. 수식으로 나타내면 다음과 같습니다.
\[P(y|x_1, \cdots, x_m) = \text{softmax}(h_l^m W_y) \\ L_2(C) = \sum_{(x,y)} \log P(y|x_1, \cdots, x_m)\]논문에서는 fine-tuning에서 $L_2$뿐만 아니라 $L_1$을 조합하여 사용합니다. 논문에서는 방법이 지도학습 모델의 일반화를 돕고 수렴 속도를 더 빠르게 하는 효과가 있다고 합니다. 아래의 식은 두 목적함수를 결합한 새로운 목적함수 $L_3$를 수식으로 나타낸 것입니다.
\[L_3(C) = L_2(C) + \lambda \times L_1(C)\]fine-tuning 에서 GPT의 모델 구조는 동일하게 유지됩니다. 대신 태스크마다 다른(task-specific) 형태로 데이터셋을 입력해야 하지요. 아래는 태스크에 따라서 달라지는 데이터셋의 형태를 나타낸 이미지입니다.
이미지 출처 : jalammar.github.io
먼저 분류(Classification)의 경우에는 별도의 구분자(Delim) 없이 텍스트 데이터를 넣습니다. 함의(Entailment)와 관련된 태스크는 전제(Premise)와 가설(Hypothesis)를 구분자로 나누어 입력합니다. 두 텍스트 간의 유사도(Similarity)를 파악하는 태스크는 두 텍스트를 구분자로 나누어 입력하되, 순서를 바꾼 데이터셋을 하나 더 구성하여 함께 입력하게 됩니다. 마지막으로 객관식(Multiple choice)와 관련된 태스크의 경우에는 N개 만큼의 세트를 만듭니다. 각 세트는 구분자를 기준으로 앞쪽에는 동일한 컨텍스트가 위치하고 뒤쪽은 각각의 Answer가 위치합니다. 모든 세트를 각각 다른 트랜스포머에 넣은 뒤 출력되는 벡터에 소프트맥스를 취해주어 최종 답안을 구합니다.
Evalution
논문에서는 지도학습 데이터셋을 사용하여 이전의 모델과 비교하였습니다. 대부분의 태스크에서 State-of-the-Art(SOTA) 를 달성하였습니다.
이미지 출처 : Improving Language Understanding by Generative Pre-Training
Ablation Study
논문에서는 이외에도 몇 가지 추가적인 연구를 수행하였습니다. 먼저 디코더 층의 개수를 변화시키면서 2개의 데이터셋(RACE, MultiNLI)에 대해 성능을 측정하였습니다. 아래 이미지의 왼쪽이 결과를 나타낸 그래프입니다. 층의 개수가 늘어나면서 성능이 늘어남을 확인할 수 있습니다. 전이 학습된 모든 디코더 층이 더 좋은 성능에 영향을 미치고 있는 것을 확인할 수 있습니다.
오른쪽은 4개의 태스크(감성 분석, 객관식, 문법, 질의응답)에 대하여 pre-training 만으로 어떤 성능을 보이는 지를 나타낸 그래프입니다. 그리고 LSTM을 활용하여 동일한 태스크에 대해 동일한 횟수만큼 pre-training한 후 성능을 비교하였습니다. 이 실험을 통해 모델의 휴리스틱(Heuristic)이 어떻게 변화하는 지를 평가하고 있습니다. pre-training 학습량이 늘어날수록 모델의 휴리스틱이 더 좋아지는 것을 볼 수 있습니다. 그리고 LSTM은 트랜스포머에 비해 Zero-shot 성능이 떨어짐을 확인할 수 있습니다.
이미지 출처 : Improving Language Understanding by Generative Pre-Training
아래는 여러 데이터셋에 대해 학습 방법이나 다른 학습 방법을 사용한 4가지 경우를 비교하고 있습니다. 첫 번째는 pre-training 이후 보조 손실($\lambda \times L_1$)을 활용하여 fine-tuning을 모두 수행한 모델입니다. 두 번째는 pre-training을 사용하지 않은 모델이고, 세 번째는 fine-tuning 과정에서 보조 손실을 사용하지 않은(only $L_2$) 모델입니다. 마지막은 다른 조건은 동일하되 트랜스포머 대신 2048개의 유닛을 사용한 LSTM 모델입니다.
먼저 pre-training을 하지 않은 모델은 모든 태스크에 대해 낮은 성능을 나타냅니다. LSTM 역시 하나의 데이터셋(MRPC)을 제외하고는 대부분의 태스크에서 트랜스포머에 비해 떨어지는 성능을 보여줍니다. 마지막으로 보조 손실을 사용한 모델(full)과 보조 손실을 적용하지 않은 모델을 비교해보겠습니다. 상대적으로 작은 데이터셋(CoLA, SST2, MRPC, STSB)에 대해서는 보조 손실을 적용하지 않은 모델이 오히려 더 좋은 성능을 보여줍니다. 하지만 일정 이상으로 커지게 되면 보조 함수를 적용한 데이터셋의 성능이 더 높아짐을 확인할 수 있습니다.
이미지 출처 : Improving Language Understanding by Generative Pre-Training
GPT-2
OpenAI는 GPT에 이어 2019년 2월 “Language Models are Unsupervised Multitask Learners” 라는 논문을 통해 GPT-2 모델을 발표하였습니다. 구조상으로는 이전에 발표했던 GPT와 별 차이가 없지만 더 많은 데이터를 통해서 Pre-training 되었다는 차이점을 가지고 있습니다. GPT-2의 Pre-training에는 무려 40GB정도의 말뭉치가 사용되었습니다.
모델의 크기에 따라 4개의 GPT-2 모델을 발표하였습니다. GPT-2 SMALL의 경우 파라미터의 개수가 1억 1700만(117M)개로 BERT BASE가 사용했던 110M과 비슷한 개수로 맞추어 발표하였습니다. GPT-2 MEDIUM은 3억 4500만(345M)으로 BERT LARGE의 파라미터 개수인 340M과 비슷한 개수로 맞추었지요. OpenAI는 이보다 더 큰 사이즈의 LARGE와 EXTRA LARGE 모델도 공개하였는데 각각 7억 6200만(762M)개, 15억 4200만(1542M)개의 파라미터를 가지고 있습니다. 아래는 GPT-2의 대략적인 크기를 잘 보여주는 이미지입니다.
이미지 출처 : jalammar.github.io
Structure
GPT-2의 구조는 GPT와 거의 유사합니다. GPT-2 SMALL은 12개의 디코더 블록을 쌓아올린 모델이며 임베딩 벡터의 차원 또한 BERT BASE와 동일한 768차원의 임베딩 벡터를 사용하고 있습니다. GPT-2 MEDIUM은 디코더 24개를 쌓아올렸으며 BERT LARGE와 같은 1024차원의 임베딩 벡터를 사용하였습니다. 나머지 GPT-2 LARGE와 EXTRA LARGE는 각각 36개, 48개의 디코더를 쌓아올렸으며 1280, 1600차원의 임베딩 벡터를 사용하였습니다. 아래는 각 모델마다 사용한 디코더 블록의 개수와 임베딩 벡터의 차원 수를 잘 보여주는 이미지입니다.
이미지 출처 : jalammar.github.io
GPT-2는 최대 1024개의 토큰을 입력받을 수 있으며 GPT-2는 특정 토큰이 생성될 때 항상 가장 확률이 높은 단어(Top word)만 선택되지 않도록 top_k 파라미터를 설정하여 샘플링 범위를 넓힐 수 있습니다. 이 파라미터를 조정하면 단어를 생성할 때 $k$개의 단어 보기 중에서 선택하게 되므로 $k$를 키울수록 모델이 다양한 문장을 생성하게 됩니다.
자기 회귀(Auto-regressive)적인 언어 모델 기반으로 작동하므로 이미 생성된 토큰이 다음 토큰의 생성 확률에 영향을 끼치게 됩니다.
이미지 출처 : jalammar.github.io
전체 vocab 사이즈의 크기는 50,257개이며 단어 임베딩 사이즈는 모델에 맞게 사용합니다. 포지셔널 인코딩 역시 최대 처리할 수 있는 토큰 사이즈에 맞추어 1024개로 설정되어 있습니다. 이렇게 단어 임베딩과 포지셔널 인코딩 벡터를 더하여 모델에 입력하게 됩니다. 아래는 토큰 임베딩 벡터와 포지셔널 인코딩 벡터가 결합되어 모델에 입력된 후 출력 단어가 생성되는 과정을 나타낸 이미지입니다.
이미지 출처 : jalammar.github.io
GPT-2는 단어 토큰을 만들기 위해서 BPE(Byte pair encoding)을 사용합니다. 입력할 수 있는 최대 토큰의 개수는 1024개 이며 동시에 처리할 수 있는 토큰 수는 절반인 512개입니다.
Ablation Study
아래는 파라미터의 개수, 즉 모델의 사이즈에 따라 성능이 변하는 것을 관측한 그래프입니다. Perplexity(PPL)을 기준으로 측정하였으며 모델 사이즈가 커질수록 성능이 좋아지는 것을 알 수 있습니다.
이미지 출처 : Improving Language Understanding by Generative Pre-Training
아래는 지도학습 데이터셋에 대한 GPT-2의 성능을 측정한 것입니다. GPT-2 SMALL 모델만으로도 몇 가지 태스크에서 SOTA를 달성할 수 있었으며 가장 사이즈가 큰 EXTRA LARGE 모델의 경우 한 가지 데이터셋을 제외하고는 SOTA를 달성한 것을 볼 수 있습니다.
이미지 출처 : Improving Language Understanding by Generative Pre-Training
Post BERT, GPT-2
ELMo, GPT, BERT, GPT-2 이후에도 아래 그림과 같이 수많은 모델이 나오고 있습니다.
이미지 출처 : Text Analytics 강의자료
아래 그림을 보면 T-NLG가 발;표된 시점까지 파라미터의 개수, 즉 모델의 사이즈가 기하급수적으로 늘고 있는 것을 볼 수 있습니다. 심지어 GPT-2에 이어 2020년 6월에 OpenAI가 발표한 GPT-3에는 약 1750억(175B)개의 파라미터가 사용되었습니다. 이는 그래프에 있는 T-NLG보다도 10배나 많은 파라미터가 사용된 것으로 자연어처리 모델의 스케일이 얼마나 빠르게 커지고 있는 지를 보여주는 사례라고 할 수 있습니다.
이미지 출처 : Text-Analytics Github
Comments