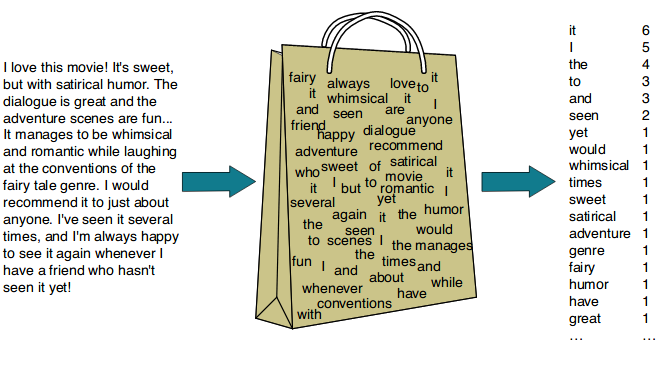
TF-IDF (Term Frequency - Inverse Document Frequency)
16 May 2020 | NLP
본 포스트의 내용은 고려대학교 강필성 교수님의 강의 와 김기현의 자연어처리 딥러닝 캠프 , 밑바닥에서 시작하는 딥러닝 2 , 한국어 임베딩 , 자연어 처리 인 액션 책을 참고하였습니다.
TF-IDF
우리는 살면서 일어나는 많은 일을 동일한 우선순위에서 대하지 않습니다. 아래는 “IT기업에 고용된 개발자의 뇌 구조” 라는 제목의 이미지입니다. 설명을 돕기 위한 이미지일 뿐이니 진지하게 받아들이실 필요는 없습니다. 잠시 아래의 이미지를 보고 설명을 이어가도록 하겠습니다.

이미지 출처 : newstars.tistory.com
위 그림에서도 알 수 있듯 개인에 따라 어떤 일을 대단히 중요하게 여겨지기도 하고, 어떤 일은 별로 중요치 않게 여기기도 합니다. 이를 자연어처리로도 그대로 가져올 수 있습니다. 문서 내에 있는 단어 중 어떤 단어는 굉장히 중요한 단어이고, 어떤 단어는 별로 중요치 않은 단어일 수 있습니다. 이번에 알아볼 TF-IDF는 더 중요하다고 생각되는 단어에 가중치는 부여하는 방법입니다.
TF-IDF(Term Frequency - Inverse Document Frequency) 는 우리가 이전에 알아본 Bag of Words 를 발전시킨 방법입니다. TF-IDF의 이름에서부터 알 수 있듯 가중치를 결정하는 두 가지 중요한 수치(Metric)가 있습니다. 첫 번째 알아볼 수치는 문서별 단어 빈도(Term frequency, TF) 입니다. 이 수치는 특정 문서에 등장하는 단어의 빈도를 나타냅니다. 이는 Bag of Words 에서 보았던 단어-문서 행렬의 빈도 표현과 같습니다. 문서별 단어 빈도를 측정하는 이유는 “해당 문서에 더 많이 등장하는 단어일수록 그 단어가 문서에서 차지하는 중요도가 커질 것”이라는 가정 때문입니다.
나머지 수치 하나는 단어별 문서 빈도(Document Frequency, DF) 입니다. DF는 특정 단어가 말뭉치 내에 있는 전체 문서 중 몇 개의 문서에 등장했는지를 나타내는 수치입니다. 단어 가중치에서 DF를 고려하는 이유는 무엇일까요? 처음에 뇌구조를 생각했던 것처럼 잠시 자연어처리를 벗어난 다른 주제로부터 DF가 중요한 이유를 알아보도록 합시다. 아래는 한 블로그에 올라온 점심 식단표입니다. (정확히는 훈련소 식단을 복원한 거라고 합니다.)

이미지 출처 : 네이버 블로그
위와 같은 식단표가 있다고 해봅시다. 4주차 목요일에 누군가가 “오늘 점심 메뉴 뭐야?” 라고 물었을 때 메뉴 하나만 대답한다면 일반적인 대답은 “돈까스” 혹은 “부대찌개” 정도일 것입니다. “밥” 혹은 “우유” 도 이들과 같이 점심 메뉴로 나오겠지만 이런 대답은 질문자가 원하는 것은 아니겠지요. “밥” 과 “우유” 가 좋지 않은 대답인 이유는 무엇일까요? 그렇습니다. 다른 날 점심에도 매번 “밥” 과 “우유” 가 나오는데 이게 “오늘 점심” 메뉴에선 별로 중요하지 않기 때문이죠. 각 식단을 하나의 문서로, 메뉴를 단어로 그대로 옮겨 적용해봅시다. 문서 속에서 “밥” 과 “우유” 에 해당하는 단어는 어떤 것들이 있을까요?
영어에서는 [“is”, “can”, “the”] 같은 단어들이 이런 범주에 속합니다. 한글에서도 형태소 분석후 나오는 [‘의’,’가’,’이’,’은’,’들’] 등의 단어는 모든 문서에 등장합니다. 이렇게 과하게 많이 등장하는 단어는 불용어(Stop word)로 지정하여 분석 대상에서 제외하기도 합니다. 모든 문서에 자주 등장하지만 문서 입장에서 보면 크게 의미있는 단어는 아니기 때문입니다. 이런 불용어를 제거하고 난 다음에도 분석할 문서들에 자주 등장하는 단어들은 낮은 가중치를 주어야 할 것입니다.
결론적으로 모든 문서에 자주 등장하는, 즉 단어별 문서 빈도(DF)가 높은 단어는 낮은 가중치를 주어야 합니다. 그렇기 때문에 실제로는 DF의 수치에 역수를 해준 뒤 로그를 취한 수치인 IDF(Inverse Document Frequency) 를 사용합니다. 일반적으로 IDF에 로그를 취하는 이유는 단어의 출현 빈도가 지프의 법칙1을 따르기 때문입니다.
오늘의 목표인 TF-IDF는 이 두 수치를 곱한 것입니다. 이렇게 구해진 TF-IDF는 특정 단어(Term)가 해당 문서(Document)에 얼마나 중요한지를 나타내는 가중치가 됩니다. 수식으로 나타내면 다음과 같습니다.
[\text{TF-IDF(w)} = \text{TF(w)} \times \log_{10} \frac{N}{\text{DF(w)}}]
아래는 실제 4개의 문서(이코노미스트 칼럼 번역 자료)를 형태소 분석 후 문서-단어 행렬(DTM)을 만든 후 문서에 등장하는 일부 단어들의 TF를 기록한 것입니다. 가장 오른쪽 열에는 구해진 TF로부터 DF까지 기록하였습니다. (예시를 돕기 위해서 극적인 사례를 선택하였습니다.) 아래 표를 보며 TF-IDF를 더 잘 이해해봅시다.
DTM
문서1 (석유 관련)
문서2 (부동산 관련)
문서3 (콘텐츠 관련)
문서4 (기후 관련)
DF
유가
27
0
0
0
1
원유
19
0
1
0
2
부동산
0
48
0
0
1
주택
0
38
0
0
1
콘텐츠
0
0
35
0
1
넷플릭스
0
0
35
0
1
기후
0
1
0
38
2
탄소
0
0
0
26
1
퍼센트
19
21
8
4
4
달러
24
21
26
14
4
미국
9
25
14
3
4
시장
4
28
22
6
4
위에서 각 단어를 위에서부터 분석해봅시다. 분석에 사용된 12개의 단어 중 “유가”, “원유” 는 석유와 관련된 칼럼에, “부동산”, “주택” 은 부동산과 관련된 칼럼에, “콘텐츠”, “넷플릭스” 는 콘텐츠와 관련된 칼럼에, “기후”, “탄소” 는 기후과 관련된 칼럼에 집중되어 있는 것을 알 수 있습니다. 이 중 “원유” 와 “기후” 는 다른 문서에도 한 번씩 등장했네요. 나머지 네 단어인 “퍼센트”, “달러”, “미국”, “시장” 을 분석한 결과 이 단어들은 모든 문서에서 고르게 1번 이상 등장하고 있는 것을 알 수 있습니다. 심지어 석유와 관련된 문서1에서 “퍼센트” 라는 단어는 “원유” 라는 단어만큼 등장했습니다. 하지만 과연 문서1에서 “퍼센트” 라는 단어가 “달러” 라는 단어만큼 중요할까요? 답은 TF-IDF가 알려줄 것입니다. 아래는 위 표를 기반으로 문서별 단어의 TF-IDF를 구한 표입니다.
DTM
문서1 (석유 관련)
문서2 (부동산 관련)
문서3 (콘텐츠 관련)
문서4 (기후 관련)
IDF
유가
16.26
0
0
0
$2\log2$
원유
5.72
0
0.30
0
$\log2$
부동산
0
28.90
0
0
$2\log2$
주택
0
22.88
0
0
$2 \log2$
콘텐츠
0
0
21.07
0
$2 \log2$
넷플릭스
0
0
21.07
0
$2 \log2$
기후
0
0.30
0
11.44
$\log2$
탄소
0
0
0
15.65
$2 \log2$
퍼센트
0
0
0
0
$\log1$
달러
0
0
0
0
$\log1$
미국
0
0
0
0
$\log1$
시장
0
0
0
0
$\log1$
위 표를 보면 아래 모든 문서에 등장하는 “퍼센트”, “달러”, “미국”, “시장” 의 TF-IDF는 0이 되었음을 알 수 있습니다. 이렇게 TF-IDF를 사용하면 한 문서에 자주 등장하는 단어에 대해서 중요도를 높일 수 있으면서도, 그 단어가 분석하려는 말뭉치 속 문서들에 골고루 등장할 경우 중요도를 낮추는 효과를 줄 수 있습니다.
다양한 TF-IDF 측정 방식과 활용
처음 TF-IDF라는 가중치 부여 방법이 고안되고 시간이 지나면서 이를 보정하기 위한 다양한 측정 방법이 생겨났습니다. 아래는 TF와 IDF를 측정하기 위한 다양한 방법을 담은 이미지입니다.


이미지 출처 :
Information Retrieval Models
이들 중 가장 좋은 성능을 보이는 절대적인 방법이 있는 것은 아닙니다. 분석할 말뭉치나 TF-IDF를 적용할 태스크에 따라 가장 적절한 방법이 달라집니다. 아래는 일반적으로 가장 많이 사용되는 TF-IDF 방식을 나타낸 것입니다.

이미지 출처 :
Information Retrieval Models
TF-IDF는 자연어처리 외에도 추천 시스템(Recommendation system) 등 다양한 분야에서 활용되고 있습니다. 이를 테면, 콘텐츠와 사용자간 행렬을 구성한 뒤 해당 콘텐츠가 특정 집단의 사용자에게 얼마나 중요한지에 대한 가중치를 부여하는 태스크 등에 사용됩니다.
-
“지프의 법칙에 따르면 어떠한 자연어 말뭉치 표현에 나타나는 단어들을 그 사용 빈도가 높은 순서대로 나열하였을 때, 모든 단어의 사용 빈도는 해당 단어의 순위에 반비례한다. 따라서 가장 사용 빈도가 높은 단어는 두 번째 단어보다 빈도가 약 두 배 높으며, 세 번째 단어보다는 빈도가 세 배 높다. 예를 들어, 브라운 대학교 현대 미국 영어 표준 말뭉치의 경우, 가장 사용 빈도가 높은 단어는 영어 정관사 “the”이며 전체 문서에서 7%의 빈도(약 백만 개 남짓의 전체 사용 단어 중 69,971회)를 차지한다. 두 번째로 사용 빈도가 높은 단어는 “of”로 약 3.5% 남짓(36,411회)한 빈도를 차지하며, 세 번째로 사용 빈도가 높은 단어는 “and”(28,852회)로, 지프의 법칙에 정확히 들어 맞는다. 약 135개 항목의 어휘만으로 브라운 대학 말뭉치의 절반을 나타낼 수 있다.” -위키피디아 : 지프의 법칙(Zipf’s law) ↩
본 포스트의 내용은 고려대학교 강필성 교수님의 강의 와 김기현의 자연어처리 딥러닝 캠프 , 밑바닥에서 시작하는 딥러닝 2 , 한국어 임베딩 , 자연어 처리 인 액션 책을 참고하였습니다.
TF-IDF
우리는 살면서 일어나는 많은 일을 동일한 우선순위에서 대하지 않습니다. 아래는 “IT기업에 고용된 개발자의 뇌 구조” 라는 제목의 이미지입니다. 설명을 돕기 위한 이미지일 뿐이니 진지하게 받아들이실 필요는 없습니다. 잠시 아래의 이미지를 보고 설명을 이어가도록 하겠습니다.
이미지 출처 : newstars.tistory.com
위 그림에서도 알 수 있듯 개인에 따라 어떤 일을 대단히 중요하게 여겨지기도 하고, 어떤 일은 별로 중요치 않게 여기기도 합니다. 이를 자연어처리로도 그대로 가져올 수 있습니다. 문서 내에 있는 단어 중 어떤 단어는 굉장히 중요한 단어이고, 어떤 단어는 별로 중요치 않은 단어일 수 있습니다. 이번에 알아볼 TF-IDF는 더 중요하다고 생각되는 단어에 가중치는 부여하는 방법입니다.
TF-IDF(Term Frequency - Inverse Document Frequency) 는 우리가 이전에 알아본 Bag of Words 를 발전시킨 방법입니다. TF-IDF의 이름에서부터 알 수 있듯 가중치를 결정하는 두 가지 중요한 수치(Metric)가 있습니다. 첫 번째 알아볼 수치는 문서별 단어 빈도(Term frequency, TF) 입니다. 이 수치는 특정 문서에 등장하는 단어의 빈도를 나타냅니다. 이는 Bag of Words 에서 보았던 단어-문서 행렬의 빈도 표현과 같습니다. 문서별 단어 빈도를 측정하는 이유는 “해당 문서에 더 많이 등장하는 단어일수록 그 단어가 문서에서 차지하는 중요도가 커질 것”이라는 가정 때문입니다.
나머지 수치 하나는 단어별 문서 빈도(Document Frequency, DF) 입니다. DF는 특정 단어가 말뭉치 내에 있는 전체 문서 중 몇 개의 문서에 등장했는지를 나타내는 수치입니다. 단어 가중치에서 DF를 고려하는 이유는 무엇일까요? 처음에 뇌구조를 생각했던 것처럼 잠시 자연어처리를 벗어난 다른 주제로부터 DF가 중요한 이유를 알아보도록 합시다. 아래는 한 블로그에 올라온 점심 식단표입니다. (정확히는 훈련소 식단을 복원한 거라고 합니다.)
이미지 출처 : 네이버 블로그
위와 같은 식단표가 있다고 해봅시다. 4주차 목요일에 누군가가 “오늘 점심 메뉴 뭐야?” 라고 물었을 때 메뉴 하나만 대답한다면 일반적인 대답은 “돈까스” 혹은 “부대찌개” 정도일 것입니다. “밥” 혹은 “우유” 도 이들과 같이 점심 메뉴로 나오겠지만 이런 대답은 질문자가 원하는 것은 아니겠지요. “밥” 과 “우유” 가 좋지 않은 대답인 이유는 무엇일까요? 그렇습니다. 다른 날 점심에도 매번 “밥” 과 “우유” 가 나오는데 이게 “오늘 점심” 메뉴에선 별로 중요하지 않기 때문이죠. 각 식단을 하나의 문서로, 메뉴를 단어로 그대로 옮겨 적용해봅시다. 문서 속에서 “밥” 과 “우유” 에 해당하는 단어는 어떤 것들이 있을까요?
영어에서는 [“is”, “can”, “the”] 같은 단어들이 이런 범주에 속합니다. 한글에서도 형태소 분석후 나오는 [‘의’,’가’,’이’,’은’,’들’] 등의 단어는 모든 문서에 등장합니다. 이렇게 과하게 많이 등장하는 단어는 불용어(Stop word)로 지정하여 분석 대상에서 제외하기도 합니다. 모든 문서에 자주 등장하지만 문서 입장에서 보면 크게 의미있는 단어는 아니기 때문입니다. 이런 불용어를 제거하고 난 다음에도 분석할 문서들에 자주 등장하는 단어들은 낮은 가중치를 주어야 할 것입니다.
결론적으로 모든 문서에 자주 등장하는, 즉 단어별 문서 빈도(DF)가 높은 단어는 낮은 가중치를 주어야 합니다. 그렇기 때문에 실제로는 DF의 수치에 역수를 해준 뒤 로그를 취한 수치인 IDF(Inverse Document Frequency) 를 사용합니다. 일반적으로 IDF에 로그를 취하는 이유는 단어의 출현 빈도가 지프의 법칙1을 따르기 때문입니다.
오늘의 목표인 TF-IDF는 이 두 수치를 곱한 것입니다. 이렇게 구해진 TF-IDF는 특정 단어(Term)가 해당 문서(Document)에 얼마나 중요한지를 나타내는 가중치가 됩니다. 수식으로 나타내면 다음과 같습니다.
[\text{TF-IDF(w)} = \text{TF(w)} \times \log_{10} \frac{N}{\text{DF(w)}}]
아래는 실제 4개의 문서(이코노미스트 칼럼 번역 자료)를 형태소 분석 후 문서-단어 행렬(DTM)을 만든 후 문서에 등장하는 일부 단어들의 TF를 기록한 것입니다. 가장 오른쪽 열에는 구해진 TF로부터 DF까지 기록하였습니다. (예시를 돕기 위해서 극적인 사례를 선택하였습니다.) 아래 표를 보며 TF-IDF를 더 잘 이해해봅시다.
| DTM | 문서1 (석유 관련) | 문서2 (부동산 관련) | 문서3 (콘텐츠 관련) | 문서4 (기후 관련) | DF |
|---|---|---|---|---|---|
| 유가 | 27 | 0 | 0 | 0 | 1 |
| 원유 | 19 | 0 | 1 | 0 | 2 |
| 부동산 | 0 | 48 | 0 | 0 | 1 |
| 주택 | 0 | 38 | 0 | 0 | 1 |
| 콘텐츠 | 0 | 0 | 35 | 0 | 1 |
| 넷플릭스 | 0 | 0 | 35 | 0 | 1 |
| 기후 | 0 | 1 | 0 | 38 | 2 |
| 탄소 | 0 | 0 | 0 | 26 | 1 |
| 퍼센트 | 19 | 21 | 8 | 4 | 4 |
| 달러 | 24 | 21 | 26 | 14 | 4 |
| 미국 | 9 | 25 | 14 | 3 | 4 |
| 시장 | 4 | 28 | 22 | 6 | 4 |
위에서 각 단어를 위에서부터 분석해봅시다. 분석에 사용된 12개의 단어 중 “유가”, “원유” 는 석유와 관련된 칼럼에, “부동산”, “주택” 은 부동산과 관련된 칼럼에, “콘텐츠”, “넷플릭스” 는 콘텐츠와 관련된 칼럼에, “기후”, “탄소” 는 기후과 관련된 칼럼에 집중되어 있는 것을 알 수 있습니다. 이 중 “원유” 와 “기후” 는 다른 문서에도 한 번씩 등장했네요. 나머지 네 단어인 “퍼센트”, “달러”, “미국”, “시장” 을 분석한 결과 이 단어들은 모든 문서에서 고르게 1번 이상 등장하고 있는 것을 알 수 있습니다. 심지어 석유와 관련된 문서1에서 “퍼센트” 라는 단어는 “원유” 라는 단어만큼 등장했습니다. 하지만 과연 문서1에서 “퍼센트” 라는 단어가 “달러” 라는 단어만큼 중요할까요? 답은 TF-IDF가 알려줄 것입니다. 아래는 위 표를 기반으로 문서별 단어의 TF-IDF를 구한 표입니다.
| DTM | 문서1 (석유 관련) | 문서2 (부동산 관련) | 문서3 (콘텐츠 관련) | 문서4 (기후 관련) | IDF |
|---|---|---|---|---|---|
| 유가 | 16.26 | 0 | 0 | 0 | $2\log2$ |
| 원유 | 5.72 | 0 | 0.30 | 0 | $\log2$ |
| 부동산 | 0 | 28.90 | 0 | 0 | $2\log2$ |
| 주택 | 0 | 22.88 | 0 | 0 | $2 \log2$ |
| 콘텐츠 | 0 | 0 | 21.07 | 0 | $2 \log2$ |
| 넷플릭스 | 0 | 0 | 21.07 | 0 | $2 \log2$ |
| 기후 | 0 | 0.30 | 0 | 11.44 | $\log2$ |
| 탄소 | 0 | 0 | 0 | 15.65 | $2 \log2$ |
| 퍼센트 | 0 | 0 | 0 | 0 | $\log1$ |
| 달러 | 0 | 0 | 0 | 0 | $\log1$ |
| 미국 | 0 | 0 | 0 | 0 | $\log1$ |
| 시장 | 0 | 0 | 0 | 0 | $\log1$ |
위 표를 보면 아래 모든 문서에 등장하는 “퍼센트”, “달러”, “미국”, “시장” 의 TF-IDF는 0이 되었음을 알 수 있습니다. 이렇게 TF-IDF를 사용하면 한 문서에 자주 등장하는 단어에 대해서 중요도를 높일 수 있으면서도, 그 단어가 분석하려는 말뭉치 속 문서들에 골고루 등장할 경우 중요도를 낮추는 효과를 줄 수 있습니다.
다양한 TF-IDF 측정 방식과 활용
처음 TF-IDF라는 가중치 부여 방법이 고안되고 시간이 지나면서 이를 보정하기 위한 다양한 측정 방법이 생겨났습니다. 아래는 TF와 IDF를 측정하기 위한 다양한 방법을 담은 이미지입니다.
이미지 출처 : Information Retrieval Models
이들 중 가장 좋은 성능을 보이는 절대적인 방법이 있는 것은 아닙니다. 분석할 말뭉치나 TF-IDF를 적용할 태스크에 따라 가장 적절한 방법이 달라집니다. 아래는 일반적으로 가장 많이 사용되는 TF-IDF 방식을 나타낸 것입니다.
이미지 출처 : Information Retrieval Models
TF-IDF는 자연어처리 외에도 추천 시스템(Recommendation system) 등 다양한 분야에서 활용되고 있습니다. 이를 테면, 콘텐츠와 사용자간 행렬을 구성한 뒤 해당 콘텐츠가 특정 집단의 사용자에게 얼마나 중요한지에 대한 가중치를 부여하는 태스크 등에 사용됩니다.
-
“지프의 법칙에 따르면 어떠한 자연어 말뭉치 표현에 나타나는 단어들을 그 사용 빈도가 높은 순서대로 나열하였을 때, 모든 단어의 사용 빈도는 해당 단어의 순위에 반비례한다. 따라서 가장 사용 빈도가 높은 단어는 두 번째 단어보다 빈도가 약 두 배 높으며, 세 번째 단어보다는 빈도가 세 배 높다. 예를 들어, 브라운 대학교 현대 미국 영어 표준 말뭉치의 경우, 가장 사용 빈도가 높은 단어는 영어 정관사 “the”이며 전체 문서에서 7%의 빈도(약 백만 개 남짓의 전체 사용 단어 중 69,971회)를 차지한다. 두 번째로 사용 빈도가 높은 단어는 “of”로 약 3.5% 남짓(36,411회)한 빈도를 차지하며, 세 번째로 사용 빈도가 높은 단어는 “and”(28,852회)로, 지프의 법칙에 정확히 들어 맞는다. 약 135개 항목의 어휘만으로 브라운 대학 말뭉치의 절반을 나타낼 수 있다.” -위키피디아 : 지프의 법칙(Zipf’s law) ↩