
이미지 분류를 위한 모델들
28 Mar 2020 | Deep-Learning
Models
이번 게시물에서는 컴퓨터 비전 분야에 사용되어온 모델들에 대해서 알아보겠습니다. 블로그에서는 비전에 대해서는 깊게 다루고 있지 않으므로 모델의 이름과 구조만 간단하게 소개하도록 하겠습니다.
AlexNet
가장 첫 번째는 대표적인 모델인 알렉스넷(AlexNet)입니다. 알렉스넷은 2012년 이미지넷(ImageNet)1 데이터 분류 대회에서 우승하며 큰 주목을 받았습니다. 아래는 알렉스넷의 구조입니다.
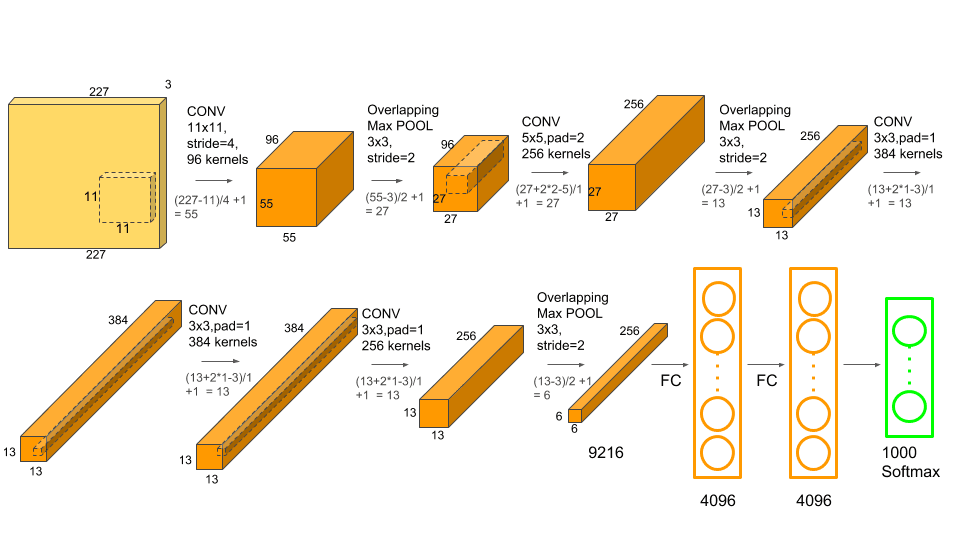
이미지 출처 : neurohive.io
총 5개의 합성곱 층을 사용하고 있으며 2개의 완전 연결 층을 사용하고 있는 것을 볼 수 있습니다.
VGG
이후로 소개될 모델은 위 알렉스넷보다 층을 더 깊게 쌓은 모델입니다. 층을 더 깊게 쌓으면 어떤 점이 좋을까요? 우선, 층을 깊게 하면 신경망에 있는 파라미터의 수가 줄어듭니다. 층을 깊게 하면 적은 파라미터로도 높은 수준의 표현력을 달성할 수 있기 때문입니다. 한 개의 층에서 $5 \times 5$ 크기의 필터를 사용하여 하나의 출력값을 낼 때에는 $5 \times 5 = 25$개의 파라미터가 필요합니다. 하지만 $3 \times 3$ 필터를 사용하여 $2$층으로 쌓으면 $3 \times 3 \times 2 = 18$ 개의 파라미터 만으로도 같은 크기의 공간을 표현할 수 있게 됩니다.
이 차이는 층을 더 깊게 쌓으면 더 커집니다. 한 개의 층에서 $9 \times 9$ 크기의 필터를 사용하면 $9 \times 9 = 81$개의 파라미터가 필요하지만, $3 \times 3$ 크기의 필터를 $4$층으로 쌓으면 $3 \times 3 \times 4 = 36$ 개의 파라미터만으로 동일한 공간을 학습하게 됩니다. 이렇게 층을 깊게 쌓으면 한 층에서 학습해야 하는 정보의 양도 줄어들기 때문에 학습 시간을 더욱 빠르게 할 수 있다는 장점이 있습니다.
VGG16은 Visual Geometry Group에서 개발한 이미지 분류를 위한 합성곱 신경망 모델입니다. 13개의 합성곱 층과 3개의 완전 연결 층까지 무려 16개의 층을 쌓았기 때문에 이런 이름이 붙었습니다.

이미지 출처 : neurohive.io
VGG의 특징은 다음과 같은 것들이 있습니다. 첫 번째로 모든 합성곱 층에서 $3 \times 3$ 크기의 작은 필터를 사용하였습니다. 대신 층을 깊게 쌓음으로써 기존에 사용하던 $7 \times 7$ 혹은 $11 \times 11$ 크기의 필터를 사용했을 때와 동일하거나 더 높은 표현력을 가질 수 있게된 것이지요. 두 번째로 활성화 함수로 ReLU를 사용하였으며 가중치 초깃값으로는 He초깃값을 사용하였습니다. 덕분에 층을 깊게 쌓았음에도 기울기 소실(Gradient vanishing)문제를 해결할 수 있었습니다. 마지막으로 완전 연결 층 뒤에 드롭아웃(Dropout)을 사용하여 과적합을 방지하였으며 옵티마이저로는 아담(Adam)을 사용했다는 특징이 있습니다.
VGG16은 14년 이미지넷 대회에서 앞서 소개한 알렉스넷(AlexNet)의 오차율을 반으로 줄임으로써 이미지 인식 분야에서 큰 향상을 가져왔다는 의의를 가지는 모델입니다. 층의 개수를 변형한 모델인 VGG13, VGG19도 존재합니다. 모델의 구조가 단순하기에 VGG를 다양하게 응용하여 사용하는 사례도 많습니다.
GoogLeNet
GoogLeNet은 말 그대로 구글이 발표한 모델이며, 오래 전 이미지 인식 분야에서 획기적인 성능을 나타내었던 LeNet의 이름을 땄습니다. GoogLeNet역시 기본적인 합성곱 신경망 형태를 띠고 있습니다. 하지만 세로 방향의 깊이 뿐만 아니라 가로 방향으로도 넓은 신경망 층을 가지고 있다는 것이 특징입니다. GoogLeNet의 구조는 아래와 같습니다.
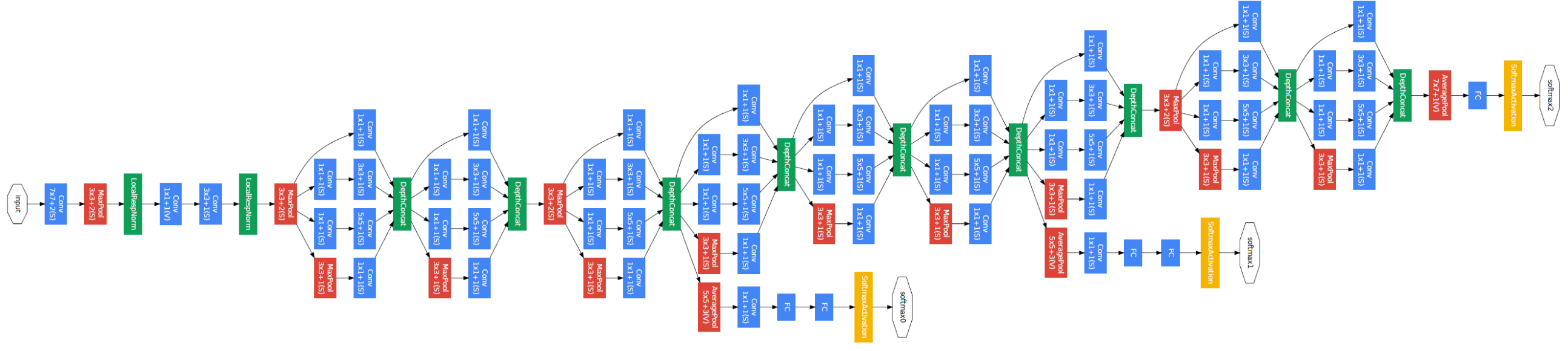
이미지 출처 : bskyvision.com
이렇게 가로 방향으로 층을 넓게 구성한 것을 인셉션 구조라고 합니다. GoogLeNet에서는 인셉션 구조를 활용하여 크기가 다른 필터와 풀링을 병렬적으로 적용하여 그 결과를 조합합니다. 위 그림에서 파란색 층은 필터가 적용되는 합성곱 층이며 빨간 색은 풀링 층입니다. GoogleNet은 인셉션 기법을 통해 2015년 이미지넷 대회에서 VGG보다 더 좋은 성능을 달성한 모델입니다.
ResNet
ResNet은 스킵 연결(Skip connection)이라는 기법을 적용하여 성능을 향상시킨 모델입니다. 이를 수행하는 구간을 Residual block 이라고도 부르는데 이로부터 ResNet이라고 이름을 붙였습니다. 스킵 연결이 적용되는 과정을 도식화하면 아래와 같습니다.

이미지 출처 : programmersought.com
스킵 연결을 사용하면 입력 $x$를 연속한 두 합성곱 계층을 뛰어넘어 그 출력값에 바로 더해줍니다. 스킵 연결이 없다면 2개의 층을 지난 후의 출력은 $F(x)$가 되지만, 스킵 연결을 사용하면 출력값 $F(x)$에 입력값 $x$ 를 그대로 더해주어 최종 출력값을 $F(x) + x$ 로 만들어 줍니다. 이 방법은 역전파를 통하여 학습하는 과정에서 너무 작은 그래디언트를 보내지 않도록 합니다. 아래는 스킵 연결을 적용한 ResNet의 전체 구조를 나타낸 이미지입니다.

이미지 출처 : developer.ridgerun.com
위 그림에서 ResNet은 인셉션 구조를 사용하지 않았다는 것을 볼 수 있습니다. 오히려 수직으로만 층을 쌓은 VGG와 더욱 비슷하다고 볼 수 있습니다. 하지만 VGG16의 2배가 넘는 34개의 층을 사용하였으며 이로 인해 발생하는 기울기 소실 문제를 스킵 연결로 극복하고 있다는 것을 알 수 있습니다.
이런 스킵 연결은 ResNet뿐만 아니라 자연어처리의 트랜스포머(Transformer) 등의 다양한 모델에도 사용되고 있습니다. ResNet은 이러한 스킵 연결을 적용한 모델이라는 의의를 가지고 있습니다.
Problems
합성곱 신경망을 활용한 여러 모델은 이미지 처리 분야에서 엄청난 성능을 보여왔지만 여전히 풀어야할 숙제도 있습니다. 첫 번째는 합성곱 층에서의 연산 횟수 문제입니다. 합성곱 신경망은 각 필터가 옮겨가면서 파라미터 개수만큼의 곱연산을 실행하므로 큰 이미지를 처리할 때에는 엄청나게 많은 횟수의 연산을 수행해야 합니다. 이런 많은 연산을 수행하기 위해 GPU컴퓨팅을 통한 고속 연산과 병렬 분산 학습 등 많은 기법이 고안되고 있습니다.
메모리 사용량도 문제입니다. 필터의 개수가 많아질수록 저장해야 하는 가중치 매개변수가 많아집니다. 많은 메모리를 확보하는 것도 하나의 해결방법이 될 수 있지만, 이는 어느정도 한계가 있습니다. 이를 해결하기 위하여 딥러닝에서는 간단한 부동소수점 표현을 사용합니다. 컴퓨터에서는 일반적인 연산을 위해 64bit 혹은 32bit의 부동소수점을 사용하지만, 딥러닝에서는 16bit 반정밀도를 사용하여 연산하여도 큰 문제가 없는 것으로 알려져 있기 때문에 이정도 수준의 표현을 사용하여 메모리를 절약합니다.
Various uses
이미지 처리 분야에서는 이러한 모델을 다양한 분야에 사용하고 있습니다. 첫 번째는 사물 검출(Object detection)입니다. 이는 이미지 속에 담긴 사물의 위치와 그 사물의 클래스를 알아내기 위한 기술입니다. 이를 위해서 R-CNN(Regions with convolutional neural network)류의 모델을 사용합니다.
두 번째는 분할(Segmentation)입니다. 이는 이미지를 픽셀 수준에서 구분하는 기술입니다. FCN(Fully convolutional network) 류의 모델이 이런 역할을 할 수 있습니다. 이런 기술들을 활용하여 컴퓨터가 보는 사물을 구분하고 그 사물의 위치를 인지할 수 있기 때문에 자율 주행을 포함한 여러 분야에 사용할 수 있습니다.
또한, VAE(Variational autoencoder)이나 GAN(Generative adversarial network)등을 사용하는 생성 모델도 활발히 연구되고 있는 분야입니다.
-
이미지넷(ImageNet)은 100만 장이 넘는 이미지를 담고 있는 데이터셋입니다. 레이블이 포함된 다양한 종류의 이미지 데이터로 구성되어 있습니다. 매년 열리는 ILSVRC라는 대회에서는 이미지넷 데이터셋을 사용하여 모델의 성능을 평가합니다. ILSVRC의 분류 부문에서 2012년이 AlexNet이 우승한 이래로 Clarifi(2013), VGG(2014), GoogLeNet(2015), ResNet(2016) 등 딥러닝 모델이 좋은 성능을 기록하고 있습니다. ↩
Models
이번 게시물에서는 컴퓨터 비전 분야에 사용되어온 모델들에 대해서 알아보겠습니다. 블로그에서는 비전에 대해서는 깊게 다루고 있지 않으므로 모델의 이름과 구조만 간단하게 소개하도록 하겠습니다.
AlexNet
가장 첫 번째는 대표적인 모델인 알렉스넷(AlexNet)입니다. 알렉스넷은 2012년 이미지넷(ImageNet)1 데이터 분류 대회에서 우승하며 큰 주목을 받았습니다. 아래는 알렉스넷의 구조입니다.
이미지 출처 : neurohive.io
총 5개의 합성곱 층을 사용하고 있으며 2개의 완전 연결 층을 사용하고 있는 것을 볼 수 있습니다.
VGG
이후로 소개될 모델은 위 알렉스넷보다 층을 더 깊게 쌓은 모델입니다. 층을 더 깊게 쌓으면 어떤 점이 좋을까요? 우선, 층을 깊게 하면 신경망에 있는 파라미터의 수가 줄어듭니다. 층을 깊게 하면 적은 파라미터로도 높은 수준의 표현력을 달성할 수 있기 때문입니다. 한 개의 층에서 $5 \times 5$ 크기의 필터를 사용하여 하나의 출력값을 낼 때에는 $5 \times 5 = 25$개의 파라미터가 필요합니다. 하지만 $3 \times 3$ 필터를 사용하여 $2$층으로 쌓으면 $3 \times 3 \times 2 = 18$ 개의 파라미터 만으로도 같은 크기의 공간을 표현할 수 있게 됩니다.
이 차이는 층을 더 깊게 쌓으면 더 커집니다. 한 개의 층에서 $9 \times 9$ 크기의 필터를 사용하면 $9 \times 9 = 81$개의 파라미터가 필요하지만, $3 \times 3$ 크기의 필터를 $4$층으로 쌓으면 $3 \times 3 \times 4 = 36$ 개의 파라미터만으로 동일한 공간을 학습하게 됩니다. 이렇게 층을 깊게 쌓으면 한 층에서 학습해야 하는 정보의 양도 줄어들기 때문에 학습 시간을 더욱 빠르게 할 수 있다는 장점이 있습니다.
VGG16은 Visual Geometry Group에서 개발한 이미지 분류를 위한 합성곱 신경망 모델입니다. 13개의 합성곱 층과 3개의 완전 연결 층까지 무려 16개의 층을 쌓았기 때문에 이런 이름이 붙었습니다.
이미지 출처 : neurohive.io
VGG의 특징은 다음과 같은 것들이 있습니다. 첫 번째로 모든 합성곱 층에서 $3 \times 3$ 크기의 작은 필터를 사용하였습니다. 대신 층을 깊게 쌓음으로써 기존에 사용하던 $7 \times 7$ 혹은 $11 \times 11$ 크기의 필터를 사용했을 때와 동일하거나 더 높은 표현력을 가질 수 있게된 것이지요. 두 번째로 활성화 함수로 ReLU를 사용하였으며 가중치 초깃값으로는 He초깃값을 사용하였습니다. 덕분에 층을 깊게 쌓았음에도 기울기 소실(Gradient vanishing)문제를 해결할 수 있었습니다. 마지막으로 완전 연결 층 뒤에 드롭아웃(Dropout)을 사용하여 과적합을 방지하였으며 옵티마이저로는 아담(Adam)을 사용했다는 특징이 있습니다.
VGG16은 14년 이미지넷 대회에서 앞서 소개한 알렉스넷(AlexNet)의 오차율을 반으로 줄임으로써 이미지 인식 분야에서 큰 향상을 가져왔다는 의의를 가지는 모델입니다. 층의 개수를 변형한 모델인 VGG13, VGG19도 존재합니다. 모델의 구조가 단순하기에 VGG를 다양하게 응용하여 사용하는 사례도 많습니다.
GoogLeNet
GoogLeNet은 말 그대로 구글이 발표한 모델이며, 오래 전 이미지 인식 분야에서 획기적인 성능을 나타내었던 LeNet의 이름을 땄습니다. GoogLeNet역시 기본적인 합성곱 신경망 형태를 띠고 있습니다. 하지만 세로 방향의 깊이 뿐만 아니라 가로 방향으로도 넓은 신경망 층을 가지고 있다는 것이 특징입니다. GoogLeNet의 구조는 아래와 같습니다.
이미지 출처 : bskyvision.com
이렇게 가로 방향으로 층을 넓게 구성한 것을 인셉션 구조라고 합니다. GoogLeNet에서는 인셉션 구조를 활용하여 크기가 다른 필터와 풀링을 병렬적으로 적용하여 그 결과를 조합합니다. 위 그림에서 파란색 층은 필터가 적용되는 합성곱 층이며 빨간 색은 풀링 층입니다. GoogleNet은 인셉션 기법을 통해 2015년 이미지넷 대회에서 VGG보다 더 좋은 성능을 달성한 모델입니다.
ResNet
ResNet은 스킵 연결(Skip connection)이라는 기법을 적용하여 성능을 향상시킨 모델입니다. 이를 수행하는 구간을 Residual block 이라고도 부르는데 이로부터 ResNet이라고 이름을 붙였습니다. 스킵 연결이 적용되는 과정을 도식화하면 아래와 같습니다.
이미지 출처 : programmersought.com
스킵 연결을 사용하면 입력 $x$를 연속한 두 합성곱 계층을 뛰어넘어 그 출력값에 바로 더해줍니다. 스킵 연결이 없다면 2개의 층을 지난 후의 출력은 $F(x)$가 되지만, 스킵 연결을 사용하면 출력값 $F(x)$에 입력값 $x$ 를 그대로 더해주어 최종 출력값을 $F(x) + x$ 로 만들어 줍니다. 이 방법은 역전파를 통하여 학습하는 과정에서 너무 작은 그래디언트를 보내지 않도록 합니다. 아래는 스킵 연결을 적용한 ResNet의 전체 구조를 나타낸 이미지입니다.
이미지 출처 : developer.ridgerun.com
{kind=link}
위 그림에서 ResNet은 인셉션 구조를 사용하지 않았다는 것을 볼 수 있습니다. 오히려 수직으로만 층을 쌓은 VGG와 더욱 비슷하다고 볼 수 있습니다. 하지만 VGG16의 2배가 넘는 34개의 층을 사용하였으며 이로 인해 발생하는 기울기 소실 문제를 스킵 연결로 극복하고 있다는 것을 알 수 있습니다.
이런 스킵 연결은 ResNet뿐만 아니라 자연어처리의 트랜스포머(Transformer) 등의 다양한 모델에도 사용되고 있습니다. ResNet은 이러한 스킵 연결을 적용한 모델이라는 의의를 가지고 있습니다.
Problems
합성곱 신경망을 활용한 여러 모델은 이미지 처리 분야에서 엄청난 성능을 보여왔지만 여전히 풀어야할 숙제도 있습니다. 첫 번째는 합성곱 층에서의 연산 횟수 문제입니다. 합성곱 신경망은 각 필터가 옮겨가면서 파라미터 개수만큼의 곱연산을 실행하므로 큰 이미지를 처리할 때에는 엄청나게 많은 횟수의 연산을 수행해야 합니다. 이런 많은 연산을 수행하기 위해 GPU컴퓨팅을 통한 고속 연산과 병렬 분산 학습 등 많은 기법이 고안되고 있습니다.
메모리 사용량도 문제입니다. 필터의 개수가 많아질수록 저장해야 하는 가중치 매개변수가 많아집니다. 많은 메모리를 확보하는 것도 하나의 해결방법이 될 수 있지만, 이는 어느정도 한계가 있습니다. 이를 해결하기 위하여 딥러닝에서는 간단한 부동소수점 표현을 사용합니다. 컴퓨터에서는 일반적인 연산을 위해 64bit 혹은 32bit의 부동소수점을 사용하지만, 딥러닝에서는 16bit 반정밀도를 사용하여 연산하여도 큰 문제가 없는 것으로 알려져 있기 때문에 이정도 수준의 표현을 사용하여 메모리를 절약합니다.
Various uses
이미지 처리 분야에서는 이러한 모델을 다양한 분야에 사용하고 있습니다. 첫 번째는 사물 검출(Object detection)입니다. 이는 이미지 속에 담긴 사물의 위치와 그 사물의 클래스를 알아내기 위한 기술입니다. 이를 위해서 R-CNN(Regions with convolutional neural network)류의 모델을 사용합니다.
두 번째는 분할(Segmentation)입니다. 이는 이미지를 픽셀 수준에서 구분하는 기술입니다. FCN(Fully convolutional network) 류의 모델이 이런 역할을 할 수 있습니다. 이런 기술들을 활용하여 컴퓨터가 보는 사물을 구분하고 그 사물의 위치를 인지할 수 있기 때문에 자율 주행을 포함한 여러 분야에 사용할 수 있습니다.
또한, VAE(Variational autoencoder)이나 GAN(Generative adversarial network)등을 사용하는 생성 모델도 활발히 연구되고 있는 분야입니다.
-
이미지넷(ImageNet)은 100만 장이 넘는 이미지를 담고 있는 데이터셋입니다. 레이블이 포함된 다양한 종류의 이미지 데이터로 구성되어 있습니다. 매년 열리는 ILSVRC라는 대회에서는 이미지넷 데이터셋을 사용하여 모델의 성능을 평가합니다. ILSVRC의 분류 부문에서 2012년이 AlexNet이 우승한 이래로 Clarifi(2013), VGG(2014), GoogLeNet(2015), ResNet(2016) 등 딥러닝 모델이 좋은 성능을 기록하고 있습니다. ↩
Comments