
Bag of Words (BoW)
12 May 2020 | NLP
본 포스트의 내용은 고려대학교 강필성 교수님의 강의 와 김기현의 자연어처리 딥러닝 캠프 , 밑바닥에서 시작하는 딥러닝 2 , 한국어 임베딩 , 자연어 처리 인 액션 책을 참고하였습니다.
단어를 벡터로 표현하기
자연어처리에서 우리가 처리하고자 하는 문서(Document)나 문장(Sentence)은 각각의 길이가 다릅니다. 많은 단어로 구성된 문서도 있고 적은 단어로 구성된 문서도 있지요. 서로 다른 길이인 문서를 컴퓨터에 집어넣기 위해서는 일정한 길이의 벡터로 변환해주어야 합니다. 컴퓨터에게 행렬 혹은 텐서 연산을 맡기기 위해서는 모든 벡터의 길이를 갖게 해주어야 하기 때문입니다. 테이블로 이루어진 정형 데이터의 경우에는 이미 모든 인스턴스의 길이가 같기 때문에 일정한 길이의 벡터로 변환할 필요가 없습니다. 하지만 비정형 데이터인 자연어의 경우 단어나 문서를 벡터로 표현(Representation)하는 것은 중요한 과제 중 하나입니다. 단어를 벡터로 표현하는 방법은 크게 두 가지로 나눌 수 있습니다. 첫 번째는 숫자 기반의 표현(Count-based representation) 입니다. 숫자 기반의 표현에는 이번 게시물의 주제인 Bag of Words, 그리고 이를 고도화한 TF-IDF 와 N-gram 등이 있습니다. 두 번째는 분산 표현(Distributed representation) 입니다. 임베딩(Embedding) 이라고도 부르는 분산 표현 방식에는 Word2Vec 와 GloVe, Fasttext 등 다양한 방법이 있습니다. 이번 시간에는 숫자 기반의 표현에서 가장 기본이 되는 Bag of Words 에 대해 알아보도록 합시다.
Bag of Words
Bag of Words 는 문서를 여러 단어가 들어있는 가방(bag)처럼 생각하는 표현 방식입니다. 유튜브에 존재하는 왓츠 인 마이백(What’s in my bag?) 영상을 떠올려 봅시다. 해당 영상에서 유튜버는 자기 가방에 들어있는 물건을 하나씩 꺼내어 확인해주는데요. 이런 방식을 문서에 적용한 것이 Bag of Words 입니다. 아래 그림을 보며 설명을 이어나가겠습니다.
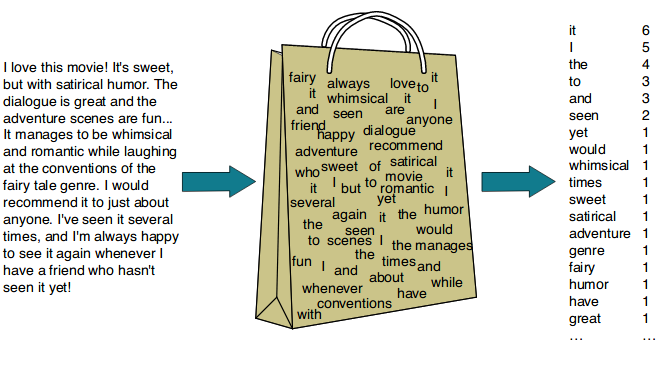
이미지 출처 : dudeperf3ct.github.io
왓츠 인 마이백 영상에서 유튜버가 가방에 어떤 물건이 있는지를 확인하여 보여주는 것처럼, Bag of Words 에서도 문서로부터 단어를 하나씩 꺼내어 기록합니다. 위 그림처럼 문서 내에 있는 모든 단어에 대해 단어가 등장할 때마다 기록하는 방식입니다. Bag of Words 는 ‘이렇게 헤아린 단어의 빈도로부터 무언가를 추론할 수 있을 것이다’라는 전제를 바탕으로 합니다.
Term-Document Matrix
단어-문서 행렬(Term-Document Matrix, TDM) 을 만드는 것은 Bag of Words 의 처음이자 끝입니다. 단어-문서 행렬에서 열(Column)에 해당하는 부분은 우리가 분석하고자 하는 각각의 문서(Document)를 입니다. 행에 해당하는 부분은 문서 전체에 등장하는 단어(Term)가 됩니다. 그리고 각 문서에 해당 단어가 등장하는지 아닌지, 혹은 몇 번이나 등장하는지를 기록합니다. 경우에 따라서는 단어-문서 행렬을 전치시킨 문서-단어 행렬(Document-Term Matrix, DTM)을 사용하기도 합니다.
단어-문서 행렬은 단어를 어떤 방식으로 기록할 것인지에 따라 두 종류로 나뉩니다. 아래 이미지를 통해 두 방식을 비교할 수 있습니다.

이미지 출처 : Text-Analytics Github
위 그림에서 왼쪽에 있는 단어-문서 행렬은 이진 표현(Binary representation)을 사용하여 나타낸 것이고 오른쪽에 있는 단어-문서 행렬은 빈도 표현(Frequency representation)을 사용하여 나타낸 것입니다. 분석하고자 하는 문장이 길지 않기 때문에 두 방식간에 큰 차이는 없습니다. 유일한 차이는 2번 행에 해당하는 “Likes” 입니다. 이진 표현은 문서에 단어가 등장했는지 아닌지만을 나타내기 때문에 $S_1$ 에서의 값이 $1$ 이 됩니다. 반면에 단어가 등장한 횟수를 헤아리는 빈도 표현에서는 $S_1$ 에 “Likes” 가 2번 등장하기 때문에 $2$ 로 표현한 것을 볼 수 있습니다. 두 표현 중 빈도 표현이 이진 표현보다 더 많은 정보를 담고 있는 것은 사실입니다. 하지만 특정 태스크에서는 이진 표현이 더 좋은 결과를 보여줄 때도 있기 때문에 태스크에 맞는 표현 방식을 사용하는 것이 좋습니다.
단점과 의의
Bag of Words의 단점은 단어가 등장하는 순서, 즉 어순을 고려하지 않는다는 점입니다. 아래는 (비속어가 있긴 하지만) “한글의 위대함.jpg” 라는 제목으로 떠도는 이미지입니다.

(맨 마지막 문장에 등장하는 “시발”만 “씨발”로 오타를 고친다면) 위 이미지에 나타난 11개 문장을 Bag of Words로 표현하면 모두 ”{ 영어는 : 1, 씨발 : 1, 이런거 : 1, 안되잖아 : 1 }” 로 나오게 됩니다. 실제로는 11개의 문장이 서로 다르지만 Bag of Words 로 표현하면 모두 같게 되는 것입니다. 다른 예시도 있습니다 “Mary loves John” 과 “John loves Mary” 는 주어와 목적어가 반대이기 때문에 의미가 완전히 다른 문장입니다. 하지만 이 두 문장을 Bag of Words로 표현하면 모두 ”{ Mary : 1, loves : 1, John : 1 }” 로 같아져 버립니다. 이런 단점 때문에 단어 사이의 관계나 문맥의 의미가 중요한 태스크에 Bag of Words 를 사용하는 것은 적절하지 못할 때가 많습니다.
이런 단점에도 불구하고 Bag of Words는 이해하기 쉬우며 TF-IDF 나 N-gram의 기반이 되는 방법이 됩니다. 또한 단어를 벡터로 표현하는 가장 고전적인 방법이라는 의미도 가지고 있습니다.
본 포스트의 내용은 고려대학교 강필성 교수님의 강의 와 김기현의 자연어처리 딥러닝 캠프 , 밑바닥에서 시작하는 딥러닝 2 , 한국어 임베딩 , 자연어 처리 인 액션 책을 참고하였습니다.
단어를 벡터로 표현하기
자연어처리에서 우리가 처리하고자 하는 문서(Document)나 문장(Sentence)은 각각의 길이가 다릅니다. 많은 단어로 구성된 문서도 있고 적은 단어로 구성된 문서도 있지요. 서로 다른 길이인 문서를 컴퓨터에 집어넣기 위해서는 일정한 길이의 벡터로 변환해주어야 합니다. 컴퓨터에게 행렬 혹은 텐서 연산을 맡기기 위해서는 모든 벡터의 길이를 갖게 해주어야 하기 때문입니다. 테이블로 이루어진 정형 데이터의 경우에는 이미 모든 인스턴스의 길이가 같기 때문에 일정한 길이의 벡터로 변환할 필요가 없습니다. 하지만 비정형 데이터인 자연어의 경우 단어나 문서를 벡터로 표현(Representation)하는 것은 중요한 과제 중 하나입니다. 단어를 벡터로 표현하는 방법은 크게 두 가지로 나눌 수 있습니다. 첫 번째는 숫자 기반의 표현(Count-based representation) 입니다. 숫자 기반의 표현에는 이번 게시물의 주제인 Bag of Words, 그리고 이를 고도화한 TF-IDF 와 N-gram 등이 있습니다. 두 번째는 분산 표현(Distributed representation) 입니다. 임베딩(Embedding) 이라고도 부르는 분산 표현 방식에는 Word2Vec 와 GloVe, Fasttext 등 다양한 방법이 있습니다. 이번 시간에는 숫자 기반의 표현에서 가장 기본이 되는 Bag of Words 에 대해 알아보도록 합시다.
Bag of Words
Bag of Words 는 문서를 여러 단어가 들어있는 가방(bag)처럼 생각하는 표현 방식입니다. 유튜브에 존재하는 왓츠 인 마이백(What’s in my bag?) 영상을 떠올려 봅시다. 해당 영상에서 유튜버는 자기 가방에 들어있는 물건을 하나씩 꺼내어 확인해주는데요. 이런 방식을 문서에 적용한 것이 Bag of Words 입니다. 아래 그림을 보며 설명을 이어나가겠습니다.
이미지 출처 : dudeperf3ct.github.io
왓츠 인 마이백 영상에서 유튜버가 가방에 어떤 물건이 있는지를 확인하여 보여주는 것처럼, Bag of Words 에서도 문서로부터 단어를 하나씩 꺼내어 기록합니다. 위 그림처럼 문서 내에 있는 모든 단어에 대해 단어가 등장할 때마다 기록하는 방식입니다. Bag of Words 는 ‘이렇게 헤아린 단어의 빈도로부터 무언가를 추론할 수 있을 것이다’라는 전제를 바탕으로 합니다.
Term-Document Matrix
단어-문서 행렬(Term-Document Matrix, TDM) 을 만드는 것은 Bag of Words 의 처음이자 끝입니다. 단어-문서 행렬에서 열(Column)에 해당하는 부분은 우리가 분석하고자 하는 각각의 문서(Document)를 입니다. 행에 해당하는 부분은 문서 전체에 등장하는 단어(Term)가 됩니다. 그리고 각 문서에 해당 단어가 등장하는지 아닌지, 혹은 몇 번이나 등장하는지를 기록합니다. 경우에 따라서는 단어-문서 행렬을 전치시킨 문서-단어 행렬(Document-Term Matrix, DTM)을 사용하기도 합니다.
단어-문서 행렬은 단어를 어떤 방식으로 기록할 것인지에 따라 두 종류로 나뉩니다. 아래 이미지를 통해 두 방식을 비교할 수 있습니다.
이미지 출처 : Text-Analytics Github
위 그림에서 왼쪽에 있는 단어-문서 행렬은 이진 표현(Binary representation)을 사용하여 나타낸 것이고 오른쪽에 있는 단어-문서 행렬은 빈도 표현(Frequency representation)을 사용하여 나타낸 것입니다. 분석하고자 하는 문장이 길지 않기 때문에 두 방식간에 큰 차이는 없습니다. 유일한 차이는 2번 행에 해당하는 “Likes” 입니다. 이진 표현은 문서에 단어가 등장했는지 아닌지만을 나타내기 때문에 $S_1$ 에서의 값이 $1$ 이 됩니다. 반면에 단어가 등장한 횟수를 헤아리는 빈도 표현에서는 $S_1$ 에 “Likes” 가 2번 등장하기 때문에 $2$ 로 표현한 것을 볼 수 있습니다. 두 표현 중 빈도 표현이 이진 표현보다 더 많은 정보를 담고 있는 것은 사실입니다. 하지만 특정 태스크에서는 이진 표현이 더 좋은 결과를 보여줄 때도 있기 때문에 태스크에 맞는 표현 방식을 사용하는 것이 좋습니다.
단점과 의의
Bag of Words의 단점은 단어가 등장하는 순서, 즉 어순을 고려하지 않는다는 점입니다. 아래는 (비속어가 있긴 하지만) “한글의 위대함.jpg” 라는 제목으로 떠도는 이미지입니다.
(맨 마지막 문장에 등장하는 “시발”만 “씨발”로 오타를 고친다면) 위 이미지에 나타난 11개 문장을 Bag of Words로 표현하면 모두 ”{ 영어는 : 1, 씨발 : 1, 이런거 : 1, 안되잖아 : 1 }” 로 나오게 됩니다. 실제로는 11개의 문장이 서로 다르지만 Bag of Words 로 표현하면 모두 같게 되는 것입니다. 다른 예시도 있습니다 “Mary loves John” 과 “John loves Mary” 는 주어와 목적어가 반대이기 때문에 의미가 완전히 다른 문장입니다. 하지만 이 두 문장을 Bag of Words로 표현하면 모두 ”{ Mary : 1, loves : 1, John : 1 }” 로 같아져 버립니다. 이런 단점 때문에 단어 사이의 관계나 문맥의 의미가 중요한 태스크에 Bag of Words 를 사용하는 것은 적절하지 못할 때가 많습니다.
이런 단점에도 불구하고 Bag of Words는 이해하기 쉬우며 TF-IDF 나 N-gram의 기반이 되는 방법이 됩니다. 또한 단어를 벡터로 표현하는 가장 고전적인 방법이라는 의미도 가지고 있습니다.
Comments