전진 선택(Forward Selection)과 후진 제거(Backward Elimination)
06 Sep 2020 | Machine-Learning
해당 게시물은 고려대학교 강필성 교수님의 강의를 바탕으로 작성한 것입니다.
Wrapper
래퍼(Wrapper)는 특성 선택(Feature selection)에 속하는 방법 중 하나로, 반복되는 알고리즘을 사용하는 지도 학습 기반의 차원 축소법입니다. 래퍼 방식에는 전진 선택(Forward selection), 후진 제거(Backward elimination), Stepwise selection 방식 뿐만아니라 유전 알고리즘(Genetic algorithm) 방식도 사용됩니다. 이번 게시물에서는 각 방법들에 대해 자세히 알아보겠습니다.
Exhaustive Search
완전 탐색(Exhaustive search)은 모든 특성 선택 방법 중 가장 단순한 방식입니다. 예를 들어, 특성이 3개 $x_1,x_2,x_3$인 데이터가 있다고 해보겠습니다. 이 때 완전 탐색 방법을 사용하면 다음의 특성 조합에 대해 모델을 모두 실험해보고 가장 성능이 좋은 것을 고릅니다.
[f(x_1),f(x_2),f(x_3),f(x_1,x_2),f(x_1,x_3),f(x_2,x_3),f(x_1,x_2,x_3)]
완전 탐색 방식의 가장 좋은 점은 언제나 Global optimum(전역 최적점)을 찾을 수 있다는 점입니다. 순서에 상관없이 모든 특성 조합에 대하여 모델을 시험해 보기 때문에 Local optimum(지역 최적점)에 빠질 우려가 없습니다.
하지만 완전 탐색을 사용하면 데이터셋의 특성이 $n$개 일 때, $2^n-1$ 만큼의 모델을 평가해야 합니다. 위의 예에서도 3개의 특성을 기준으로 완전 탐색을 사용하였더니 $2^3-1 = 7$개의 모델을 평가하였습니다. 특성의 개수에 대하여 지수적으로 증가하므로 특성의 개수가 늘어나면 모델 평가 횟수가 엄청나게 많아지게 됩니다. $n=30$ 이라면 $2^{30}-1$ 회, 즉 10억 번 이상의 모델 평가를 수행해야 합니다. 이런 이유에서 완전 탐색 방식은 현실적으로 사용 불가능합니다.
앞으로 알아볼 다른 알고리즘과 비교하기 위해서 시간-성능 그래프에 완전 탐색을 나타내어 보겠습니다. 완전 탐색은 최고의 성능을 보여주지만 최고 오랜 시간을 필요로하기 때문에 아래와 같이 나타낼 수 있습니다.

Forward Selection / Backward Elimination
다음으로 전진 선택과 후진 제거를 알아보겠습니다. 이 두 방법은 성능을 어느 정도 유지하면서 전역 탐색에서 걸리는 시간을 극적으로 줄인 방법입니다. 시간-성능 그래프에 두 방법을 나타내면 다음과 같이 나타낼 수 있습니다.

Forward Selection
전진 선택(Forward selection)은 가장 유의미한 특성을 선택해나가는 방식 입니다. 아무런 특성이 없는 상태부터 시작해서 특성을 늘려나가는 방향(Forward)으로 나아갑니다. 매 단계마다 가장 성능이 좋은 특성을 선택한 뒤에 유의미한 성능이 없을 때까지 이 과정을 실행해 나갑니다. 아래는 전진 선택의 과정을 나타낸 이미지입니다.
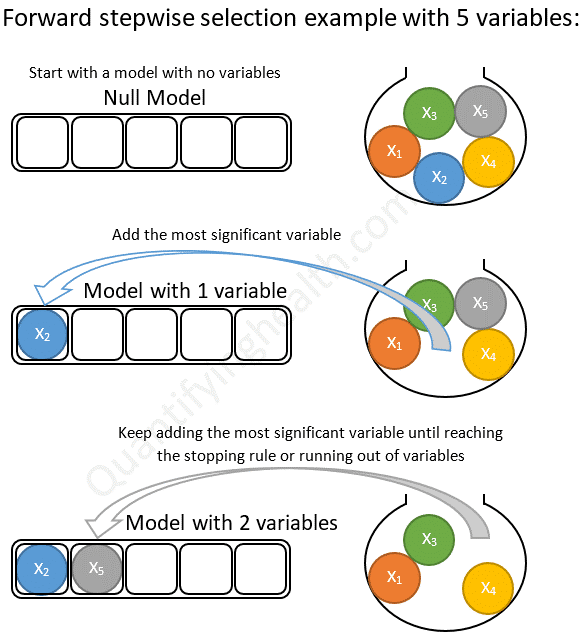
이미지 출처 : quantifyinghealth.com
특성이 5개 $x_1,x_2,x_3,x_4,x_5$인 데이터셋에 전진 선택 방식을 적용하여 특성 선택을 해보겠습니다(위 그림과는 관련이 없습니다). 먼저 1개의 특성만 가지는 모델의 성능을 비교합니다. 비교 성능으로는 조정된 결정계수(adjusted R-squared, $R^2_\text{adj}$)를 사용하겠습니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.32\
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.45
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 \qquad R^2\text{adj} = 0.53
\hat{y} = \hat{\beta_0} + \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.35
\hat{y} = \hat{\beta_0} + \hat{\beta_5}x_5 \qquad R^2_\text{adj} = 0.46]
$x_3$을 선택했을 때의 성능이 가장 좋으므로 이 특성을 고정한 뒤에 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3$ 을 대조군으로 놓고 동일한 과정을 반복합니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.55
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.58
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.71
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.66]
$x_4$의 특성을 추가적으로 선택했을 때의 성능이 가장 좋으므로 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4$ 를 대조군으로 놓고 동일한 과정을 반복합니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.71
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.70
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_3}x_5 \qquad R^2_\text{adj} = 0.69]
$x_1,x_2,x_5$중에서 어떤 특성을 추가하더라도 대조군인 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4$ 보다 성능이 좋아지지 않았으므로 여기서 과정을 멈추고 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4$ 을 특성 선택의 결과물로 선정합니다.
Backward Elimination
후진 제거(Backward elimination)는 무의미한 특성을 제거해나가는 방식 입니다. 반대로 모든 특성을 가진 모델에서 시작하여 특성을 하나씩 줄여나가는 방향(Backward)으로 나아갑니다. 특성을 제거했을 때 가장 성능이 좋은 모델을 선택함며 유의미한 성능 저하가 나타날 때까지 이 과정을 반복합니다. 아래는 후진 제거의 과정을 나타낸 이미지입니다.
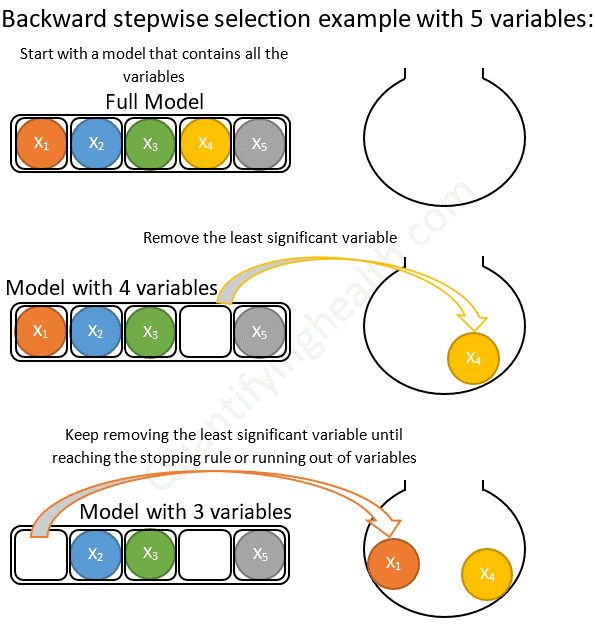
이미지 출처 : quantifyinghealth.com
동일하게 5개의 특성을 가진 데이터셋에 후진 제거를 사용하여 특성 선택을 해보겠습니다(위 그림과는 관련이 없습니다). 아래 예시에서 유의미한 성능저하를 결정하는 $R^2_\text{adj}$의 임계값은 $0.03$으로 하겠습니다. 먼저 모든 특성을 사용한 모델을 대조군으로 놓겠습니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2_\text{adj} = 0.73]
이제 특성을 하나씩 제거한 뒤에 성능을 비교합니다.
[\hat{y} = \hat{\beta_0} + \quad \qquad \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.73
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \quad \qquad \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.71
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_2}x_2 + \quad \qquad \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.64
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \quad \qquad \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.69
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \hat{\beta_4}x_4\quad \qquad \qquad R^2_\text{adj} = 0.66\]
$x_1$특성을 제거한 모델이 가장 높은 성능을 보였으며 $R^2_\text{adj}$이 임계값보다 적은 성능저하를 보였으므로 이 모델을 대조군으로 사용한 뒤에 동일한 과정을 반복합니다.
[\hat{y} = \hat{\beta_0} + \quad \qquad \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.69
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \quad \qquad \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.67
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \quad \qquad \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.71
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 \quad \qquad \qquad R^2\text{adj} = 0.70]
$x_4$특성을 제거한 모델이 가장 높은 성능을 보였으며 $R^2_\text{adj}$이 임계값보다 적은 성능저하를 보였으므로 이 모델을 대조군으로 사용한 뒤에 동일한 과정을 반복합니다.
[\hat{y} = \hat{\beta_0} + \quad \qquad \hat{\beta_3}x_3 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.66
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \quad \qquad \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.54
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 \quad \qquad \qquad R^2_\text{adj} = 0.56]
$x_4$특성을 제거한 모델이 가장 높은 성능을 보였지만, 이 모델의 $R^2_\text{adj}$은 대조군에 비하여 임곗값보다 더 많이 감소한 것을 볼 수 있습니다. 그렇기 때문에 대조군에 해당하는 $\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \hat{\beta_5}x_5$을 최종 모델로 선택합니다.
Stepwise Selection
전진 선택에서는 한 번 선택된 특성은 제거되지 않고, 후진 제거에서는 한 번 제거된 특성은 다시 선택되지 않습니다. 그렇기 때문에 두 방법 모두 더 많은 특성 조합에 대해 모델을 평가할 수 없다는 단점을 가지고 있습니다. Stepwise selection은 전진 선택과 후진 제거 방식을 매 단계마다 반복하여 적용하는 방식입니다. 이전 두 방법보다는 더 오래 걸리지만 최적의 변수 조합을 찾을 확률이 높습니다. Stepwise selection을 시간-성능 그래프에 표시하면 아래와 같이 나타나게 됩니다.

전진 선택과 후진 제거를 단계별로(Stepwise) 반복하여 적용할 뿐 특별히 다른 방식을 적용하지는 않습니다. 5개의 특성을 가지고 있는 데이터셋에 Stepwise selection을 적용하여 특성 선택을 진행해보겠습니다. 먼저 전진 선택을 적용합니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.32\
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.45
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 \qquad R^2\text{adj} = 0.53
\hat{y} = \hat{\beta_0} + \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.35
\hat{y} = \hat{\beta_0} + \hat{\beta_5}x_5 \qquad R^2_\text{adj} = 0.46]
가장 성능이 좋은 모델을 선택합니다. 이어 선택된 모델 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3$에 후진 제거를 적용하면 제거할 특성이 하나뿐이므로 제대로 적용되지 않습니다. 다시 전진 선택을 수행하겠습니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.55
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.58
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.71
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.66]
성능이 가장 좋은 모델은 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4$ 입니다. 이 모델에 후진 제거를 수행하면 어차피 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3$이 선택될 것이므로 제대로 적용되지는 않습니다. 다시 전진 선택을 수행하겠습니다. (예시를 위해서 전진 선택에서의 예시와 다른 $R^2_\text{adj}$값을 사용하겠습니다)
[\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.75
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.70
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_3}x_5 \qquad R^2_\text{adj} = 0.69]
성능이 가장 좋은 모델은 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_1}x_1$ 입니다. 이 단계부터는 후진 제거가 제대로 작동하게 됩니다. 이 모델을 대조군으로 두고 후진 제거를 수행해보겠습니다. 전진 선택과 후진 제거의 종료 기준이 되는 임계값은 여전히 위와 같은 $0.03$으로 하겠습니다.
[\hat{y} = \hat{\beta_0} + \quad \qquad \hat{\beta_3}x_3 + \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.70
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \quad \qquad \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.54
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_3}x_3 \quad \qquad \qquad R^2_\text{adj} = 0.73]
최고 성능을 보이는 $\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_3}x_3$모델의 성능은 후진 제거 임계값보다 더 적게 감소되었으므로 반복을 멈추지 않고 다시 전진 선택을 수행하면 됩니다. 이렇게 전진 선택과 후진 제거를 한 번씩 적용하여도 특성의 변화가 없을 때까지 알고리즘을 반복하면 됩니다. 이 방법은 전진 선택이나 후진 제거가 가지고 있던 “한 번 선택된 변수를 제거하지 않음, 한 번 제거된 변수를 선택하지 않음”의 문제를 해결해 준다는 장점을 가지고 있습니다.
해당 게시물은 고려대학교 강필성 교수님의 강의를 바탕으로 작성한 것입니다.
Wrapper
래퍼(Wrapper)는 특성 선택(Feature selection)에 속하는 방법 중 하나로, 반복되는 알고리즘을 사용하는 지도 학습 기반의 차원 축소법입니다. 래퍼 방식에는 전진 선택(Forward selection), 후진 제거(Backward elimination), Stepwise selection 방식 뿐만아니라 유전 알고리즘(Genetic algorithm) 방식도 사용됩니다. 이번 게시물에서는 각 방법들에 대해 자세히 알아보겠습니다.
Exhaustive Search
완전 탐색(Exhaustive search)은 모든 특성 선택 방법 중 가장 단순한 방식입니다. 예를 들어, 특성이 3개 $x_1,x_2,x_3$인 데이터가 있다고 해보겠습니다. 이 때 완전 탐색 방법을 사용하면 다음의 특성 조합에 대해 모델을 모두 실험해보고 가장 성능이 좋은 것을 고릅니다.
[f(x_1),f(x_2),f(x_3),f(x_1,x_2),f(x_1,x_3),f(x_2,x_3),f(x_1,x_2,x_3)]
완전 탐색 방식의 가장 좋은 점은 언제나 Global optimum(전역 최적점)을 찾을 수 있다는 점입니다. 순서에 상관없이 모든 특성 조합에 대하여 모델을 시험해 보기 때문에 Local optimum(지역 최적점)에 빠질 우려가 없습니다.
하지만 완전 탐색을 사용하면 데이터셋의 특성이 $n$개 일 때, $2^n-1$ 만큼의 모델을 평가해야 합니다. 위의 예에서도 3개의 특성을 기준으로 완전 탐색을 사용하였더니 $2^3-1 = 7$개의 모델을 평가하였습니다. 특성의 개수에 대하여 지수적으로 증가하므로 특성의 개수가 늘어나면 모델 평가 횟수가 엄청나게 많아지게 됩니다. $n=30$ 이라면 $2^{30}-1$ 회, 즉 10억 번 이상의 모델 평가를 수행해야 합니다. 이런 이유에서 완전 탐색 방식은 현실적으로 사용 불가능합니다.
앞으로 알아볼 다른 알고리즘과 비교하기 위해서 시간-성능 그래프에 완전 탐색을 나타내어 보겠습니다. 완전 탐색은 최고의 성능을 보여주지만 최고 오랜 시간을 필요로하기 때문에 아래와 같이 나타낼 수 있습니다.
Forward Selection / Backward Elimination
다음으로 전진 선택과 후진 제거를 알아보겠습니다. 이 두 방법은 성능을 어느 정도 유지하면서 전역 탐색에서 걸리는 시간을 극적으로 줄인 방법입니다. 시간-성능 그래프에 두 방법을 나타내면 다음과 같이 나타낼 수 있습니다.
Forward Selection
전진 선택(Forward selection)은 가장 유의미한 특성을 선택해나가는 방식 입니다. 아무런 특성이 없는 상태부터 시작해서 특성을 늘려나가는 방향(Forward)으로 나아갑니다. 매 단계마다 가장 성능이 좋은 특성을 선택한 뒤에 유의미한 성능이 없을 때까지 이 과정을 실행해 나갑니다. 아래는 전진 선택의 과정을 나타낸 이미지입니다.
이미지 출처 : quantifyinghealth.com
특성이 5개 $x_1,x_2,x_3,x_4,x_5$인 데이터셋에 전진 선택 방식을 적용하여 특성 선택을 해보겠습니다(위 그림과는 관련이 없습니다). 먼저 1개의 특성만 가지는 모델의 성능을 비교합니다. 비교 성능으로는 조정된 결정계수(adjusted R-squared, $R^2_\text{adj}$)를 사용하겠습니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.32\
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.45
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 \qquad R^2\text{adj} = 0.53
\hat{y} = \hat{\beta_0} + \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.35
\hat{y} = \hat{\beta_0} + \hat{\beta_5}x_5 \qquad R^2_\text{adj} = 0.46]
$x_3$을 선택했을 때의 성능이 가장 좋으므로 이 특성을 고정한 뒤에 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3$ 을 대조군으로 놓고 동일한 과정을 반복합니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.55
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.58
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.71
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.66]
$x_4$의 특성을 추가적으로 선택했을 때의 성능이 가장 좋으므로 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4$ 를 대조군으로 놓고 동일한 과정을 반복합니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.71
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.70
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_3}x_5 \qquad R^2_\text{adj} = 0.69]
$x_1,x_2,x_5$중에서 어떤 특성을 추가하더라도 대조군인 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4$ 보다 성능이 좋아지지 않았으므로 여기서 과정을 멈추고 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4$ 을 특성 선택의 결과물로 선정합니다.
Backward Elimination
후진 제거(Backward elimination)는 무의미한 특성을 제거해나가는 방식 입니다. 반대로 모든 특성을 가진 모델에서 시작하여 특성을 하나씩 줄여나가는 방향(Backward)으로 나아갑니다. 특성을 제거했을 때 가장 성능이 좋은 모델을 선택함며 유의미한 성능 저하가 나타날 때까지 이 과정을 반복합니다. 아래는 후진 제거의 과정을 나타낸 이미지입니다.
이미지 출처 : quantifyinghealth.com
동일하게 5개의 특성을 가진 데이터셋에 후진 제거를 사용하여 특성 선택을 해보겠습니다(위 그림과는 관련이 없습니다). 아래 예시에서 유의미한 성능저하를 결정하는 $R^2_\text{adj}$의 임계값은 $0.03$으로 하겠습니다. 먼저 모든 특성을 사용한 모델을 대조군으로 놓겠습니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2_\text{adj} = 0.73]
이제 특성을 하나씩 제거한 뒤에 성능을 비교합니다.
[\hat{y} = \hat{\beta_0} + \quad \qquad \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.73
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \quad \qquad \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.71
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_2}x_2 + \quad \qquad \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.64
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \quad \qquad \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.69
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \hat{\beta_4}x_4\quad \qquad \qquad R^2_\text{adj} = 0.66\]
$x_1$특성을 제거한 모델이 가장 높은 성능을 보였으며 $R^2_\text{adj}$이 임계값보다 적은 성능저하를 보였으므로 이 모델을 대조군으로 사용한 뒤에 동일한 과정을 반복합니다.
[\hat{y} = \hat{\beta_0} + \quad \qquad \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.69
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \quad \qquad \hat{\beta_4}x_4 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.67
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \quad \qquad \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.71
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 \quad \qquad \qquad R^2\text{adj} = 0.70]
$x_4$특성을 제거한 모델이 가장 높은 성능을 보였으며 $R^2_\text{adj}$이 임계값보다 적은 성능저하를 보였으므로 이 모델을 대조군으로 사용한 뒤에 동일한 과정을 반복합니다.
[\hat{y} = \hat{\beta_0} + \quad \qquad \hat{\beta_3}x_3 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.66
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \quad \qquad \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.54
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 \quad \qquad \qquad R^2_\text{adj} = 0.56]
$x_4$특성을 제거한 모델이 가장 높은 성능을 보였지만, 이 모델의 $R^2_\text{adj}$은 대조군에 비하여 임곗값보다 더 많이 감소한 것을 볼 수 있습니다. 그렇기 때문에 대조군에 해당하는 $\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 + \hat{\beta_3}x_3 + \hat{\beta_5}x_5$을 최종 모델로 선택합니다.
Stepwise Selection
전진 선택에서는 한 번 선택된 특성은 제거되지 않고, 후진 제거에서는 한 번 제거된 특성은 다시 선택되지 않습니다. 그렇기 때문에 두 방법 모두 더 많은 특성 조합에 대해 모델을 평가할 수 없다는 단점을 가지고 있습니다. Stepwise selection은 전진 선택과 후진 제거 방식을 매 단계마다 반복하여 적용하는 방식입니다. 이전 두 방법보다는 더 오래 걸리지만 최적의 변수 조합을 찾을 확률이 높습니다. Stepwise selection을 시간-성능 그래프에 표시하면 아래와 같이 나타나게 됩니다.
전진 선택과 후진 제거를 단계별로(Stepwise) 반복하여 적용할 뿐 특별히 다른 방식을 적용하지는 않습니다. 5개의 특성을 가지고 있는 데이터셋에 Stepwise selection을 적용하여 특성 선택을 진행해보겠습니다. 먼저 전진 선택을 적용합니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.32\
\hat{y} = \hat{\beta_0} + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.45
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 \qquad R^2\text{adj} = 0.53
\hat{y} = \hat{\beta_0} + \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.35
\hat{y} = \hat{\beta_0} + \hat{\beta_5}x_5 \qquad R^2_\text{adj} = 0.46]
가장 성능이 좋은 모델을 선택합니다. 이어 선택된 모델 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3$에 후진 제거를 적용하면 제거할 특성이 하나뿐이므로 제대로 적용되지 않습니다. 다시 전진 선택을 수행하겠습니다.
[\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.55
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.58
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.71
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_5}x_5 \qquad R^2\text{adj} = 0.66]
성능이 가장 좋은 모델은 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4$ 입니다. 이 모델에 후진 제거를 수행하면 어차피 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3$이 선택될 것이므로 제대로 적용되지는 않습니다. 다시 전진 선택을 수행하겠습니다. (예시를 위해서 전진 선택에서의 예시와 다른 $R^2_\text{adj}$값을 사용하겠습니다)
[\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_1}x_1 \qquad R^2\text{adj} = 0.75
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_2}x_2 \qquad R^2\text{adj} = 0.70
\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_3}x_5 \qquad R^2_\text{adj} = 0.69]
성능이 가장 좋은 모델은 $\hat{y} = \hat{\beta_0} + \hat{\beta_3}x_3 + \hat{\beta_4}x_4 + \hat{\beta_1}x_1$ 입니다. 이 단계부터는 후진 제거가 제대로 작동하게 됩니다. 이 모델을 대조군으로 두고 후진 제거를 수행해보겠습니다. 전진 선택과 후진 제거의 종료 기준이 되는 임계값은 여전히 위와 같은 $0.03$으로 하겠습니다.
[\hat{y} = \hat{\beta_0} + \quad \qquad \hat{\beta_3}x_3 + \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.70
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \quad \qquad \hat{\beta_4}x_4 \qquad R^2\text{adj} = 0.54
\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_3}x_3 \quad \qquad \qquad R^2_\text{adj} = 0.73]
최고 성능을 보이는 $\hat{y} = \hat{\beta_0} + \hat{\beta_1}x_1 + \hat{\beta_3}x_3$모델의 성능은 후진 제거 임계값보다 더 적게 감소되었으므로 반복을 멈추지 않고 다시 전진 선택을 수행하면 됩니다. 이렇게 전진 선택과 후진 제거를 한 번씩 적용하여도 특성의 변화가 없을 때까지 알고리즘을 반복하면 됩니다. 이 방법은 전진 선택이나 후진 제거가 가지고 있던 “한 번 선택된 변수를 제거하지 않음, 한 번 제거된 변수를 선택하지 않음”의 문제를 해결해 준다는 장점을 가지고 있습니다.