
선형 회귀 (Linear Regression)
07 Apr 2020 | Machine-Learning
본 포스트는 문일철 교수님의 인공지능 및 기계학습 개론 I 강의를 바탕으로 작성하였습니다.
Linear Regression
이번에는 레이블이 “예”, “아니오” 와 같은 범주형(Categorical) 변수가 아니라 연속형(Continuous)인 인스턴스로 구성된 데이터셋에 대해 알아보도록 합시다. 이런 데이터는 선형의 형태를 가지고 있다고 추측해볼 수 있습니다. 아래 이미지를 보며 설명을 이어나가도록 하겠습니다.

이미지 출처 : 위키피디아 - 선형회귀
위 그림에서 파란색 점은 각 데이터의 연속형인 레이블을 마크한 것이고, 빨간색 선은 파란색 점과 가장 잘 부합하는 하나의 직선(혹은 곡선)입니다. 이번 게시물에서는 특정 데이터셋의 특성(Feature)과 레이블간에 선형(Linear)의 관계가 있다는 가설을 세웠을 때 이 선형의 그래프를 예측해보는 선형회귀(Linear Regression) 에 대해서 알아봅시다.
가장 기본적인 선형 회귀는 직선의 형태를 가지므로 기울기를 나타내는 파라미터를 $\theta_i (i \geq 1)$ 라고 하고 편향(Bias)을 나타내는 파라미터를 $\theta_0$ 라고 하면 속성값 $x_i$ 에 대한 회귀 가설식 $h$ 을 아래와 같이 나타낼 수 있습니다.
\[h:\hat{f}(x;\theta) = \theta_0 + \sum_{i=1}^n \theta_i x_i = \sum_{i=0}^n \theta_i x_i\]
위 식에서 속성값에 해당하는 $x_i$ 는 데이터로부터 주어져 있습니다. 그렇기 때문에 우리의 목표는 데이터에 더 잘 부합하는 적절한 $\theta$ 를 찾아 좋은 가설을 만드는 것이 되겠습니다.
Find $\theta$ , 최소제곱법
최소제곱법(Least Squared Method) 은 가장 적절한 $\theta$ 를 찾는 방법 중 하나입니다. 최소 제곱법은 정규방정식이라는 행렬 연산을 기반으로 합니다. 위에서 사용한 가설식 $h$ 를 행렬을 사용하여 간단하게 나타내 봅시다. 아래 식에서 각 행(Row)은 인스턴스의 특성값을 나타내며, $D$ 는 데이터셋 내에 있는 행의 개수가 됩니다.
\[h: \hat{f}(x;\theta) = \sum_{i=0}^n \theta_i x_i \rightarrow \hat{f} = X \theta \\
X = \left(\begin{array}{cccc} 1 & x^1_1 & \cdots & x^1_n \\ \vdots & \vdots & \ddots & \vdots \\ 1 & x^D_1 & \cdots & x_n^D \end{array}\right), \theta = \left(\begin{array}{c} \theta_0 \\ \theta_1 \\ \vdots \\ \theta_n \end{array}\right)\]
규칙 기반 학습 에서도 알아보았던 것처럼 현실 세계는 완벽한 세계(Perfect world)와는 달리 다양한 노이즈가 존재합니다. 그렇기 때문에 현실 세계를 근사하는 함수 $f (\neq \hat{f})$ 에는 에러 $e$ 에 대한 항을 포함하여 나타냅니다.
\[f(x;\theta) = \sum_{i=0}^n \theta_i x_i + e = y \rightarrow f = X \theta + e = Y\]
우리의 목표는 $\theta$ 를 조정하여 노이즈로부터 발생하는 에러 $e$ 를 최소화하는 것입니다. $\text{argmin}$ 을 사용하여 수식으로 이를 표현하면 다음과 같습니다.
\[\hat{\theta} = \text{argmin}_\theta (e)^2 = \text{argmin}_\theta (f - \hat{f})^2\]
$f, \hat{f}$ 에 $Y, X\theta$ 를 각각 대입한 뒤 다음과 같이 변형할 수 습니다. 마지막에 등장하는 $Y^T Y$ 는 $\theta$ 값이 변해도 변하지 않는 상수(Constant)기 때문에 $\text{argmin}$ 이후의 식에서 삭제해 주어도 문제가 되지 않습니다.
\(\begin{aligned}
\hat{\theta} &= \text{argmin}_\theta (e)^2 = \text{argmin}_\theta (f - \hat{f})^2 \\
&= \text{argmin}_\theta (Y - X\theta)^2 = \text{argmin}_\theta (Y - X\theta)^T (Y - X\theta) = \text{argmin}_\theta (Y^T - \theta^TX^T) (Y - X\theta) \\
&= \text{argmin}_\theta (\theta^TX^TX\theta - 2\theta^TX^TY + Y^T Y) = \text{argmin}_\theta (\theta^TX^TX\theta - 2\theta^TX^TY)
\end{aligned}\)
다음으로 $\text{argmin}$ 이하의 행렬식을 $\theta$ 에 대해 미분한 뒤 그 값이 $0$ 이 되는 $\theta$ 를 찾아내어 $\hat{\theta}$ 를 구할 수 있습니다.
\[\begin{aligned}
\nabla_\theta (\theta^TX^TX\theta - 2\theta^TX^TY) = 0 \\
2X^TX\theta - 2X^TY = 0 \\
\therefore \theta = (X^TX)^{-1}X^TY
\end{aligned}\]
최소제곱법 덕분에 우리는 데이터셋이 주어지면 인스턴스의 특성값으로 구성된 행렬 $X$ 와 실제 레이블로 구성된 행렬 $Y$ 를 만든 뒤, 해당 데이터셋을 가장 잘 근사하는 선형 함수의 파라미터 $\theta$ 를 구해낼 수 있게 되었습니다.
하지만 간단해 보이는 최소제곱법에도 단점이 있습니다. 해당 알고리즘이 행렬 연산에 기반한 방식이기 때문에 특성 수에 따라 복잡도가 엄청나게 늘어나게 됩니다. 최소제곱법의 복잡도는 아래와 같습니다.
최소제곱법의 복잡도
인스턴스(샘플)의 개수 $m$
특성의 개수 $n$
빅 - $O$ 표기법
$O(m)$
$O(n^{2.4} \sim n^3)$
위 표로부터 최소제곱법 알고리즘의 복잡도가 샘플의 개수에는 큰 영향을 받지 않지만, 특성의 개수에는 상당히 큰 영향을 받고 있음을 알 수 있습니다. 분석할 데이터셋이 인스턴스의 개수만 많고 특성의 개수는 적다면 최소제곱법을 사용하는 것이 올바른 방법이 되겠습니다. 하지만 인스턴스가 수십 ~ 수백개 이상의 특성을 가지고 있다면 최소제곱법을 사용하는 것은 너무 많은 시간과 컴퓨팅 자원을 필요로 하게 됩니다. 이런 데이터셋을 분석하기 위해서는 특성의 개수에 큰 영향을 받지 않는 다른 알고리즘을 사용해야 합니다. 다음으로 그런 알고리즘인 경사 하강법에 대해 알아봅시다.
Gradient Descent, 경사 하강법
경사 하강법(Gradient Descent) 은 최소제곱법과 같이 최적의 $\theta$ 를 찾아가는 알고리즘입니다. 경사 하강법에는 비용 함수(Cost function) 라는 개념이 등장합니다. 비용 함수 마다 약간의 차이가 있기는 하지만 큰 범주에서는 예측값과 실제값의 차이, 즉 $f - \hat{f}$ 라고 할 수 있습니다. 우리는 실제값과 가장 유사한 예측값을 알아내는 것이 목적이므로 비용 함수를 최소화하는 방향으로 파라미터 $\theta$ 를 조정해나가게 됩니다. 아래는 경사 하강법이 진행되는 과정을 이미지로 나타낸 것입니다.
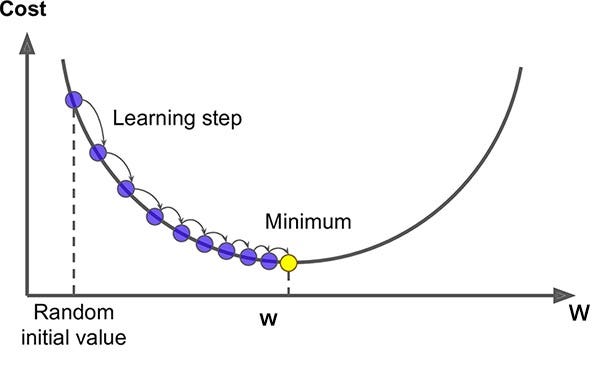
이미지 출처 : mc.ai
경사 하강법에 본격적으로 들어가기 전에 선형 회귀에서 가장 흔히 사용되는 비용 함수인 평균 제곱 오차(Mean square error, MSE) 에 대해 알아봅시다. 평균 제곱 오차의 수식은 아래와 같습니다. 아래 식에서 $m$ 은 인스턴스의 개수를, $i$ 는 행의 인덱스를 나타냅니다.
\[MSE(X, h_\theta) = \frac{1}{m} \sum^m_{i=1} (\theta^T \cdot x^i - y^i)^2\]
평균 제곱 오차의 식을 보면 실제 오차를 제곱하여 더해준 뒤 평균을 구한 값임을 알 수 있습니다. 비록 오차에 제곱을 해주었지만, 우리의 목표는 오차를 정확하게 구하는 것이 아니라 오차를 최소화하는 것입니다. 그렇기 때문에 미분 계산이 더 용이한 평균 제곱 오차를 가장 많이 사용합니다.
이제 본격적으로 경사 하강법을 알아보기 위한 모든 준비가 끝났습니다. 가장 기본적인 경사 하강법에 해당하는 배치 경사 하강법(Batch Gradient Descent) 부터 알아보도록 합시다. 경사 하강법에서 가장 중요한 것은 경사, 즉 그래디언트를 계산하는 것입니다. 우리가 사용할 비용 함수인 평균 제곱 오차에 대한 파라미터 $\theta$ 의 그래디언트는 편도함수(Partial derivative) 를 이용하여 구할 수 있습니다. 편도함수의 수식은 아래와 같습니다.
\[\frac{\partial}{\partial \theta_j}MSE(\theta) = \frac{2}{m}\sum_{i=1}^{m}(\theta^T \cdot x^i - y^i)x^i_j\]
위 식은 각각의 파라미터 $\theta_j$ 에 대한 편도함수를 나타낸 것입니다. 그래디언트 벡터를 사용하면 이 식을 모든 파라미터에 대하여 행렬식으로 쓸 수 있습니다. 그래디언트 벡터를 사용하여 나타내 보겠습니다.
\[\nabla_\theta MSE(\theta) = \left[\begin{array}{c} \frac{\partial}{\partial \theta_0}MSE(\theta) \\ \frac{\partial}{\partial \theta_1}MSE(\theta) \\ \vdots \\ \frac{\partial}{\partial \theta_n}MSE(\theta) \end{array}\right] = \frac{2}{m}\mathbf{X}^T \cdot (\mathbf{X} \cdot \theta - \mathbf{y})\]
이제 그래디언트를 구할 수 있게 되었습니다. 이제는 이 그래디언트를 우리의 목표에 맞게 사용하기 위해 목표를 다시 상기시켜 봅시다. 우리의 목표는 비용 함수가 최소가 되는 점, 즉 아래 그림에서 $\theta^\star$ 에 해당하는 점을 찾는 것이었습니다. 아래 그림을 보면 $\theta_0$ 에서 시작하여 $\theta^\star$ 까지 $\theta_1, \theta_2, \theta_3$ 으로 나아갈수록 그래디언트(기울기)가 점점 감소하는 것을 볼 수 있습니다. 그렇기 때문에 우리는 그래디언트(경사)가 $0$ 이 되는 순간까지 감소하는 방향으로 나아가야 합니다.

이미지 출처 : researchgate.net
이를 수식으로 나타내면 아래와 같습니다.
\[\theta^{d+1} = \theta^d - \eta \cdot \nabla_\theta MSE(\theta)\]
위 식에서 새로운 항 $\eta$ 가 등장했습니다. 학습률(Learning rate) 을 나타내는 $\eta$ 는 경사 하강법에서 가장 중요한 하이퍼파라미터(hyperparameter, 사용자 지정 매개변수) 중 하나입니다. 학습률은 경사 하강법에서 보폭의 크기를 지정하는 것으로 사용자가 지정한 값에 따라 달라지게 됩니다. 아래의 이미지를 참고하여 설명을 이어나가겠습니다.
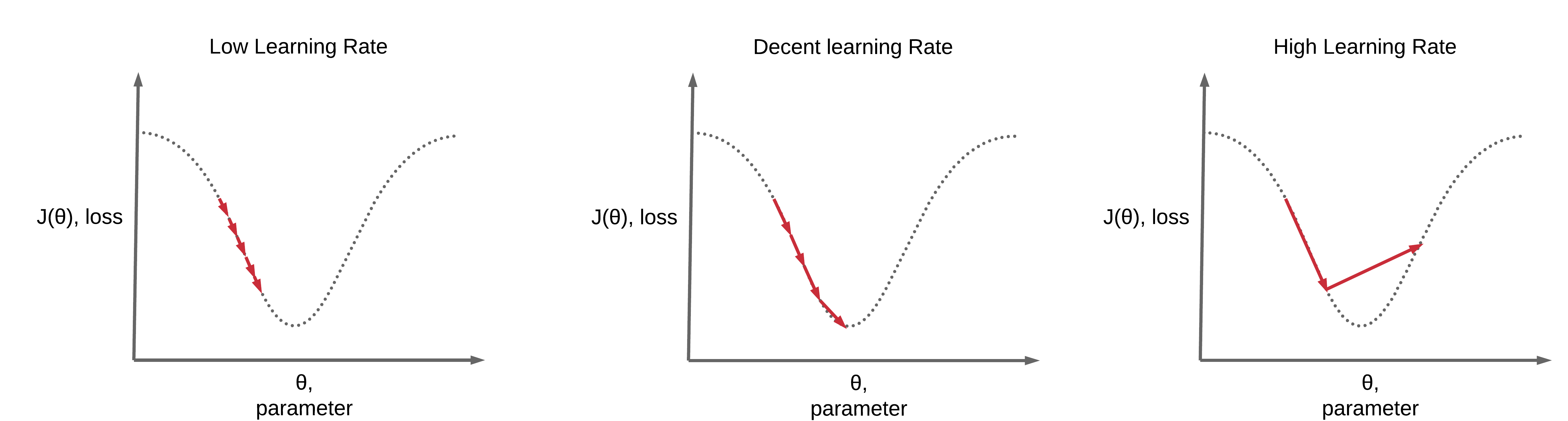
이미지 출처 : deeplearningwizard.com
위 그림에서 왼쪽은 학습률을 너무 작게 설정한 경우입니다. 학습률이 너무 작으면 특정 반복횟수 내에서 최소점을 찾지 못하는 경우가 있습니다. 물론 반복을 계속하게 되면 최소점에 다다를 수 있겠지만 너무 많은 시간과 컴퓨팅 자원을 소비하게 됩니다. 반대로 오른쪽은 학습률을 너무 크게 설정한 경우입니다. 학습률이 크면 빠르게 최소점으로 다가갈 수 있지만 진행 도중에 최소점을 지나쳐버리는 사고가 발생할 수 있습니다. 이런 문제 때문에 여러 학습률을 설정해보면서 가장 적절한 학습률을 찾아야 합니다. 경우에 따라서는 아래 그림과 같이 처음에는 학습률을 크게 설정한 뒤 점점 감소시켜 나가는 학습률 감소(Learning rate decay) 방법을 사용하기도 합니다. (아래 그림에서 학습률 감소 방법을 사용했을 때에 고정된 학습률을 사용했을 때보다 더 적은 반복수로 최솟값에 다다르는 것을 볼 수 있습니다)
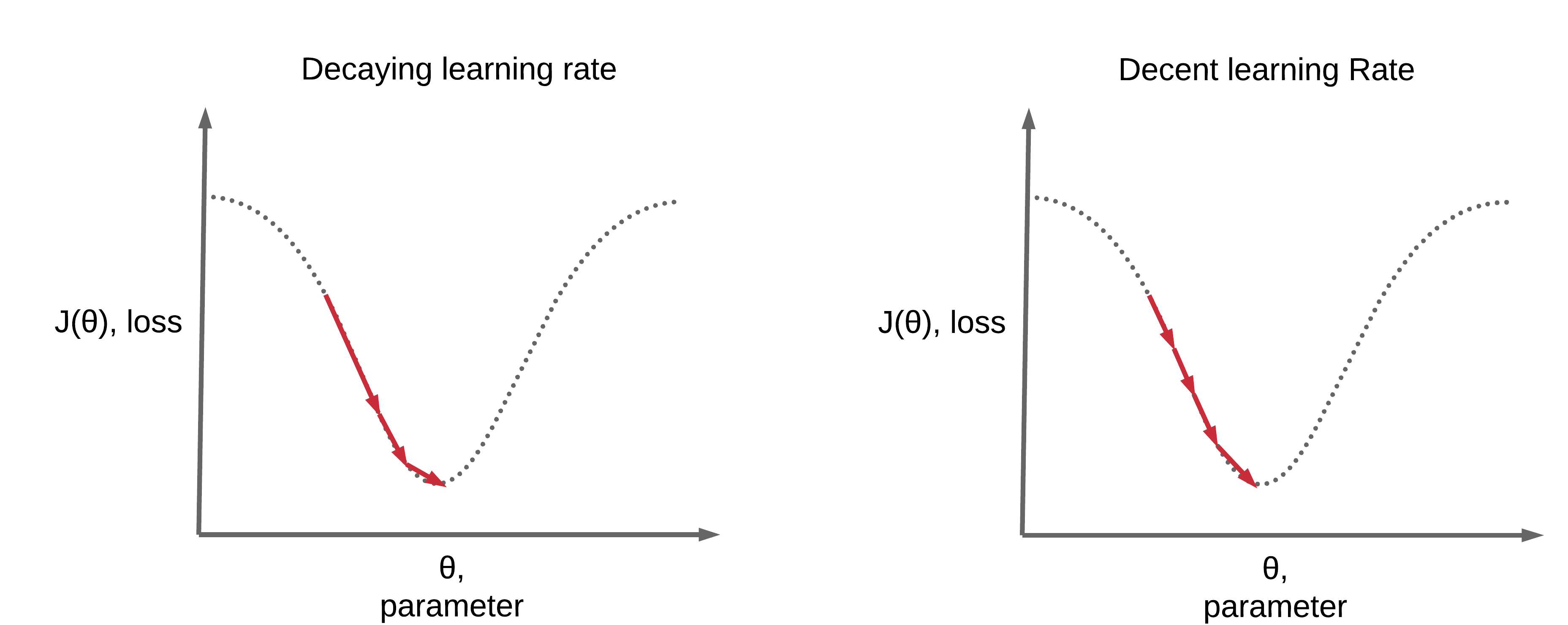
이미지 출처 : deeplearningwizard.com
배치 경사 하강법의 가장 큰 문제는 매번 모든 데이터셋에 대해 그래디언트를 계산한다는 점입니다. 인스턴스의 개수가 많은 데이터셋에 배치 경사 하강법을 적용할 경우 시간이 오래 걸리고 컴퓨팅 자원을 많이 소모하게 됩니다. 확률적 경사 하강법(Stochastic Gradient Descent, SGD) 은 이러한 문제를 개선하기 위한 알고리즘입니다. 확률적 경사 하강법에서는 매 스텝마다 한 개의 샘플을 무작위로 선택한 뒤 하나의 샘플에 대해 그래디언트를 계산합니다. 반복마다 사용되는 인스턴스의 숫자가 하나뿐이기 때문에 훨씬 빠른 속도로 계산을 해낼 수 있습니다. 하지만 인스턴스를 랜덤하게 하나만 선택하기 때문에 배치 경사 하강법보다 불안정하다는 단점이 있습니다.
랜덤하게 선택하지만 매번 다른 인스턴스를 선택하므로 데이터셋 내에 있는 인스턴스 개수 $m$ 만큼 반복할 경우에는 데이터셋을 모두 살피게 됩니다. 이 때 $m$ 번 만큼의 반복을 에포크(Epoch) 라고 합니다. 예를 들어, $1000$ 개의 인스턴스로 구성된 데이터셋에 확률적 경사 하강법을 사용하여 그래디언트를 개선하는 과정을 $10000$ 번 시행한다고 합시다. 이 경우에는 총 $10000 / 1000 = 10$ 에포크 만큼 반복한 것입니다.
미니배치 경사 하강법(Mini-batch Gradient Descent) 은 두 방법의 절충안에 해당하는 경사 하강법 방식입니다. 전체 데이터셋을 사용하거나 하나의 인스턴스만을 선택하지 않고 작은 샘플 세트를 구성하여 경사하강법 알고리즘을 진행해 나가는 방식입니다.
아래는 최소제곱법과 각각의 경사 하강법에 대해 특징을 표로 나타낸 것입니다.
알고리즘
샘플 수가 클 때
특성 수가 클 때
외부 메모리 학습 지원
스케일 조정 필요
하이퍼 파라미터 수
최소제곱법
빠름
느림
X
X
0
배치 경사 하강법
느림
빠름
X
O
2
확률적 경사 하강법
빠름
빠름
O
O
>=2
미니배치 경사 하강법
빠름
빠름
O
O
>=2
Polynomial, 다항 회귀
모든 데이터셋이 직선의 형태를 보이는 것은 아닙니다. 아래 그림을 보며 설명을 이어가도록 하겠습니다.
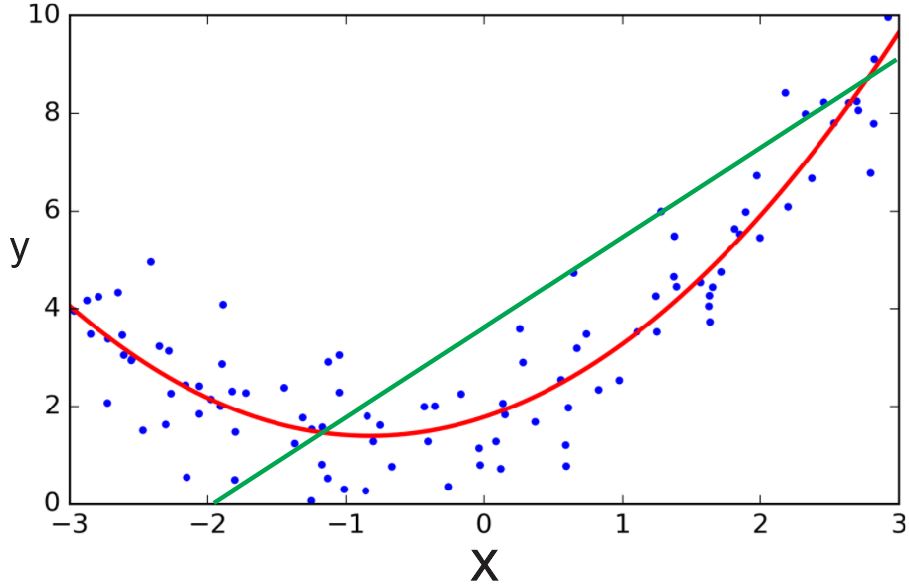
이미지 출처 : animoidin.wordpress.com
위 그림에서 초록색 직선은 $-2$ 보다 오른쪽에 위치한 데이터는 잘 근사하는 듯하지만, 왼쪽에 위치한 데이터셋은 잘 근사하고 있지 못합니다. 그에 비해 빨간색 포물선은 모든 데이터셋을 그럴듯하게 근사하고 있음을 알 수 있습니다. 다항 회귀(Polynomial Regression) 는 이렇게 직선보다 복잡한 형태를 보이는 데이터를 근사하는 알고리즘 입니다.
다항 회귀는 특성 끼리의 곱이나 한 특성의 거듭제곱을 새로운 특성으로 추가하여 선형 모델을 훈련시킵니다. 예를 들어, 특성이 두 개 $x_1, x_2$ 인 데이터에 새로운 항없이 근사하면 다음 수식과 같은 함수가 됩니다.
\[\hat{f_1} = \theta_0 + \theta_1x_1 + \theta_2x_2\]
하지만 서로 특성끼리 곱하거나 자기 자신을 제곱함으로써 아래 수식과 같이 데이터의 차원을 늘려줄 수 있습니다.
\[\hat{f_2} = \theta_0 + \theta_1x_1 + \theta_2x_2 + \theta_3x_1^2 + \theta_4x_1x_2 + \theta_5x_2^2\]
위와 같이 차원이 높은 근사 함수는 낮은 차원의 근사함수보다 훈련 데이터에 더 잘 맞게됩니다. 특히 데이터의 갯수보다 파라미터의 개수가 같거나 많으면 훈련 데이터에 대해서 $100\%$ 의 정확도를 보입니다. 하지만 이럴 경우 훈련 데이터가 아닌 새로운 데이터에는 맞지 않는 현상이 일어납니다. 이런 현상을 과적합(Overfitting)이라고 합니다. 그렇기 때문에 우리는 “훈련 데이터에 어느정도 잘 맞되, 새로운 데이터에도 잘 맞도록” 차원을 조정해야 합니다. 이를 편향-분산 트레이드오프(Bias - Variance Trade-off) 라 하며 이곳 에서 더욱 자세한 내용을 볼 수 있습니다. 머신러닝에서 과적합은 피해야 할 커다란 문제입니다. 그렇기 때문에 교차 검증(Cross validation)1 을 통한 학습 곡선(Learning curve)2 을 사용하여 과적합을 방지합니다.

본 포스트는 문일철 교수님의 인공지능 및 기계학습 개론 I 강의를 바탕으로 작성하였습니다.
Linear Regression
이번에는 레이블이 “예”, “아니오” 와 같은 범주형(Categorical) 변수가 아니라 연속형(Continuous)인 인스턴스로 구성된 데이터셋에 대해 알아보도록 합시다. 이런 데이터는 선형의 형태를 가지고 있다고 추측해볼 수 있습니다. 아래 이미지를 보며 설명을 이어나가도록 하겠습니다.
이미지 출처 : 위키피디아 - 선형회귀
위 그림에서 파란색 점은 각 데이터의 연속형인 레이블을 마크한 것이고, 빨간색 선은 파란색 점과 가장 잘 부합하는 하나의 직선(혹은 곡선)입니다. 이번 게시물에서는 특정 데이터셋의 특성(Feature)과 레이블간에 선형(Linear)의 관계가 있다는 가설을 세웠을 때 이 선형의 그래프를 예측해보는 선형회귀(Linear Regression) 에 대해서 알아봅시다.
가장 기본적인 선형 회귀는 직선의 형태를 가지므로 기울기를 나타내는 파라미터를 $\theta_i (i \geq 1)$ 라고 하고 편향(Bias)을 나타내는 파라미터를 $\theta_0$ 라고 하면 속성값 $x_i$ 에 대한 회귀 가설식 $h$ 을 아래와 같이 나타낼 수 있습니다.
\[h:\hat{f}(x;\theta) = \theta_0 + \sum_{i=1}^n \theta_i x_i = \sum_{i=0}^n \theta_i x_i\]위 식에서 속성값에 해당하는 $x_i$ 는 데이터로부터 주어져 있습니다. 그렇기 때문에 우리의 목표는 데이터에 더 잘 부합하는 적절한 $\theta$ 를 찾아 좋은 가설을 만드는 것이 되겠습니다.
Find $\theta$ , 최소제곱법
최소제곱법(Least Squared Method) 은 가장 적절한 $\theta$ 를 찾는 방법 중 하나입니다. 최소 제곱법은 정규방정식이라는 행렬 연산을 기반으로 합니다. 위에서 사용한 가설식 $h$ 를 행렬을 사용하여 간단하게 나타내 봅시다. 아래 식에서 각 행(Row)은 인스턴스의 특성값을 나타내며, $D$ 는 데이터셋 내에 있는 행의 개수가 됩니다.
\[h: \hat{f}(x;\theta) = \sum_{i=0}^n \theta_i x_i \rightarrow \hat{f} = X \theta \\ X = \left(\begin{array}{cccc} 1 & x^1_1 & \cdots & x^1_n \\ \vdots & \vdots & \ddots & \vdots \\ 1 & x^D_1 & \cdots & x_n^D \end{array}\right), \theta = \left(\begin{array}{c} \theta_0 \\ \theta_1 \\ \vdots \\ \theta_n \end{array}\right)\]규칙 기반 학습 에서도 알아보았던 것처럼 현실 세계는 완벽한 세계(Perfect world)와는 달리 다양한 노이즈가 존재합니다. 그렇기 때문에 현실 세계를 근사하는 함수 $f (\neq \hat{f})$ 에는 에러 $e$ 에 대한 항을 포함하여 나타냅니다.
\[f(x;\theta) = \sum_{i=0}^n \theta_i x_i + e = y \rightarrow f = X \theta + e = Y\]우리의 목표는 $\theta$ 를 조정하여 노이즈로부터 발생하는 에러 $e$ 를 최소화하는 것입니다. $\text{argmin}$ 을 사용하여 수식으로 이를 표현하면 다음과 같습니다.
\[\hat{\theta} = \text{argmin}_\theta (e)^2 = \text{argmin}_\theta (f - \hat{f})^2\]$f, \hat{f}$ 에 $Y, X\theta$ 를 각각 대입한 뒤 다음과 같이 변형할 수 습니다. 마지막에 등장하는 $Y^T Y$ 는 $\theta$ 값이 변해도 변하지 않는 상수(Constant)기 때문에 $\text{argmin}$ 이후의 식에서 삭제해 주어도 문제가 되지 않습니다. \(\begin{aligned} \hat{\theta} &= \text{argmin}_\theta (e)^2 = \text{argmin}_\theta (f - \hat{f})^2 \\ &= \text{argmin}_\theta (Y - X\theta)^2 = \text{argmin}_\theta (Y - X\theta)^T (Y - X\theta) = \text{argmin}_\theta (Y^T - \theta^TX^T) (Y - X\theta) \\ &= \text{argmin}_\theta (\theta^TX^TX\theta - 2\theta^TX^TY + Y^T Y) = \text{argmin}_\theta (\theta^TX^TX\theta - 2\theta^TX^TY) \end{aligned}\)
다음으로 $\text{argmin}$ 이하의 행렬식을 $\theta$ 에 대해 미분한 뒤 그 값이 $0$ 이 되는 $\theta$ 를 찾아내어 $\hat{\theta}$ 를 구할 수 있습니다.
\[\begin{aligned} \nabla_\theta (\theta^TX^TX\theta - 2\theta^TX^TY) = 0 \\ 2X^TX\theta - 2X^TY = 0 \\ \therefore \theta = (X^TX)^{-1}X^TY \end{aligned}\]최소제곱법 덕분에 우리는 데이터셋이 주어지면 인스턴스의 특성값으로 구성된 행렬 $X$ 와 실제 레이블로 구성된 행렬 $Y$ 를 만든 뒤, 해당 데이터셋을 가장 잘 근사하는 선형 함수의 파라미터 $\theta$ 를 구해낼 수 있게 되었습니다.
하지만 간단해 보이는 최소제곱법에도 단점이 있습니다. 해당 알고리즘이 행렬 연산에 기반한 방식이기 때문에 특성 수에 따라 복잡도가 엄청나게 늘어나게 됩니다. 최소제곱법의 복잡도는 아래와 같습니다.
| 최소제곱법의 복잡도 | 인스턴스(샘플)의 개수 $m$ | 특성의 개수 $n$ |
|---|---|---|
| 빅 - $O$ 표기법 | $O(m)$ | $O(n^{2.4} \sim n^3)$ |
위 표로부터 최소제곱법 알고리즘의 복잡도가 샘플의 개수에는 큰 영향을 받지 않지만, 특성의 개수에는 상당히 큰 영향을 받고 있음을 알 수 있습니다. 분석할 데이터셋이 인스턴스의 개수만 많고 특성의 개수는 적다면 최소제곱법을 사용하는 것이 올바른 방법이 되겠습니다. 하지만 인스턴스가 수십 ~ 수백개 이상의 특성을 가지고 있다면 최소제곱법을 사용하는 것은 너무 많은 시간과 컴퓨팅 자원을 필요로 하게 됩니다. 이런 데이터셋을 분석하기 위해서는 특성의 개수에 큰 영향을 받지 않는 다른 알고리즘을 사용해야 합니다. 다음으로 그런 알고리즘인 경사 하강법에 대해 알아봅시다.
Gradient Descent, 경사 하강법
경사 하강법(Gradient Descent) 은 최소제곱법과 같이 최적의 $\theta$ 를 찾아가는 알고리즘입니다. 경사 하강법에는 비용 함수(Cost function) 라는 개념이 등장합니다. 비용 함수 마다 약간의 차이가 있기는 하지만 큰 범주에서는 예측값과 실제값의 차이, 즉 $f - \hat{f}$ 라고 할 수 있습니다. 우리는 실제값과 가장 유사한 예측값을 알아내는 것이 목적이므로 비용 함수를 최소화하는 방향으로 파라미터 $\theta$ 를 조정해나가게 됩니다. 아래는 경사 하강법이 진행되는 과정을 이미지로 나타낸 것입니다.
이미지 출처 : mc.ai
경사 하강법에 본격적으로 들어가기 전에 선형 회귀에서 가장 흔히 사용되는 비용 함수인 평균 제곱 오차(Mean square error, MSE) 에 대해 알아봅시다. 평균 제곱 오차의 수식은 아래와 같습니다. 아래 식에서 $m$ 은 인스턴스의 개수를, $i$ 는 행의 인덱스를 나타냅니다.
\[MSE(X, h_\theta) = \frac{1}{m} \sum^m_{i=1} (\theta^T \cdot x^i - y^i)^2\]평균 제곱 오차의 식을 보면 실제 오차를 제곱하여 더해준 뒤 평균을 구한 값임을 알 수 있습니다. 비록 오차에 제곱을 해주었지만, 우리의 목표는 오차를 정확하게 구하는 것이 아니라 오차를 최소화하는 것입니다. 그렇기 때문에 미분 계산이 더 용이한 평균 제곱 오차를 가장 많이 사용합니다.
이제 본격적으로 경사 하강법을 알아보기 위한 모든 준비가 끝났습니다. 가장 기본적인 경사 하강법에 해당하는 배치 경사 하강법(Batch Gradient Descent) 부터 알아보도록 합시다. 경사 하강법에서 가장 중요한 것은 경사, 즉 그래디언트를 계산하는 것입니다. 우리가 사용할 비용 함수인 평균 제곱 오차에 대한 파라미터 $\theta$ 의 그래디언트는 편도함수(Partial derivative) 를 이용하여 구할 수 있습니다. 편도함수의 수식은 아래와 같습니다.
\[\frac{\partial}{\partial \theta_j}MSE(\theta) = \frac{2}{m}\sum_{i=1}^{m}(\theta^T \cdot x^i - y^i)x^i_j\]위 식은 각각의 파라미터 $\theta_j$ 에 대한 편도함수를 나타낸 것입니다. 그래디언트 벡터를 사용하면 이 식을 모든 파라미터에 대하여 행렬식으로 쓸 수 있습니다. 그래디언트 벡터를 사용하여 나타내 보겠습니다.
\[\nabla_\theta MSE(\theta) = \left[\begin{array}{c} \frac{\partial}{\partial \theta_0}MSE(\theta) \\ \frac{\partial}{\partial \theta_1}MSE(\theta) \\ \vdots \\ \frac{\partial}{\partial \theta_n}MSE(\theta) \end{array}\right] = \frac{2}{m}\mathbf{X}^T \cdot (\mathbf{X} \cdot \theta - \mathbf{y})\]이제 그래디언트를 구할 수 있게 되었습니다. 이제는 이 그래디언트를 우리의 목표에 맞게 사용하기 위해 목표를 다시 상기시켜 봅시다. 우리의 목표는 비용 함수가 최소가 되는 점, 즉 아래 그림에서 $\theta^\star$ 에 해당하는 점을 찾는 것이었습니다. 아래 그림을 보면 $\theta_0$ 에서 시작하여 $\theta^\star$ 까지 $\theta_1, \theta_2, \theta_3$ 으로 나아갈수록 그래디언트(기울기)가 점점 감소하는 것을 볼 수 있습니다. 그렇기 때문에 우리는 그래디언트(경사)가 $0$ 이 되는 순간까지 감소하는 방향으로 나아가야 합니다.
이미지 출처 : researchgate.net
이를 수식으로 나타내면 아래와 같습니다.
\[\theta^{d+1} = \theta^d - \eta \cdot \nabla_\theta MSE(\theta)\]위 식에서 새로운 항 $\eta$ 가 등장했습니다. 학습률(Learning rate) 을 나타내는 $\eta$ 는 경사 하강법에서 가장 중요한 하이퍼파라미터(hyperparameter, 사용자 지정 매개변수) 중 하나입니다. 학습률은 경사 하강법에서 보폭의 크기를 지정하는 것으로 사용자가 지정한 값에 따라 달라지게 됩니다. 아래의 이미지를 참고하여 설명을 이어나가겠습니다.
이미지 출처 : deeplearningwizard.com
위 그림에서 왼쪽은 학습률을 너무 작게 설정한 경우입니다. 학습률이 너무 작으면 특정 반복횟수 내에서 최소점을 찾지 못하는 경우가 있습니다. 물론 반복을 계속하게 되면 최소점에 다다를 수 있겠지만 너무 많은 시간과 컴퓨팅 자원을 소비하게 됩니다. 반대로 오른쪽은 학습률을 너무 크게 설정한 경우입니다. 학습률이 크면 빠르게 최소점으로 다가갈 수 있지만 진행 도중에 최소점을 지나쳐버리는 사고가 발생할 수 있습니다. 이런 문제 때문에 여러 학습률을 설정해보면서 가장 적절한 학습률을 찾아야 합니다. 경우에 따라서는 아래 그림과 같이 처음에는 학습률을 크게 설정한 뒤 점점 감소시켜 나가는 학습률 감소(Learning rate decay) 방법을 사용하기도 합니다. (아래 그림에서 학습률 감소 방법을 사용했을 때에 고정된 학습률을 사용했을 때보다 더 적은 반복수로 최솟값에 다다르는 것을 볼 수 있습니다)
이미지 출처 : deeplearningwizard.com
배치 경사 하강법의 가장 큰 문제는 매번 모든 데이터셋에 대해 그래디언트를 계산한다는 점입니다. 인스턴스의 개수가 많은 데이터셋에 배치 경사 하강법을 적용할 경우 시간이 오래 걸리고 컴퓨팅 자원을 많이 소모하게 됩니다. 확률적 경사 하강법(Stochastic Gradient Descent, SGD) 은 이러한 문제를 개선하기 위한 알고리즘입니다. 확률적 경사 하강법에서는 매 스텝마다 한 개의 샘플을 무작위로 선택한 뒤 하나의 샘플에 대해 그래디언트를 계산합니다. 반복마다 사용되는 인스턴스의 숫자가 하나뿐이기 때문에 훨씬 빠른 속도로 계산을 해낼 수 있습니다. 하지만 인스턴스를 랜덤하게 하나만 선택하기 때문에 배치 경사 하강법보다 불안정하다는 단점이 있습니다.
랜덤하게 선택하지만 매번 다른 인스턴스를 선택하므로 데이터셋 내에 있는 인스턴스 개수 $m$ 만큼 반복할 경우에는 데이터셋을 모두 살피게 됩니다. 이 때 $m$ 번 만큼의 반복을 에포크(Epoch) 라고 합니다. 예를 들어, $1000$ 개의 인스턴스로 구성된 데이터셋에 확률적 경사 하강법을 사용하여 그래디언트를 개선하는 과정을 $10000$ 번 시행한다고 합시다. 이 경우에는 총 $10000 / 1000 = 10$ 에포크 만큼 반복한 것입니다.
미니배치 경사 하강법(Mini-batch Gradient Descent) 은 두 방법의 절충안에 해당하는 경사 하강법 방식입니다. 전체 데이터셋을 사용하거나 하나의 인스턴스만을 선택하지 않고 작은 샘플 세트를 구성하여 경사하강법 알고리즘을 진행해 나가는 방식입니다.
아래는 최소제곱법과 각각의 경사 하강법에 대해 특징을 표로 나타낸 것입니다.
| 알고리즘 | 샘플 수가 클 때 | 특성 수가 클 때 | 외부 메모리 학습 지원 | 스케일 조정 필요 | 하이퍼 파라미터 수 |
|---|---|---|---|---|---|
| 최소제곱법 | 빠름 | 느림 | X | X | 0 |
| 배치 경사 하강법 | 느림 | 빠름 | X | O | 2 |
| 확률적 경사 하강법 | 빠름 | 빠름 | O | O | >=2 |
| 미니배치 경사 하강법 | 빠름 | 빠름 | O | O | >=2 |
Polynomial, 다항 회귀
모든 데이터셋이 직선의 형태를 보이는 것은 아닙니다. 아래 그림을 보며 설명을 이어가도록 하겠습니다.
이미지 출처 : animoidin.wordpress.com
위 그림에서 초록색 직선은 $-2$ 보다 오른쪽에 위치한 데이터는 잘 근사하는 듯하지만, 왼쪽에 위치한 데이터셋은 잘 근사하고 있지 못합니다. 그에 비해 빨간색 포물선은 모든 데이터셋을 그럴듯하게 근사하고 있음을 알 수 있습니다. 다항 회귀(Polynomial Regression) 는 이렇게 직선보다 복잡한 형태를 보이는 데이터를 근사하는 알고리즘 입니다.
다항 회귀는 특성 끼리의 곱이나 한 특성의 거듭제곱을 새로운 특성으로 추가하여 선형 모델을 훈련시킵니다. 예를 들어, 특성이 두 개 $x_1, x_2$ 인 데이터에 새로운 항없이 근사하면 다음 수식과 같은 함수가 됩니다.
\[\hat{f_1} = \theta_0 + \theta_1x_1 + \theta_2x_2\]하지만 서로 특성끼리 곱하거나 자기 자신을 제곱함으로써 아래 수식과 같이 데이터의 차원을 늘려줄 수 있습니다.
\[\hat{f_2} = \theta_0 + \theta_1x_1 + \theta_2x_2 + \theta_3x_1^2 + \theta_4x_1x_2 + \theta_5x_2^2\]위와 같이 차원이 높은 근사 함수는 낮은 차원의 근사함수보다 훈련 데이터에 더 잘 맞게됩니다. 특히 데이터의 갯수보다 파라미터의 개수가 같거나 많으면 훈련 데이터에 대해서 $100\%$ 의 정확도를 보입니다. 하지만 이럴 경우 훈련 데이터가 아닌 새로운 데이터에는 맞지 않는 현상이 일어납니다. 이런 현상을 과적합(Overfitting)이라고 합니다. 그렇기 때문에 우리는 “훈련 데이터에 어느정도 잘 맞되, 새로운 데이터에도 잘 맞도록” 차원을 조정해야 합니다. 이를 편향-분산 트레이드오프(Bias - Variance Trade-off) 라 하며 이곳 에서 더욱 자세한 내용을 볼 수 있습니다. 머신러닝에서 과적합은 피해야 할 커다란 문제입니다. 그렇기 때문에 교차 검증(Cross validation)1 을 통한 학습 곡선(Learning curve)2 을 사용하여 과적합을 방지합니다.
Comments