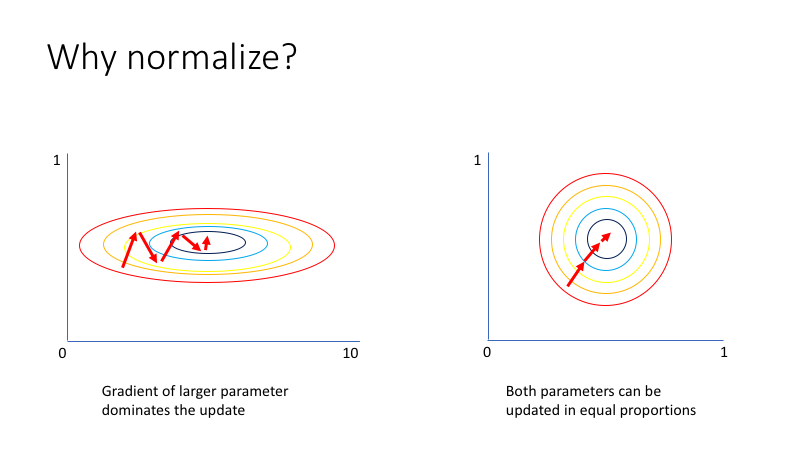
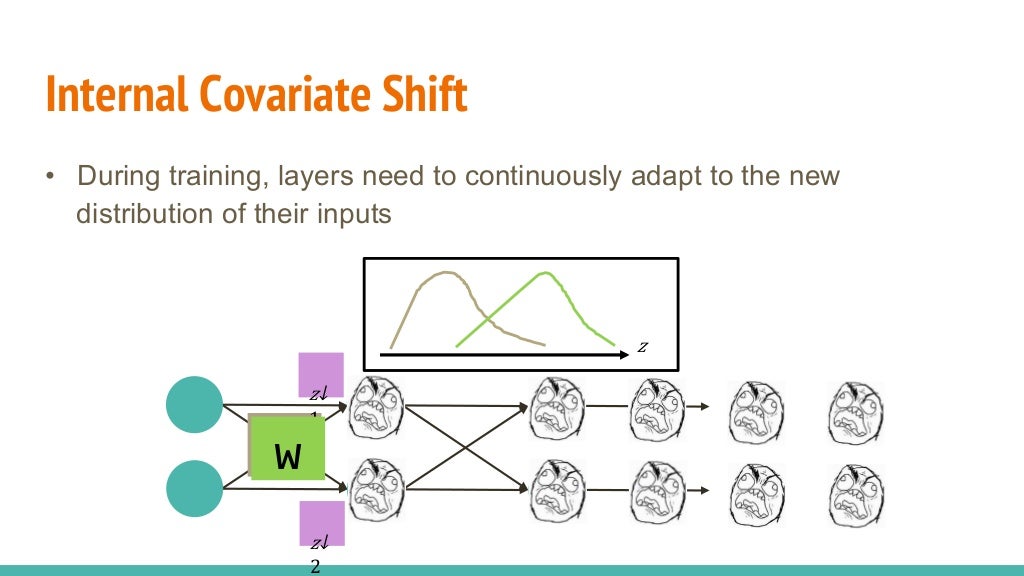
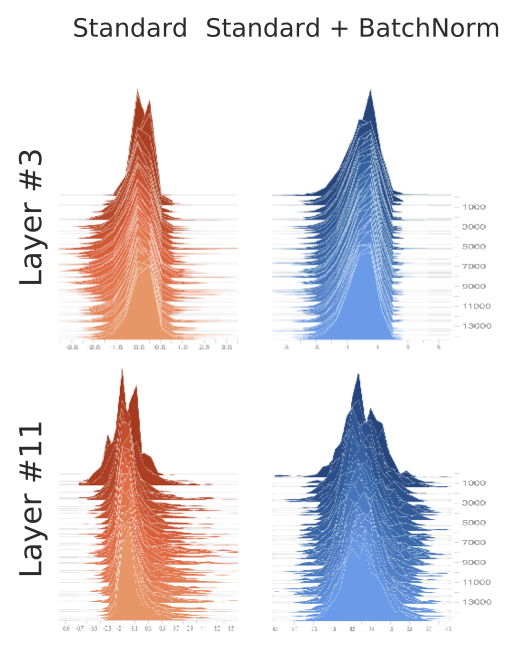
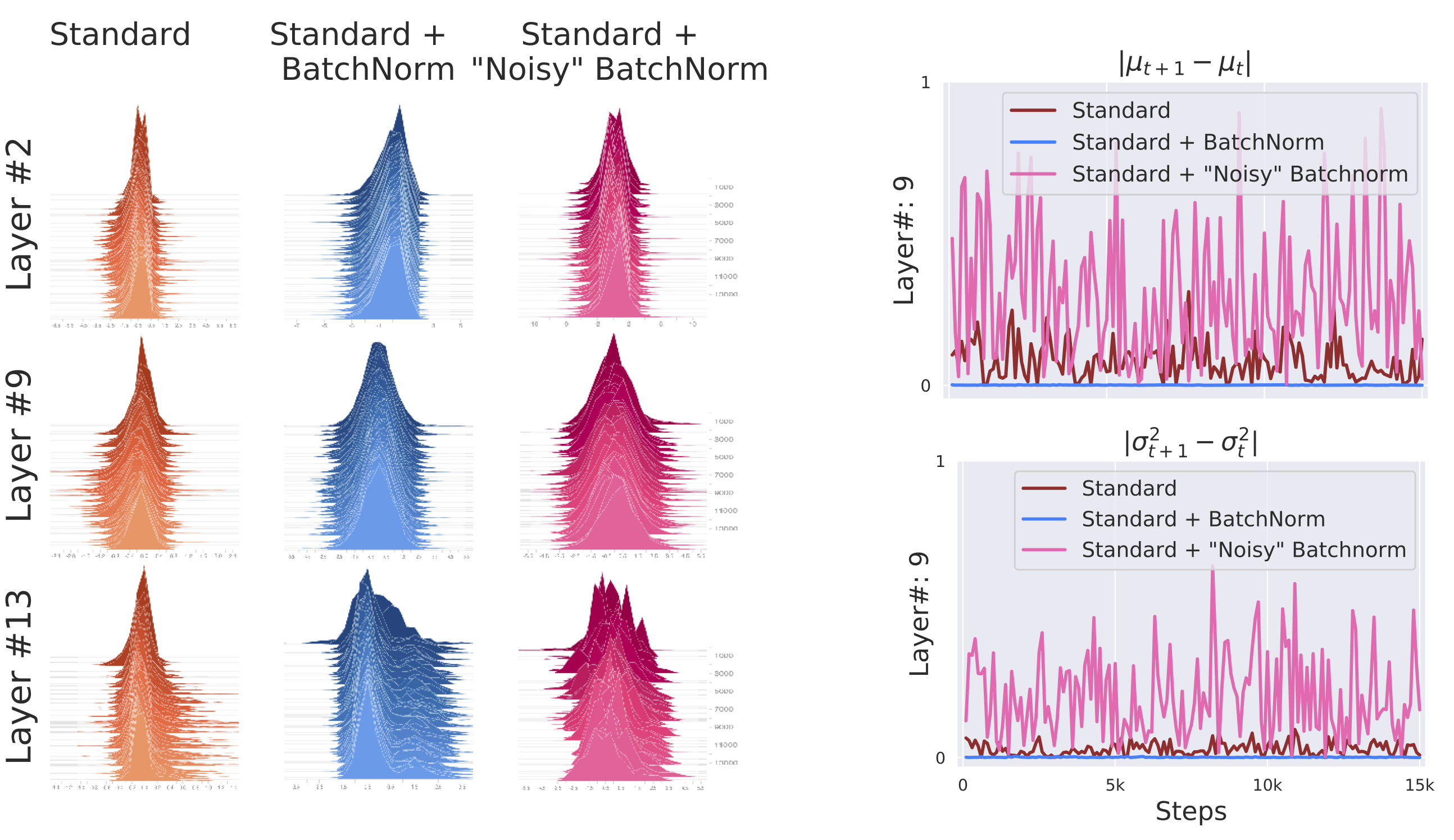
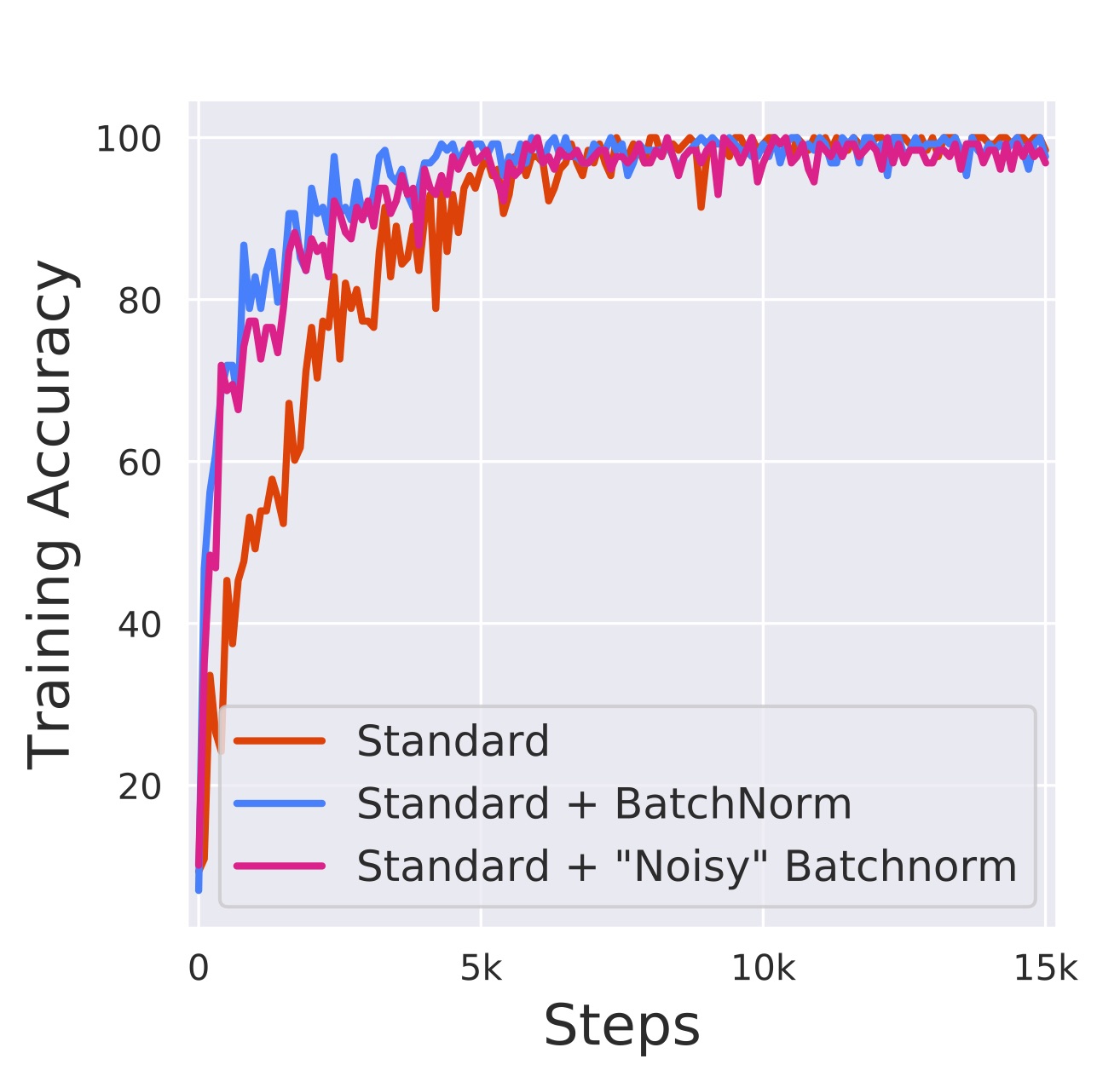
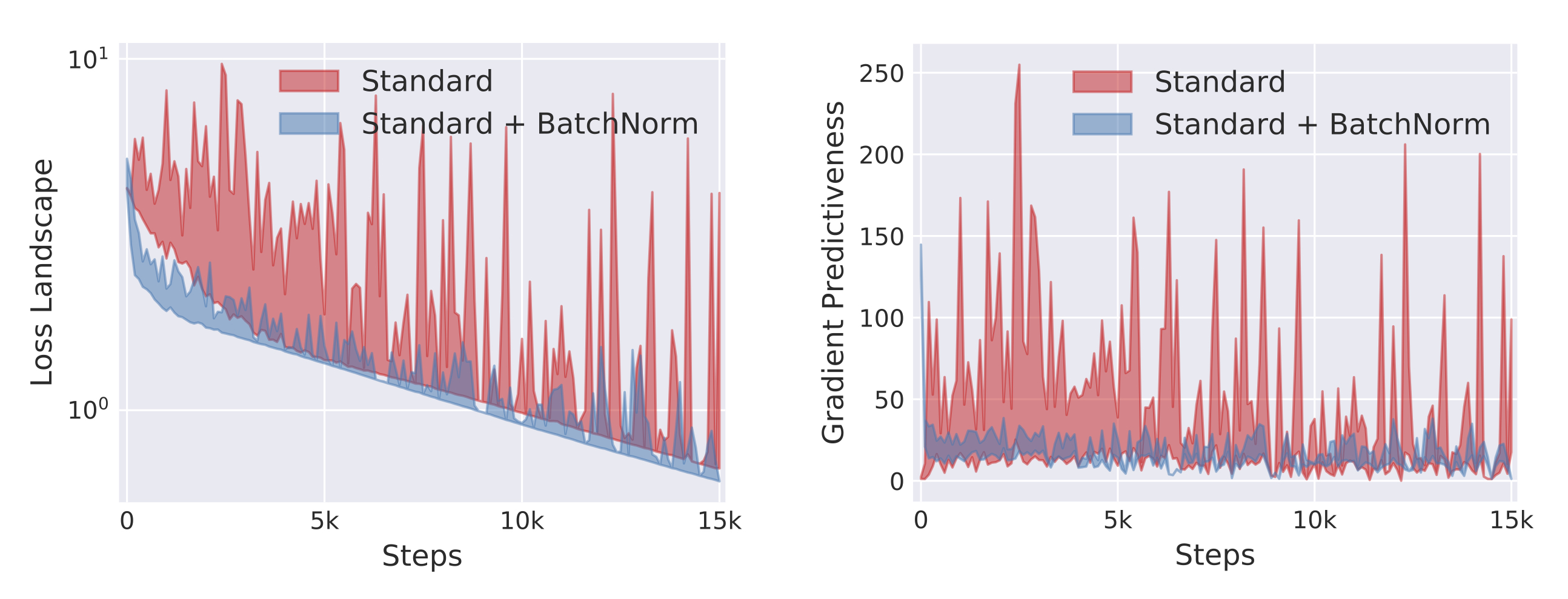
Numpy (1) - ndarray 생성, 데이터 타입 및 크기 다루기
23 Feb 2021 | Numpy
이번 포스팅의 내용은 파이썬 라이브러리를 활용한 데이터 분석(2판) 의 내용을 참조하여 작성하였습니다.
Numpy
Numpy(넘파이)는 Numerical Python의 줄임말입니다. 말 그대로 수학 계산을 위한 패키지이지요. 넘파이의 코드는 C, C++, Fortran 등으로 작성되었으며 파이썬으로 래핑되어 상당히 빠른 연산 속도를 보장합니다. 넘파이 배열(Array) 연산시에는 반복문(for loop)을 사용하지 않고 벡터화된 연산을 수행합니다.
ndarray 생성하기
ndarray는 넘파이가 제공하는 $N$ 차원의 배열 객체입니다. 넘파이 패키지를 import 한 뒤에 ndarray 를 생성해보겠습니다. 생성된 객체의 타입을 확인할 수 있습니다.
>>> import numpy as np
>>> arr1 = np.array([1, 2, 3])
>>> print(type(arr1))
<class 'numpy.ndarray'>
리스트를 변환하여 새로운 배열을 생성할 수도 있습니다.
>>> lst1 = [1, 4, 9, 16]
>>> arr2 = np.array(lst1)
>>> arr2
array([ 1, 4, 9, 16])
ndarray 데이터 타입 다루기
생성된 배열의 요소 타입을 확인하는 메서드로 .dtype 이 있습니다. 배열 생성 시 타입을 지정해주지 않는다면 int64 혹은 float64 로 생성됩니다. 만약 크기가 크지 않은 정수형 데이터를 다루거나, 부동 소수점에 만감하지 않은 실수형 데이터를 다루기 위해 배열을 생성할 때 데이터 타입을 int32, float32 로 지정해주면 메모리를 절약할 수 있습니다.
# 따로 지정해주지 않은 경우 `int64'로 생성
>>> print(arr1.dtype)
int64
# 생성할 때 요소의 타입을 지정해주면 그대로 생성
>>> arr3 = np.array([1, 2, 3], dtype='int32')
>>> print(arr3.dtype)
int32
# float(실수형)도 마찬가지
>>> arr_float1 = np.array([1, 2.5, 4, 5.5])
>>> print(arr_float1.dtype)
float64
# float32로 지정해주면 그대로 생성한다
>>> arr_float2 = np.array([1, 2.5, 4, 5.5], dtype='float32')
>>> print(arr_float2.dtype)
float32
.astype 메서드를 활용하면 배열의 데이터 타입을 다른 형태로 바꾸어 새로운 형태로 할당할 수 있습니다.
>>> arr_float3 = arr1.astype('float64')
>>> print(arr_float3.dtype)
float64
실수형(float) 데이터 타입을 정수형으로 변경한 경우에는 소수점 아래 자리가 버려집니다. .astype 메서드를 활용하면 숫자를 담고 있는 문자열도 숫자로 변환할 수 있습니다.
# 실수형 데이터타입을 정수형으로 변경한 경우
>>> arr_int1 = arr_float1.astype('int64')
>>> arr_int1
array([1, 2, 4, 5])
# 2.5 -> 2로, 5.5 -> 5로 소수점이 버려진 것을 알 수 있습니다.
# 음수의 경우 -1.5 -> -1, -3.7 -> -3 과 같이 변합니다.
# 숫자를 품고 있는 문자열 숫자로 변환하기
>>> arr_str1 = np.array(['1.3', '4.24', '-5'])
>>> arr_num1 = arr_str1.astype('float64')
>>> arr_num1
array([ 1.3 , 4.24, -5. ])
ndarray의 크기 다루기
.ndim 메서드를 사용하면 해당 배열의 차원 수를 알 수 있고 .shape 메서드로는 해당 배열의 크기(형태)를 알 수 있습니다.
>>> arr_2dim = np.array([[1, 2, 3], [4, 5, 6]])
>>> arr_2dim
array([[1, 2, 3],
[4, 5, 6]])
>>> print(f"""배열의 차원 수 : {arr_2dim.ndim}
배열의 크기 : {arr_2dim.shape}""")
배열의 차원 수 : 2
배열의 크기 : (2, 3)
2차원 배열을 생성하였으므로 .ndim 을 사용하여 확인한 값은 $2$ 가 나왔고 2행 3열 이므로 배열의 크기는 $(2, 3)$ 이 나왔습니다. 차원은 알기 쉽지만 크기는 선뜻 알기 쉽지 않습니다. 3차원 배열을 생성하여 크기가 어떻게 결정되는지 한 번 더 알아보겠습니다.
>>> arr_3dim = np.array([[[1, 2, -3], [3, 4, -5]], [[5, 6, -7], [7, 8, -9]]])
>>> arr_3dim
array([[[ 1, 2, -3],
[ 3, 4, -5]],
[[ 5, 6, -7],
[ 7, 8, -9]]])
>>> print(f"""배열의 차원 수 : {arr_3dim.ndim}
배열의 크기 : {arr_3dim.shape}""")
배열의 차원 수 : 3
배열의 크기 : (2, 2, 3)
.reshape 메서드를 사용하면 행렬의 차원이나 크기를 변경할 수 있습니다. 요소의 개수가 24개인 행렬을 만들고 이를 다양한 차원과 크기로 변형해보겠습니다.
# .arange는 range와 비슷한 역할을 하는 메서드입니다
>>> arr_12 = np.arange(12)
>>> arr_12
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 배열의 shape을 (3,4)로 변경하기 (1차원 -> 2차원)
>>> arr_3x4 = arr_24.reshape(3,4)
>>> arr_3x4
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
# 배열의 shape을 (2,3,4)로 변경하기 (1차원 -> 3차원)
>>> arr_2x2x3 = arr_12.reshape(2,2,3)
>>> arr_2x2x3
array([[[ 0, 1, 2],
[ 3, 4, 5]],
[[ 6, 7, 8],
[ 9, 10, 11]]])
위와 같이 .reshape 을 사용하면 행렬의 크기와 차원을 변경할 수 있습니다. .reshape 메서드 사용시 주의할 점은 바꿀 대상의 요소의 개수와 행렬의 크기가 맞아야 한다는 것입니다. 아래와 같이 요소의 개수와 바꾸고자 하는 행렬의 크기가 맞지 않으면 에러가 발생합니다.
>>> arr_2x2x2 = arr_12.reshape(2,2,2)
>>> arr_2x2x2
ValueError: cannot reshape array of size 12 into shape (2,2,2)
원래 배열의 요소는 12개인데 바꾸고자 하는 크기인 $(2,2,2)$ 는 이와 맞지 않습니다. 숫자가 많아지면 .reshape 사용시 암산으로만 숫자를 배정하기가 힘듭니다. 넘파이에서는 이를 위해서 한 가지 편의 기능을 제공합니다. .reshape 의 인자로 $-1$ 을 넣어주면 숫자 하나를 대체할 수 있습니다. 아래 예시를 보겠습니다.
>>> arr_2x2x_1 = arr_12.reshape(2,2,-1)
>>> arr_2x2x_1
array([[[ 0, 1, 2],
[ 3, 4, 5]],
[[ 6, 7, 8],
[ 9, 10, 11]]])
>>> arr_2x_1x3 = arr_12.reshape(2,-1,3)
>>> arr_2x_1x3
array([[[ 0, 1, 2],
[ 3, 4, 5]],
[[ 6, 7, 8],
[ 9, 10, 11]]])
각각 $3$과 $2$의 자리를 $-1$을 사용하여 잘 대체한 것을 볼 수 있습니다. 이 기능을 사용하면 편하게 행렬의 크기를 변경할 수 있습니다. 그런데 $-1$ 을 2개 이상 사용하면 어떻게 될까요?
>>> arr_2x_1x_1 = arr_12.reshape(2,-1,-1)
>>> arr_2x_1x_1
ValueError: can only specify one unknown dimension
unknown dimension, 즉 $-1$ 로 대체할 수 있는 차원은 2개 이상 지정할 수 없음을 알리는 에러가 발생했습니다.
Conclusion
이번 게시물에서는 넘파이 패키지를 사용하여 배열(ndarray)을 생성하고 생성한 배열의 데이터 타입과 크기를 다뤄보았습니다. 다음 게시물에서는 배열의 슬라이싱에 대해서 알아보겠습니다.
이번 포스팅의 내용은 파이썬 라이브러리를 활용한 데이터 분석(2판) 의 내용을 참조하여 작성하였습니다.
Numpy
Numpy(넘파이)는 Numerical Python의 줄임말입니다. 말 그대로 수학 계산을 위한 패키지이지요. 넘파이의 코드는 C, C++, Fortran 등으로 작성되었으며 파이썬으로 래핑되어 상당히 빠른 연산 속도를 보장합니다. 넘파이 배열(Array) 연산시에는 반복문(for loop)을 사용하지 않고 벡터화된 연산을 수행합니다.
ndarray 생성하기
ndarray는 넘파이가 제공하는 $N$ 차원의 배열 객체입니다. 넘파이 패키지를 import 한 뒤에 ndarray 를 생성해보겠습니다. 생성된 객체의 타입을 확인할 수 있습니다.
>>> import numpy as np
>>> arr1 = np.array([1, 2, 3])
>>> print(type(arr1))
<class 'numpy.ndarray'>
리스트를 변환하여 새로운 배열을 생성할 수도 있습니다.
>>> lst1 = [1, 4, 9, 16]
>>> arr2 = np.array(lst1)
>>> arr2
array([ 1, 4, 9, 16])
ndarray 데이터 타입 다루기
생성된 배열의 요소 타입을 확인하는 메서드로 .dtype 이 있습니다. 배열 생성 시 타입을 지정해주지 않는다면 int64 혹은 float64 로 생성됩니다. 만약 크기가 크지 않은 정수형 데이터를 다루거나, 부동 소수점에 만감하지 않은 실수형 데이터를 다루기 위해 배열을 생성할 때 데이터 타입을 int32, float32 로 지정해주면 메모리를 절약할 수 있습니다.
# 따로 지정해주지 않은 경우 `int64'로 생성
>>> print(arr1.dtype)
int64
# 생성할 때 요소의 타입을 지정해주면 그대로 생성
>>> arr3 = np.array([1, 2, 3], dtype='int32')
>>> print(arr3.dtype)
int32
# float(실수형)도 마찬가지
>>> arr_float1 = np.array([1, 2.5, 4, 5.5])
>>> print(arr_float1.dtype)
float64
# float32로 지정해주면 그대로 생성한다
>>> arr_float2 = np.array([1, 2.5, 4, 5.5], dtype='float32')
>>> print(arr_float2.dtype)
float32
.astype 메서드를 활용하면 배열의 데이터 타입을 다른 형태로 바꾸어 새로운 형태로 할당할 수 있습니다.
>>> arr_float3 = arr1.astype('float64')
>>> print(arr_float3.dtype)
float64
실수형(float) 데이터 타입을 정수형으로 변경한 경우에는 소수점 아래 자리가 버려집니다. .astype 메서드를 활용하면 숫자를 담고 있는 문자열도 숫자로 변환할 수 있습니다.
# 실수형 데이터타입을 정수형으로 변경한 경우
>>> arr_int1 = arr_float1.astype('int64')
>>> arr_int1
array([1, 2, 4, 5])
# 2.5 -> 2로, 5.5 -> 5로 소수점이 버려진 것을 알 수 있습니다.
# 음수의 경우 -1.5 -> -1, -3.7 -> -3 과 같이 변합니다.
# 숫자를 품고 있는 문자열 숫자로 변환하기
>>> arr_str1 = np.array(['1.3', '4.24', '-5'])
>>> arr_num1 = arr_str1.astype('float64')
>>> arr_num1
array([ 1.3 , 4.24, -5. ])
ndarray의 크기 다루기
.ndim 메서드를 사용하면 해당 배열의 차원 수를 알 수 있고 .shape 메서드로는 해당 배열의 크기(형태)를 알 수 있습니다.
>>> arr_2dim = np.array([[1, 2, 3], [4, 5, 6]])
>>> arr_2dim
array([[1, 2, 3],
[4, 5, 6]])
>>> print(f"""배열의 차원 수 : {arr_2dim.ndim}
배열의 크기 : {arr_2dim.shape}""")
배열의 차원 수 : 2
배열의 크기 : (2, 3)
2차원 배열을 생성하였으므로 .ndim 을 사용하여 확인한 값은 $2$ 가 나왔고 2행 3열 이므로 배열의 크기는 $(2, 3)$ 이 나왔습니다. 차원은 알기 쉽지만 크기는 선뜻 알기 쉽지 않습니다. 3차원 배열을 생성하여 크기가 어떻게 결정되는지 한 번 더 알아보겠습니다.
>>> arr_3dim = np.array([[[1, 2, -3], [3, 4, -5]], [[5, 6, -7], [7, 8, -9]]])
>>> arr_3dim
array([[[ 1, 2, -3],
[ 3, 4, -5]],
[[ 5, 6, -7],
[ 7, 8, -9]]])
>>> print(f"""배열의 차원 수 : {arr_3dim.ndim}
배열의 크기 : {arr_3dim.shape}""")
배열의 차원 수 : 3
배열의 크기 : (2, 2, 3)
.reshape 메서드를 사용하면 행렬의 차원이나 크기를 변경할 수 있습니다. 요소의 개수가 24개인 행렬을 만들고 이를 다양한 차원과 크기로 변형해보겠습니다.
# .arange는 range와 비슷한 역할을 하는 메서드입니다
>>> arr_12 = np.arange(12)
>>> arr_12
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 배열의 shape을 (3,4)로 변경하기 (1차원 -> 2차원)
>>> arr_3x4 = arr_24.reshape(3,4)
>>> arr_3x4
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
# 배열의 shape을 (2,3,4)로 변경하기 (1차원 -> 3차원)
>>> arr_2x2x3 = arr_12.reshape(2,2,3)
>>> arr_2x2x3
array([[[ 0, 1, 2],
[ 3, 4, 5]],
[[ 6, 7, 8],
[ 9, 10, 11]]])
위와 같이 .reshape 을 사용하면 행렬의 크기와 차원을 변경할 수 있습니다. .reshape 메서드 사용시 주의할 점은 바꿀 대상의 요소의 개수와 행렬의 크기가 맞아야 한다는 것입니다. 아래와 같이 요소의 개수와 바꾸고자 하는 행렬의 크기가 맞지 않으면 에러가 발생합니다.
>>> arr_2x2x2 = arr_12.reshape(2,2,2)
>>> arr_2x2x2
ValueError: cannot reshape array of size 12 into shape (2,2,2)
원래 배열의 요소는 12개인데 바꾸고자 하는 크기인 $(2,2,2)$ 는 이와 맞지 않습니다. 숫자가 많아지면 .reshape 사용시 암산으로만 숫자를 배정하기가 힘듭니다. 넘파이에서는 이를 위해서 한 가지 편의 기능을 제공합니다. .reshape 의 인자로 $-1$ 을 넣어주면 숫자 하나를 대체할 수 있습니다. 아래 예시를 보겠습니다.
>>> arr_2x2x_1 = arr_12.reshape(2,2,-1)
>>> arr_2x2x_1
array([[[ 0, 1, 2],
[ 3, 4, 5]],
[[ 6, 7, 8],
[ 9, 10, 11]]])
>>> arr_2x_1x3 = arr_12.reshape(2,-1,3)
>>> arr_2x_1x3
array([[[ 0, 1, 2],
[ 3, 4, 5]],
[[ 6, 7, 8],
[ 9, 10, 11]]])
각각 $3$과 $2$의 자리를 $-1$을 사용하여 잘 대체한 것을 볼 수 있습니다. 이 기능을 사용하면 편하게 행렬의 크기를 변경할 수 있습니다. 그런데 $-1$ 을 2개 이상 사용하면 어떻게 될까요?
>>> arr_2x_1x_1 = arr_12.reshape(2,-1,-1)
>>> arr_2x_1x_1
ValueError: can only specify one unknown dimension
unknown dimension, 즉 $-1$ 로 대체할 수 있는 차원은 2개 이상 지정할 수 없음을 알리는 에러가 발생했습니다.
Conclusion
이번 게시물에서는 넘파이 패키지를 사용하여 배열(ndarray)을 생성하고 생성한 배열의 데이터 타입과 크기를 다뤄보았습니다. 다음 게시물에서는 배열의 슬라이싱에 대해서 알아보겠습니다.