그래프 표현(Graph Representation)
10 May 2021 | Graph ML
해당 포스트는 스탠포드 대학교의 cs224w 를 바탕으로 작성하였습니다.
Graph Representation
이전 게시물에서 알아본 바와 같이 그래프는 노드와 엣지로 구성되어 있습니다. 노드(Node)는 특정 객체(Objects)를 나타내며 앞 스펠링을 따서 $N$ 으로 표현합니다. 엣지(Edge)는 링크(Link)라고도 불리며 노드 사이의 상호작용(Interaction)을 나타냅니다. 엣지 역시 맨 앞 스펠링을 따서 $E$로 표현합니다. 객체와 객체 간 상호작용으로 이루어진 시스템을 그래프라고 하며 $G(N,E)$ 로 나타냅니다. 그래프는 공용 언어이기 때문에 다양한 도메인에서의 시스템을 그래프로 설명할 수 있습니다.
우리가 접하게 되는 시스템을 그래프로 나타내고자 한다면 어떤 것을 노드로 나타내고, 어떤 것을 엣지로 나타낼 지를 결정해야 합니다. 물론 객체와 그 상호작용이 명확하고 유일한 시스템도 있지만, 그렇지 않은 시스템도 많습니다. 후자의 경우 어떤 노드로 설정하고 그 사이의 어떤 상호작용을 어떻게 나타낼 지, 즉 적절한 그래프 표현을 찾는 지가 굉장히 중요한 문제가 됩니다.
Directed vs Undirected
그래프를 구분하는 여러가지 범주 중 하나는 해당 그래프의 엣지가 방향성을 가지는가 입니다. 먼저 엣지가 방향성을 가지지 않는 그래프에 대해서 알아보겠습니다. 이런 그래프를 무향 그래프(Undirected graph)라고 합니다. 예를 들어, 페이스북에서의 친구 관계가 여기에 해당합니다. 반대로 엣지가 방향성을 가지는 그래프도 있는데 이런 그래프를 유향 그래프(Directed graph)라고 합니다. 트위터에서의 팔로우 관계나 금융 거래 등을 유향 그래프로 나타낼 수 있습니다. 아래는 유향 그래프와 무향 그래프의 구조를 나타낸 이미지입니다.
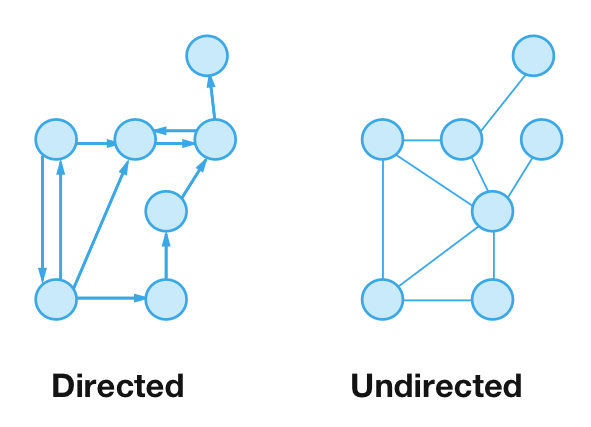
이미지 출처 : raywenderlich.com
Node degree
Node degree란 특정 노드 $i$ 와 인접한 노드의 수를 나타내는 척도로 $k_i$ 로 나타냅니다. 예를 들어, 아래와 같은 무향 그래프가 있을 때 붉은 색으로 표시된 노드의 Node degree는 $k_{\text{red}} = 4$ 입니다.
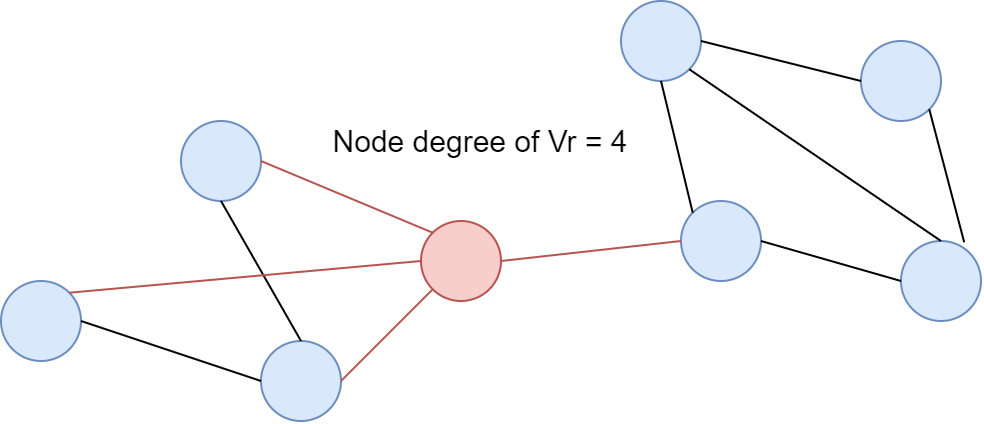
이미지 출처 : laptrinhx.com
이로부터 그래프 전체에서의 평균 Node degree, $\bar{k}$ 도 구할 수 있습니다. 엣지의 개수가 $E$ 이고 노드의 개수가 $N$ 일 때, 평균 Node degree는 아래 식을 사용하여 구할 수 있습니다.
[\bar{k} = \frac{1}{N} \sum_{i=1}^N k_i = \frac{2E}{N}]
유향 그래프(Directed graph)에서는 엣지 방향에 따라 in-degree, $k^{\text{in}}$ 와 out-degree, $k^{\text{out}}$ 를 따로 정의할 수 있습니다. 해당 노드로 들어오는 엣지의 개수를 in-degree 라고 하며, 해당 노드로부터 나가는 엣지의 개수를 out-degree 라고 합니다. 아래와 같은 유향 그래프가 있다고 해보겠습니다.

위 그림에서 붉은 색으로 표시된 $C$ 노드의 in-degree, $k_{\text{red}}^{\text{in}}=0$ 이고 out-degree $k_{\text{red}}^{\text{out}}=4$ 입니다. $C, D$ 처럼 $k^{\text{in}}=0$ 인 노드를 Source 라고 하고 $A,B,E$ 처럼 $k^{\text{out}}=0$ 인 노드를 Sink 라고 합니다. 유향 그래프에서의 Node degree는 다음과 같은 식을 만족합니다.
[k_c = k^{\text{in}} + k^{\text{out}}
\bar{k}^{\text{in}} = \bar{k}^{\text{out}} = \frac{E}{N}]
Bipartite Graph
이번에는 특이한 형태의 그래프인 이분 그래프(Bipartite graph)에 대해서 알아보도록 하겠습니다. 이분 그래프의 노드는 겹치지 않는 2개의 집합 $U, V$ 로 나눌 수 있습니다. 엣지는 $U$ 와 $V$ 사이만을 연결합니다. 즉, $U$ 에 속하는 노드 사이, $V$ 에 속하는 노드 사이에는 엣지 연결이 없습니다. 그림으로 나타내면 다음과 같습니다.
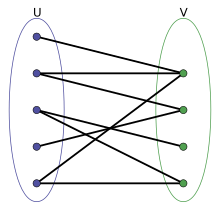
이미지 출처 : wikipedia.org
이분 그래프로 표현할 수 있는 관계는 논문 저자-논문, 출연배우-영화 등이 있습니다. 이분 그래프를 알아야 하는 이유는 이분 그래프로부터 $U,V$ 에 속하는 노드의 관계를 사영(Projection)할 수 있기 때문입니다. 아래와 같이 파란색으로 나타낸 사용자(Users) 노드 집합과 빨간색을 나타낸 상품(Items) 노드 사이의 관계를 나타낸 이분 그래프가 있다고 해보겠습니다.
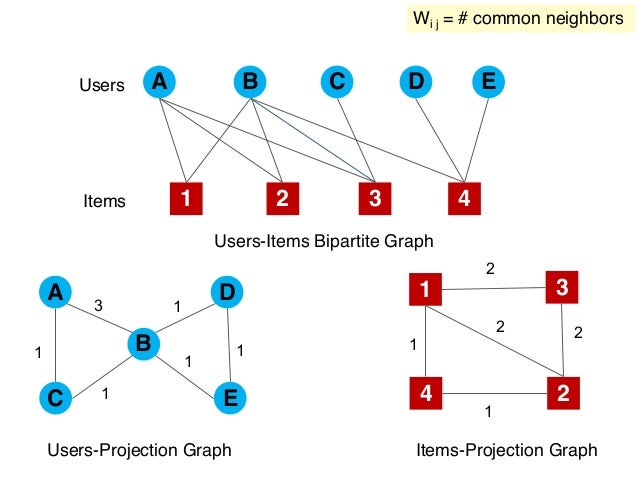
이미지 출처 : slideshare.net
사용자-상품 이분 그래프로부터 유저 간의 관계, 상품 간의 관계를 나타낸 그래프를 사영할 수 있습니다. 예를 들어, 유저 $A, B$ 는 3개의 상품을 공유하고 있으므로 3의 관계를 나타내는 노드로 연결합니다. 유저 $B, D$ 는 1개의 상품을 공유하고 있으므로 1의 관계를 나타내는 노드로 연결하며 유저 $A, D$ 는 아무런 상품도 공유하고 있지 않으므로 연결되지 않습니다. 상품 간의 관계를 나타낸 사영 그래프 역시 해당 상품이 몇 명의 유저를 공유하는 지를 바탕으로 서로의 관계를 나타냅니다.
Adjacency Matrix
이제는 위와 같이 나타나는 그래프를 컴퓨터가 이해할 수 있는 숫자로 표현해 줄 차례입니다. 그래프의 표현은 인접 행렬(Adjacency matrix)을 사용합니다. 가장 간단한 표현 방법은 연결 유무에 따른 이진 행렬(Binary matrix)입니다. 두 노드가 연결되어 있으면 1로, 그렇지 않으면 0으로 표현하는 방법이지요. 무향 그래프를 인접 행렬로 나타내면 아래와 같습니다.

이미지 출처 : thecrazyprogrammer.com
무향 그래프는 이어진 노드의 관계가 서로 동일하므로 인접 행렬 $A$ 의 대칭 성분이 동일합니다. 그렇기 때문에 무향 그래프를 나타낸 인접 행렬은 대칭 행렬(Symmetric matrix)이라는 특징이 있습니다. 그렇다면 유향 그래프는 인접 행렬로 어떻게 나타낼 수 있을까요? 유향 그래프를 나타낸 인접 행렬은 다음과 같습니다.

이미지 출처 : thecrazyprogrammer.com
유향 그래프를 나타낸 인접 행렬의 요소는 $i$ 번째 행의 노드가 $j$ 행의 노드를 가리킬 때에만 1의 값을 갖습니다. 예를 들어, 노드 2는 노드 1을 가리키기 때문에 $A_{21} = 1$ 로 나타냅니다. 하지만 노드 1은 노드 2를 가리키지 않기 때문에 $A_{12} = 0$ 으로 나타냅니다. 그렇기 때문에 유향 그래프를 나타낸 인접 행렬은 대부분 비대칭(Asymmetric)입니다.
현실 세상에 있는 네트워크를 나타낸 인접 행렬은 매우 희소합니다. 아래는 실제 네트워크에서의 노드 개수 $N$ 와 엣지 개수 $L$ , 평균 Node degree를 나타낸 표입니다.

인접 행렬에서 1의 비율은 $E/N^2$ 로 나타낼 수 있습니다. 위에 나온 대부분의 네트워크가 $10^{-4}$ 이하의 값을 가지므로 매우 희소한 인접 행렬로 나타난다는 것을 알 수 있습니다.
Attributes
각 노드와 엣지에는 여러 속성이 추가될 수 있습니다. 속성의 종류에는 다음과 같은 것들이 있습니다.
- 가중치(Weight) : 객체 간 의사소통을 나타낸 네트워크에서 네트워크의 빈도를 가중치로 표현할 수 있습니다.
- 순위(Ranking) : 객체 간 관계에 순위가 있을 경우 순위 속성을 사용하여 나타낼 수 있습니다.
- 유형(Type) : 객체 간 관계의 유형이 다를 경우 이를 속성으로 추가하여 표현할 수 있습니다.
- 부호(Sign) : 우호 관계, 적대적 관계와 같이 완전히 반대의 관계를 가질 경우 부호 속성을 추가하여 Positive/Negative 관계를 표현할 수 있습니다.
More Types of Graph
더욱 다양한 유형의 그래프에 대해서 알아보겠습니다. 첫 번째는 속성이 추가된 그래프입니다. 이 경우 인접 행렬은 $0,1$ 외에 다른 값을 가지게 됩니다. 가중치 속성이 추가된 행렬을 인접 행렬로 나타낸 그래프는 다음과 같습니다.

이미지 출처 : thecrazyprogrammer.com
Self-loops 가 추가된 형태의 그래프도 있습니다. Self-loops 가 없는 경우 인접 행렬의 대각(Diagonal) 성분은 항상 0이 되지만, 있을 경우에는 대각 성분 $A_{ii} \neq 0$ 이 됩니다.

이미지 출처 : quora.com
위 그래프에서 노드 1에 자기 자신을 가리키는 엣지가 하나있기 때문에 $A_{11} = 1$ 의 값을 갖습니다.
마지막으로 1개 이상의 노드로 연결된 다중 그래프(Multigraph)가 있습니다. 다중 그래프의 인접 행렬은 가중치 속성이 추가된 그래프와 같이 1이상의 값을 갖습니다.

이미지 출처 : math.stackexchange.com
Connectivity
그래프의 표현을 위해 마지막으로 알아볼 것은 연결성(Connectivity)입니다. 어떤 두 노드를 선택하더라도 둘을 연결하는 경로를 찾을 수 있을 경우 이 그래프를 연결된 그래프(Connected graph)라고 합니다. 위에서 예시로 살펴본 모든 그래프는 연결된 그래프입니다. 아래는 연결된 그래프와 연결되지 않은 그래프(Disconnected grpah)를 나타낸 이미지입니다.

이미지 출처 : algorithms.tutorialhorizon.com
유향 그래프에서 특정한 연결을 가진 노드 관계를 강한 연결(Strong connectivity)로 나타낼 수 있습니다. 아래와 같이 어떤 두 노드 $A, B$ 를 선택하더라도 두 노드 사이의 경로 $A \rightarrow B, B \rightarrow A$ 가 모두 정의될 경우 강하게 연결된 그래프(Strongly connected graph)라고 합니다.
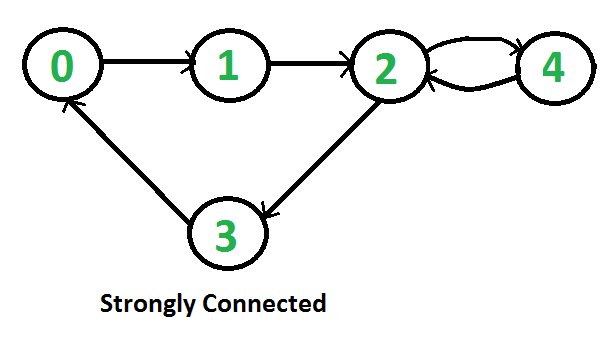
이미지 출처 : geeksforgeeks.org
예를 들어, 위 그래프에서 노드 1과 노드 3 사이의 경로는 $1 \rightarrow 3 \quad (=1\rightarrow2\rightarrow3)$ 과 $3 \rightarrow 1 \quad (=3\rightarrow0\rightarrow1)$ 이 모두 정의됩니다. 위 그래프의 어떤 두 노드를 선택하더라도 서로 간 경로가 정의되므로 강한 연결성(Strong connectivity)을 가진다고 할 수 있습니다.
범위를 좁혀 일반 그래프 내에서 강하게 연결된 부분(Strongly connected components, SCCs)을 정의할 수 있습니다. 일반 그래프에서 강한 연결을 가지는 노드 부분을 찾을 수 있는데 이를 SCC라고 합니다. 아래는 특정 그래프에서 SCC를 나타낸 이미지입니다.
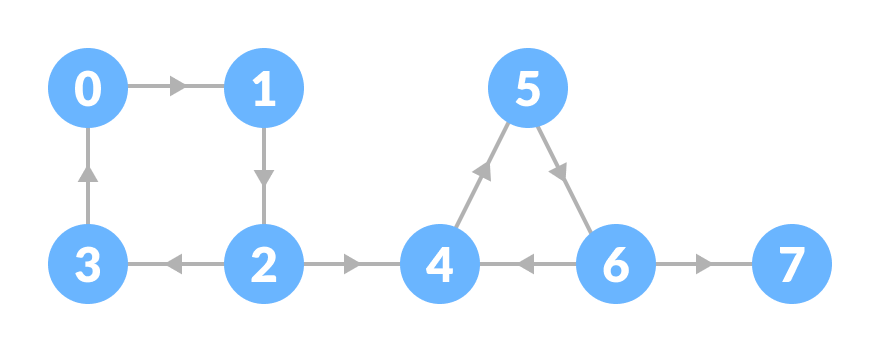
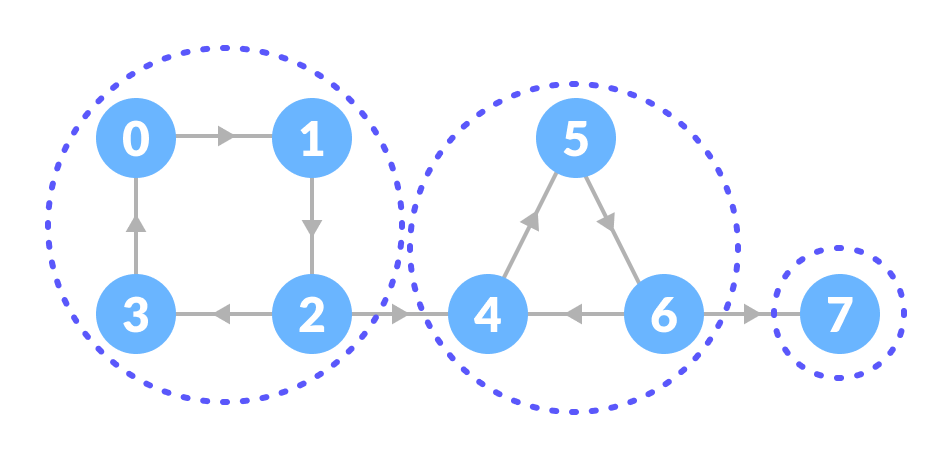
이미지 출처 : programiz.com
해당 포스트는 스탠포드 대학교의 cs224w 를 바탕으로 작성하였습니다.
Graph Representation
이전 게시물에서 알아본 바와 같이 그래프는 노드와 엣지로 구성되어 있습니다. 노드(Node)는 특정 객체(Objects)를 나타내며 앞 스펠링을 따서 $N$ 으로 표현합니다. 엣지(Edge)는 링크(Link)라고도 불리며 노드 사이의 상호작용(Interaction)을 나타냅니다. 엣지 역시 맨 앞 스펠링을 따서 $E$로 표현합니다. 객체와 객체 간 상호작용으로 이루어진 시스템을 그래프라고 하며 $G(N,E)$ 로 나타냅니다. 그래프는 공용 언어이기 때문에 다양한 도메인에서의 시스템을 그래프로 설명할 수 있습니다.
우리가 접하게 되는 시스템을 그래프로 나타내고자 한다면 어떤 것을 노드로 나타내고, 어떤 것을 엣지로 나타낼 지를 결정해야 합니다. 물론 객체와 그 상호작용이 명확하고 유일한 시스템도 있지만, 그렇지 않은 시스템도 많습니다. 후자의 경우 어떤 노드로 설정하고 그 사이의 어떤 상호작용을 어떻게 나타낼 지, 즉 적절한 그래프 표현을 찾는 지가 굉장히 중요한 문제가 됩니다.
Directed vs Undirected
그래프를 구분하는 여러가지 범주 중 하나는 해당 그래프의 엣지가 방향성을 가지는가 입니다. 먼저 엣지가 방향성을 가지지 않는 그래프에 대해서 알아보겠습니다. 이런 그래프를 무향 그래프(Undirected graph)라고 합니다. 예를 들어, 페이스북에서의 친구 관계가 여기에 해당합니다. 반대로 엣지가 방향성을 가지는 그래프도 있는데 이런 그래프를 유향 그래프(Directed graph)라고 합니다. 트위터에서의 팔로우 관계나 금융 거래 등을 유향 그래프로 나타낼 수 있습니다. 아래는 유향 그래프와 무향 그래프의 구조를 나타낸 이미지입니다.
이미지 출처 : raywenderlich.com
Node degree
Node degree란 특정 노드 $i$ 와 인접한 노드의 수를 나타내는 척도로 $k_i$ 로 나타냅니다. 예를 들어, 아래와 같은 무향 그래프가 있을 때 붉은 색으로 표시된 노드의 Node degree는 $k_{\text{red}} = 4$ 입니다.
이미지 출처 : laptrinhx.com
이로부터 그래프 전체에서의 평균 Node degree, $\bar{k}$ 도 구할 수 있습니다. 엣지의 개수가 $E$ 이고 노드의 개수가 $N$ 일 때, 평균 Node degree는 아래 식을 사용하여 구할 수 있습니다.
[\bar{k} = \frac{1}{N} \sum_{i=1}^N k_i = \frac{2E}{N}]
유향 그래프(Directed graph)에서는 엣지 방향에 따라 in-degree, $k^{\text{in}}$ 와 out-degree, $k^{\text{out}}$ 를 따로 정의할 수 있습니다. 해당 노드로 들어오는 엣지의 개수를 in-degree 라고 하며, 해당 노드로부터 나가는 엣지의 개수를 out-degree 라고 합니다. 아래와 같은 유향 그래프가 있다고 해보겠습니다.
위 그림에서 붉은 색으로 표시된 $C$ 노드의 in-degree, $k_{\text{red}}^{\text{in}}=0$ 이고 out-degree $k_{\text{red}}^{\text{out}}=4$ 입니다. $C, D$ 처럼 $k^{\text{in}}=0$ 인 노드를 Source 라고 하고 $A,B,E$ 처럼 $k^{\text{out}}=0$ 인 노드를 Sink 라고 합니다. 유향 그래프에서의 Node degree는 다음과 같은 식을 만족합니다.
[k_c = k^{\text{in}} + k^{\text{out}}
\bar{k}^{\text{in}} = \bar{k}^{\text{out}} = \frac{E}{N}]
Bipartite Graph
이번에는 특이한 형태의 그래프인 이분 그래프(Bipartite graph)에 대해서 알아보도록 하겠습니다. 이분 그래프의 노드는 겹치지 않는 2개의 집합 $U, V$ 로 나눌 수 있습니다. 엣지는 $U$ 와 $V$ 사이만을 연결합니다. 즉, $U$ 에 속하는 노드 사이, $V$ 에 속하는 노드 사이에는 엣지 연결이 없습니다. 그림으로 나타내면 다음과 같습니다.
이미지 출처 : wikipedia.org
이분 그래프로 표현할 수 있는 관계는 논문 저자-논문, 출연배우-영화 등이 있습니다. 이분 그래프를 알아야 하는 이유는 이분 그래프로부터 $U,V$ 에 속하는 노드의 관계를 사영(Projection)할 수 있기 때문입니다. 아래와 같이 파란색으로 나타낸 사용자(Users) 노드 집합과 빨간색을 나타낸 상품(Items) 노드 사이의 관계를 나타낸 이분 그래프가 있다고 해보겠습니다.
이미지 출처 : slideshare.net
사용자-상품 이분 그래프로부터 유저 간의 관계, 상품 간의 관계를 나타낸 그래프를 사영할 수 있습니다. 예를 들어, 유저 $A, B$ 는 3개의 상품을 공유하고 있으므로 3의 관계를 나타내는 노드로 연결합니다. 유저 $B, D$ 는 1개의 상품을 공유하고 있으므로 1의 관계를 나타내는 노드로 연결하며 유저 $A, D$ 는 아무런 상품도 공유하고 있지 않으므로 연결되지 않습니다. 상품 간의 관계를 나타낸 사영 그래프 역시 해당 상품이 몇 명의 유저를 공유하는 지를 바탕으로 서로의 관계를 나타냅니다.
Adjacency Matrix
이제는 위와 같이 나타나는 그래프를 컴퓨터가 이해할 수 있는 숫자로 표현해 줄 차례입니다. 그래프의 표현은 인접 행렬(Adjacency matrix)을 사용합니다. 가장 간단한 표현 방법은 연결 유무에 따른 이진 행렬(Binary matrix)입니다. 두 노드가 연결되어 있으면 1로, 그렇지 않으면 0으로 표현하는 방법이지요. 무향 그래프를 인접 행렬로 나타내면 아래와 같습니다.
이미지 출처 : thecrazyprogrammer.com
무향 그래프는 이어진 노드의 관계가 서로 동일하므로 인접 행렬 $A$ 의 대칭 성분이 동일합니다. 그렇기 때문에 무향 그래프를 나타낸 인접 행렬은 대칭 행렬(Symmetric matrix)이라는 특징이 있습니다. 그렇다면 유향 그래프는 인접 행렬로 어떻게 나타낼 수 있을까요? 유향 그래프를 나타낸 인접 행렬은 다음과 같습니다.
이미지 출처 : thecrazyprogrammer.com
유향 그래프를 나타낸 인접 행렬의 요소는 $i$ 번째 행의 노드가 $j$ 행의 노드를 가리킬 때에만 1의 값을 갖습니다. 예를 들어, 노드 2는 노드 1을 가리키기 때문에 $A_{21} = 1$ 로 나타냅니다. 하지만 노드 1은 노드 2를 가리키지 않기 때문에 $A_{12} = 0$ 으로 나타냅니다. 그렇기 때문에 유향 그래프를 나타낸 인접 행렬은 대부분 비대칭(Asymmetric)입니다.
현실 세상에 있는 네트워크를 나타낸 인접 행렬은 매우 희소합니다. 아래는 실제 네트워크에서의 노드 개수 $N$ 와 엣지 개수 $L$ , 평균 Node degree를 나타낸 표입니다.
인접 행렬에서 1의 비율은 $E/N^2$ 로 나타낼 수 있습니다. 위에 나온 대부분의 네트워크가 $10^{-4}$ 이하의 값을 가지므로 매우 희소한 인접 행렬로 나타난다는 것을 알 수 있습니다.
Attributes
각 노드와 엣지에는 여러 속성이 추가될 수 있습니다. 속성의 종류에는 다음과 같은 것들이 있습니다.
- 가중치(Weight) : 객체 간 의사소통을 나타낸 네트워크에서 네트워크의 빈도를 가중치로 표현할 수 있습니다.
- 순위(Ranking) : 객체 간 관계에 순위가 있을 경우 순위 속성을 사용하여 나타낼 수 있습니다.
- 유형(Type) : 객체 간 관계의 유형이 다를 경우 이를 속성으로 추가하여 표현할 수 있습니다.
- 부호(Sign) : 우호 관계, 적대적 관계와 같이 완전히 반대의 관계를 가질 경우 부호 속성을 추가하여 Positive/Negative 관계를 표현할 수 있습니다.
More Types of Graph
더욱 다양한 유형의 그래프에 대해서 알아보겠습니다. 첫 번째는 속성이 추가된 그래프입니다. 이 경우 인접 행렬은 $0,1$ 외에 다른 값을 가지게 됩니다. 가중치 속성이 추가된 행렬을 인접 행렬로 나타낸 그래프는 다음과 같습니다.
이미지 출처 : thecrazyprogrammer.com
Self-loops 가 추가된 형태의 그래프도 있습니다. Self-loops 가 없는 경우 인접 행렬의 대각(Diagonal) 성분은 항상 0이 되지만, 있을 경우에는 대각 성분 $A_{ii} \neq 0$ 이 됩니다.
이미지 출처 : quora.com
위 그래프에서 노드 1에 자기 자신을 가리키는 엣지가 하나있기 때문에 $A_{11} = 1$ 의 값을 갖습니다.
마지막으로 1개 이상의 노드로 연결된 다중 그래프(Multigraph)가 있습니다. 다중 그래프의 인접 행렬은 가중치 속성이 추가된 그래프와 같이 1이상의 값을 갖습니다.
이미지 출처 : math.stackexchange.com
Connectivity
그래프의 표현을 위해 마지막으로 알아볼 것은 연결성(Connectivity)입니다. 어떤 두 노드를 선택하더라도 둘을 연결하는 경로를 찾을 수 있을 경우 이 그래프를 연결된 그래프(Connected graph)라고 합니다. 위에서 예시로 살펴본 모든 그래프는 연결된 그래프입니다. 아래는 연결된 그래프와 연결되지 않은 그래프(Disconnected grpah)를 나타낸 이미지입니다.
이미지 출처 : algorithms.tutorialhorizon.com
유향 그래프에서 특정한 연결을 가진 노드 관계를 강한 연결(Strong connectivity)로 나타낼 수 있습니다. 아래와 같이 어떤 두 노드 $A, B$ 를 선택하더라도 두 노드 사이의 경로 $A \rightarrow B, B \rightarrow A$ 가 모두 정의될 경우 강하게 연결된 그래프(Strongly connected graph)라고 합니다.
이미지 출처 : geeksforgeeks.org
예를 들어, 위 그래프에서 노드 1과 노드 3 사이의 경로는 $1 \rightarrow 3 \quad (=1\rightarrow2\rightarrow3)$ 과 $3 \rightarrow 1 \quad (=3\rightarrow0\rightarrow1)$ 이 모두 정의됩니다. 위 그래프의 어떤 두 노드를 선택하더라도 서로 간 경로가 정의되므로 강한 연결성(Strong connectivity)을 가진다고 할 수 있습니다.
범위를 좁혀 일반 그래프 내에서 강하게 연결된 부분(Strongly connected components, SCCs)을 정의할 수 있습니다. 일반 그래프에서 강한 연결을 가지는 노드 부분을 찾을 수 있는데 이를 SCC라고 합니다. 아래는 특정 그래프에서 SCC를 나타낸 이미지입니다.
이미지 출처 : programiz.com